








声明: 本文引用的网站仅用于演示,如侵删。
背景
这两天收到运营同事一个关于需要登录的网站的数据爬取需求,登录同时需要填入图片验证码。
经过多次尝试,结合百度OCR可以完成图片验证码的获取和识别,特此记录。
希望能帮助到需要的朋友们。
前期准备
-
部署好的可访问的可视化爬虫spiderflow,可参考笔者之前的文章。
-
百度云OCR申请,可自行注册。
- 个人认证可申请每月1000次的免费额度,企业认证每月2000次免费额度,测试足够了。
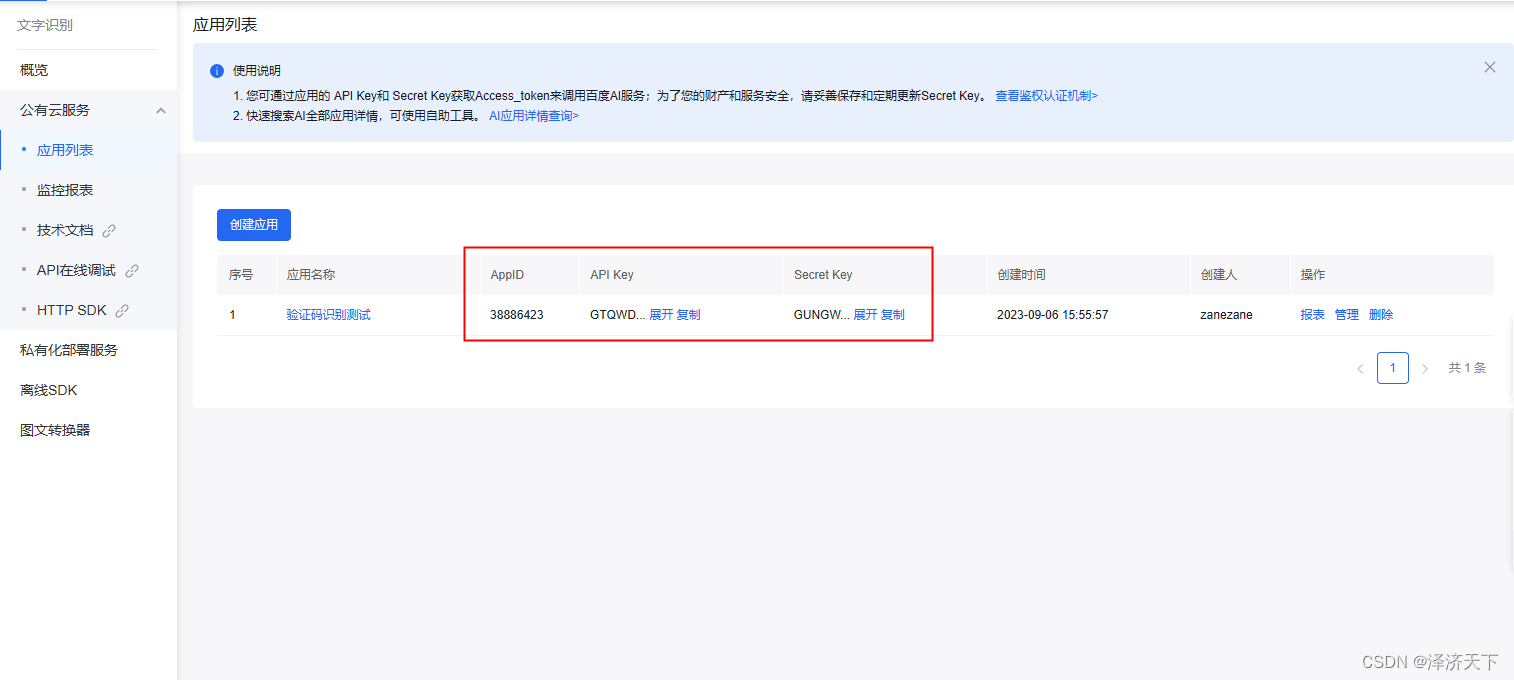
- 认证完成后注册应用,选择支持OCR图片识别。
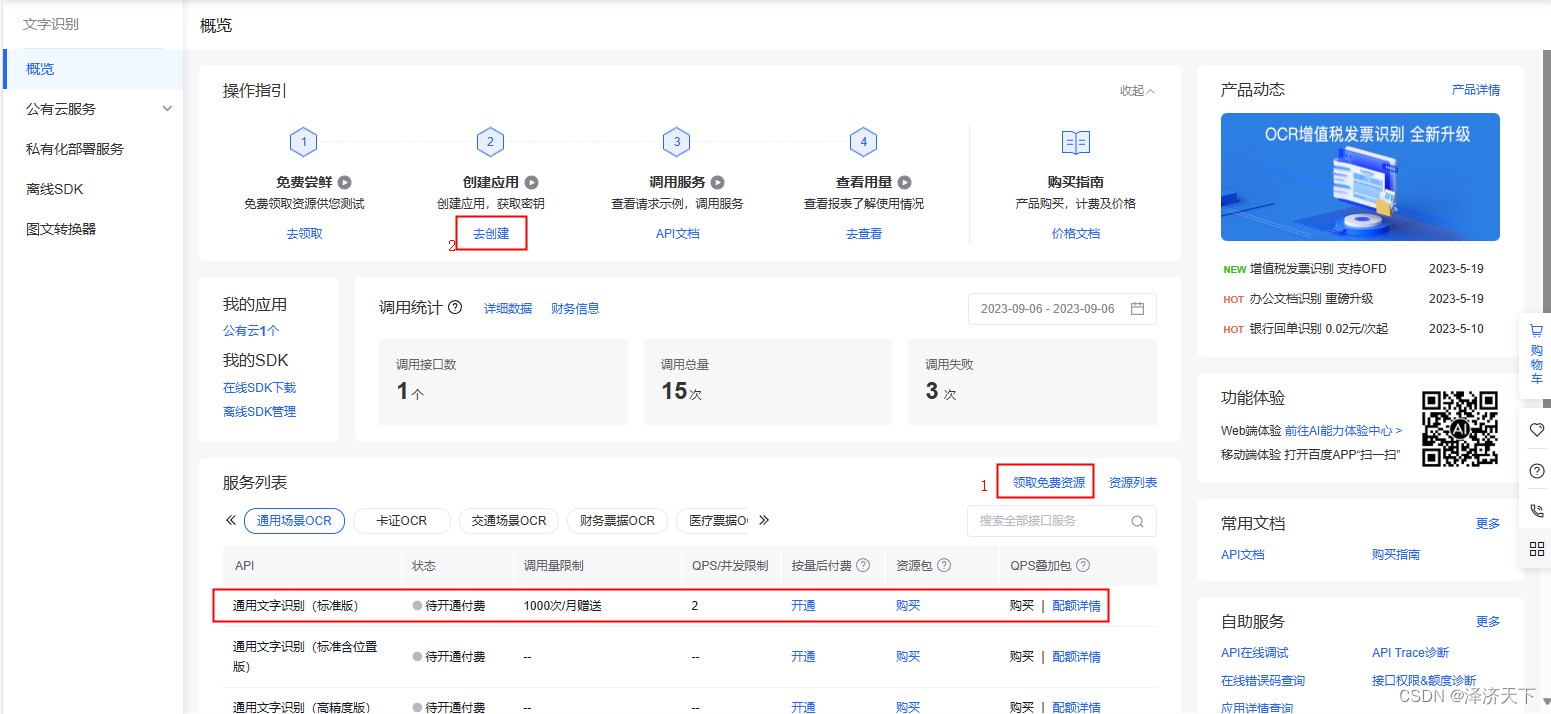
-
一个有图片验证码的目标网站
说明:
图片验证码的数据及展现形式有多种,如后端直接返回文件流,返回base64,前端自行渲染等,
本文仅讨论后端返回文件流和base64的两种情况。
开始
1. spiderflow集成ocr
这一步有现成的插件可以用,在gitee 上搜索spider-flow-ocr即可。
附地址参考: spider-flow OCR插件
用法也比较简单,在spider-flow-web的pom文件中添加如下依赖即可
<dependency>
<groupId>org.spiderflow</groupId>
<artifactId>spider-flow-ocr</artifactId>
<version>${spider-flow.version}</version>
</dependency>
添加完成后重新运行spiderflow项目,访问首页可看到如下页面:
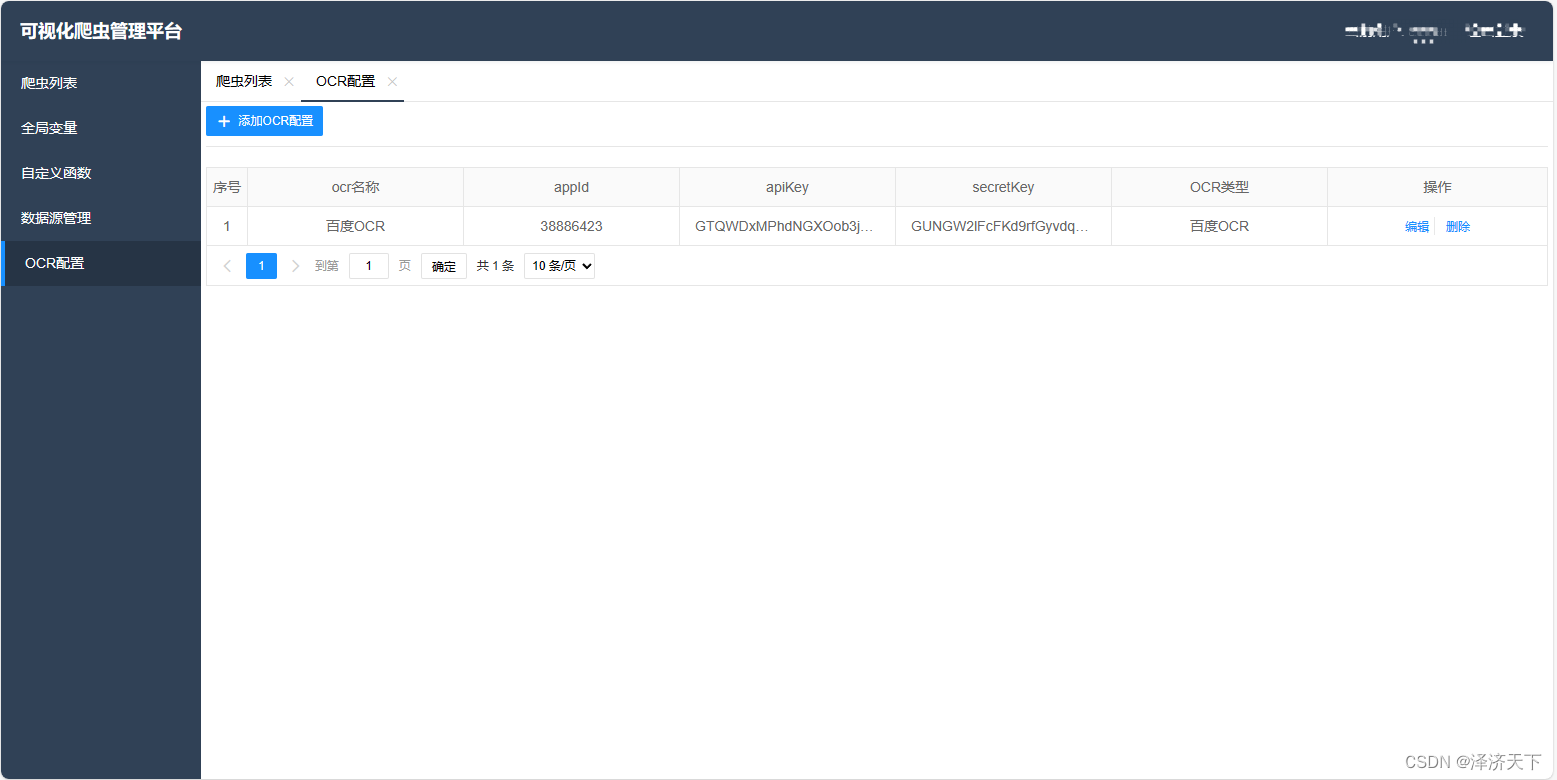
点击添加OCR配置,进入配置页面,填入百度云创建的应用对应的参数。
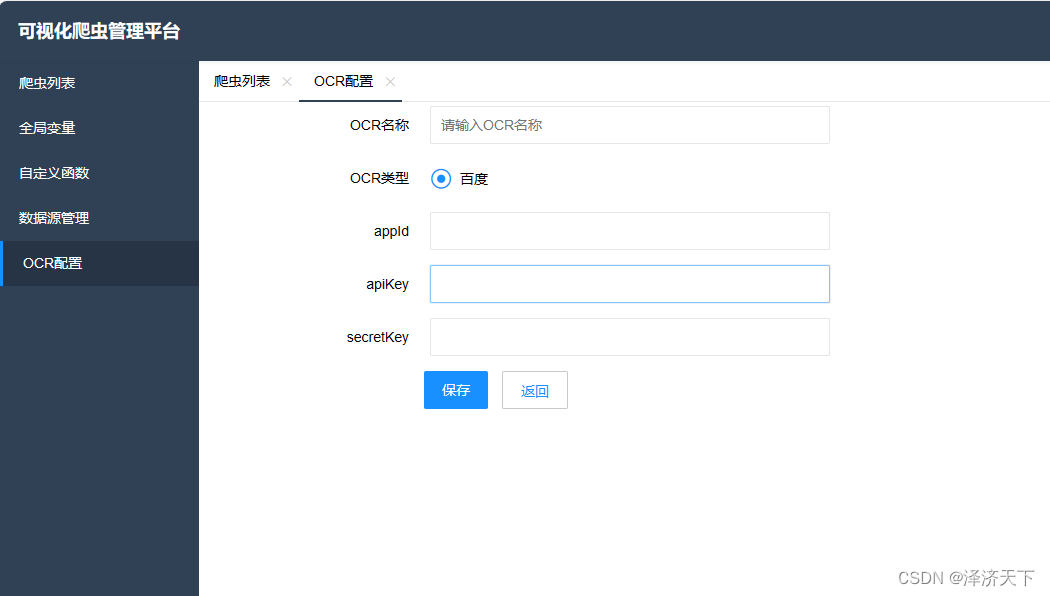
同时在爬虫列表页面点击添加爬虫,看到如下图标及配置即表示OCR集成成功。
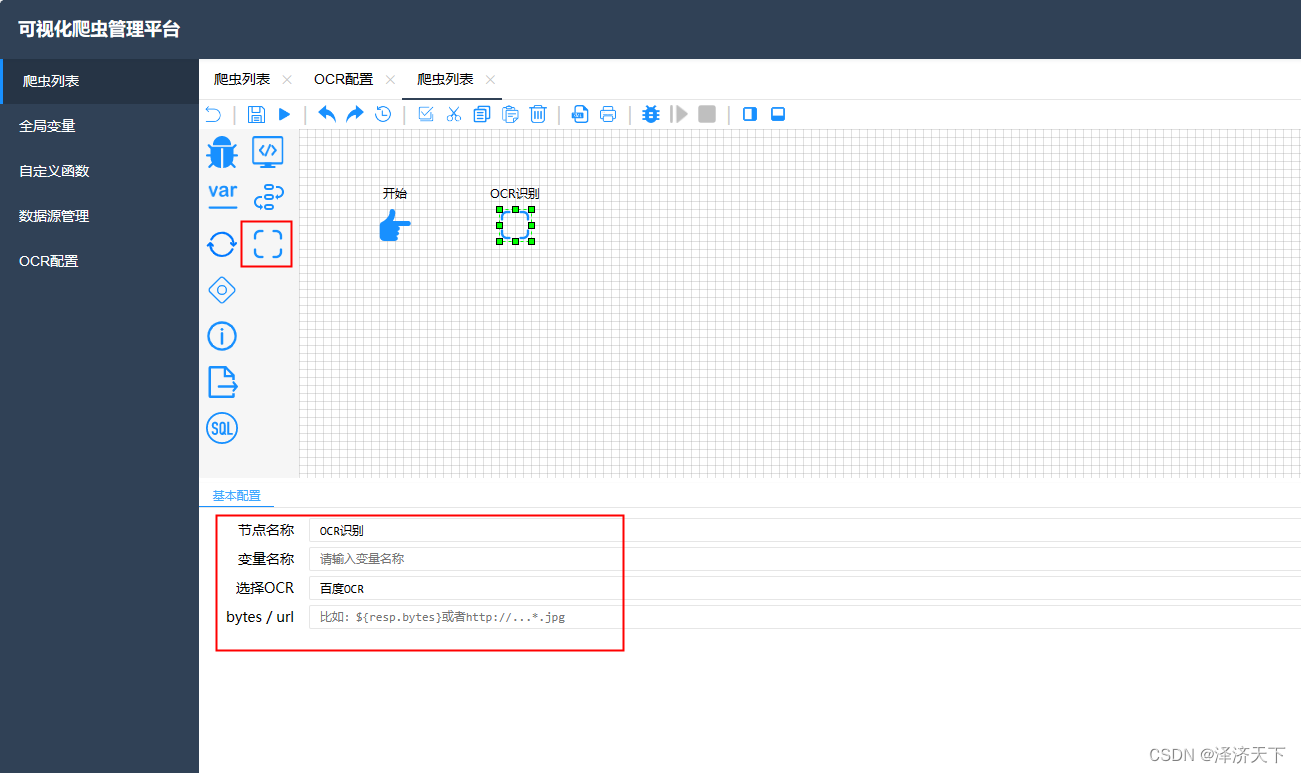
2. 获取验证码数据
首先找到获取验证码的链接,一般都可以在F12中找到对应请求,将请求记录下来,有的网站甚至需要添加指定的cookie或者请求头。
这里我使用的网站的验证码数据效果是这样的:
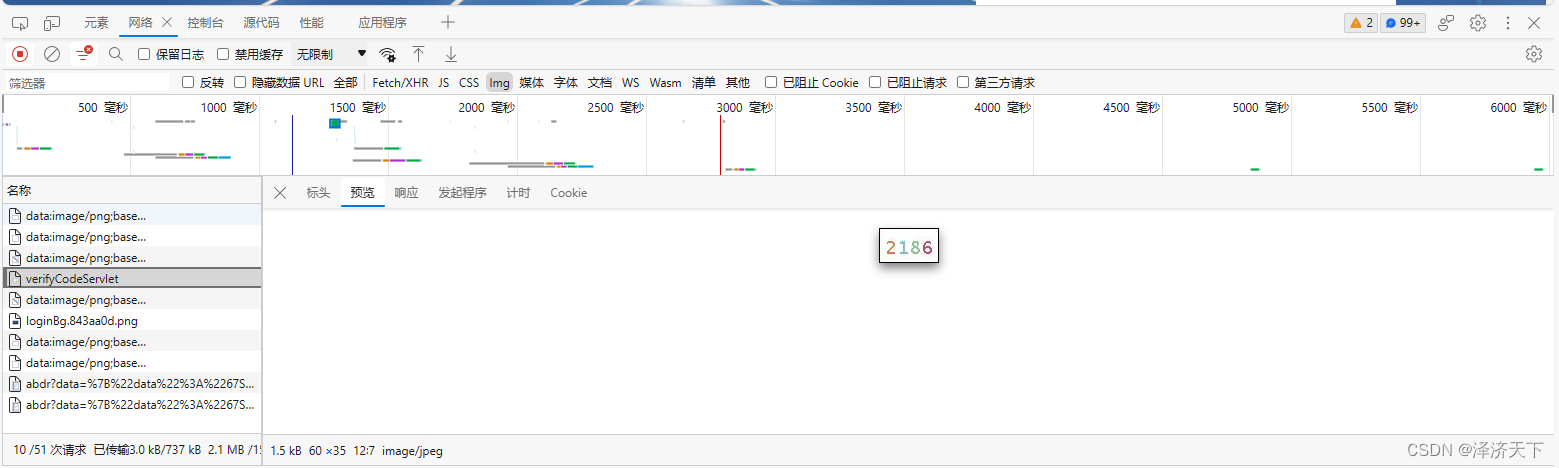
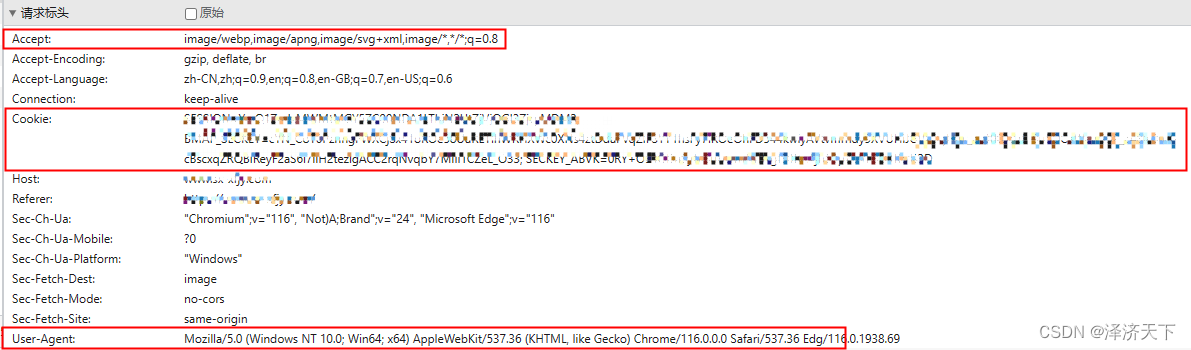
截图所示为关键请求头数据,除Cookie外其余属性需要添加到Header中。
PS: 如果上面的请求头不能正确返回数据,可尝试复制所有的请求头到spiderflow中。
3. 完成识别并查看结果
通过2的演示可以看到这里返回的直接就是一张图片,我们现在有两种思路:
- 保存图片到临时目录,再上传图片到OCR
- 直接提交byte到OCR
接下来就这两种思路分别做实现,同时也演示下spiderflow中文件和流的使用。
3.1 先保存到本地再上传
3.1.1 新建爬虫,并拖拽组件
如下图:
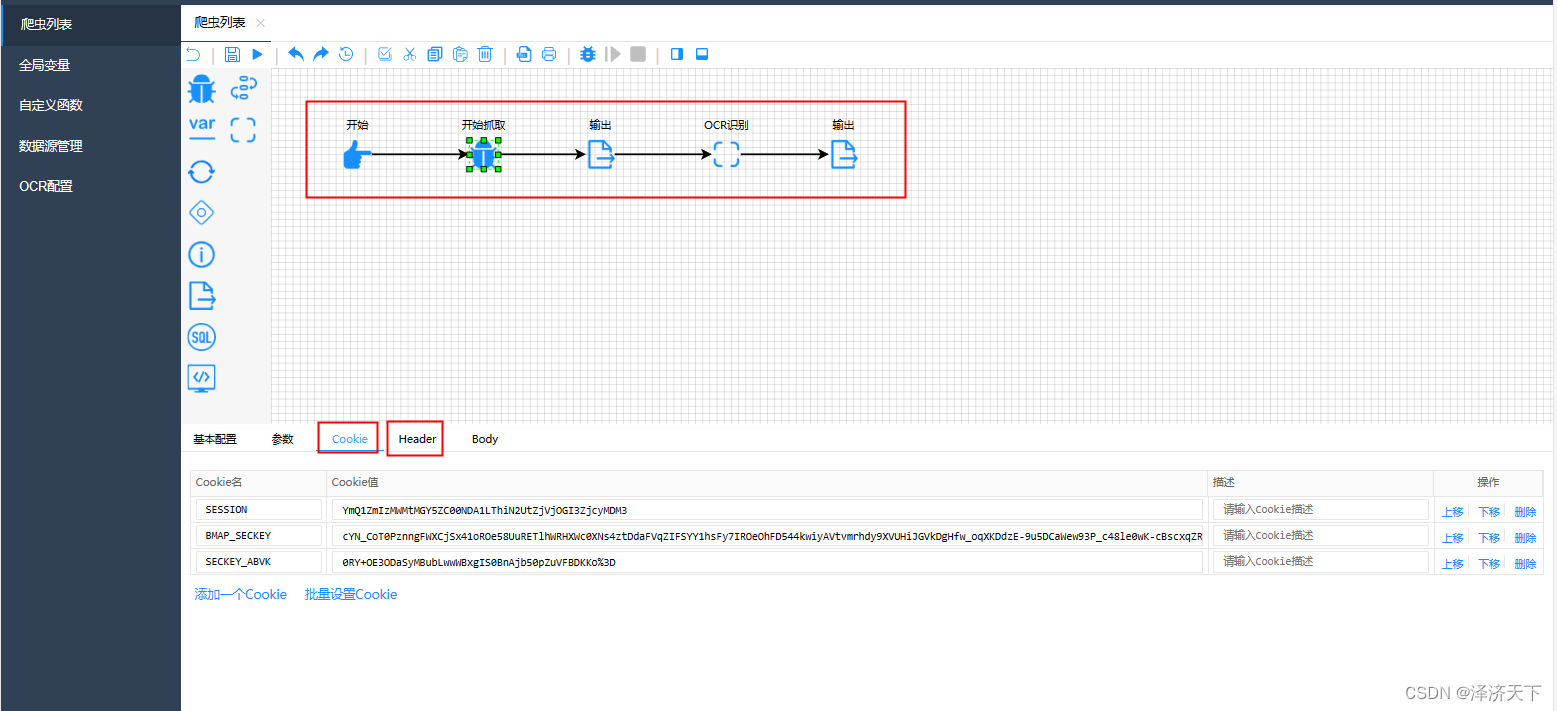
爬虫组件除配置URL外还需要加入对应的cookie和header,cookie和header均支持批量添加,还是挺方便的。
3.1.2 配置文件保存

用到了file.write方法,有三个参数,第一个是存储路径,第二个是个InputStream流,第三个是append参数,这里是false。
这样文件就存储到了/tmp/result.png中,后面运行后我们再验证。
3.1.3 配置OCR

3.1.4 输出结果
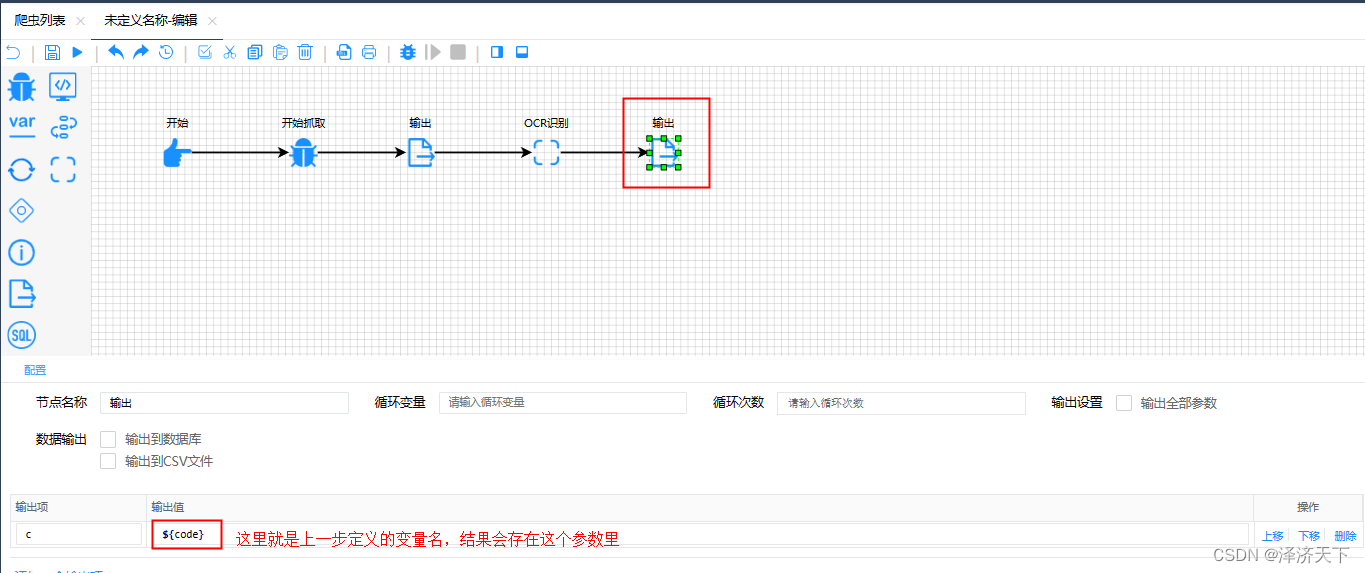
3.1.5 结果验证
保存并运行,查看/tmp/result.png文件是否存在,同时验证结果输出是否正确,效果如下:
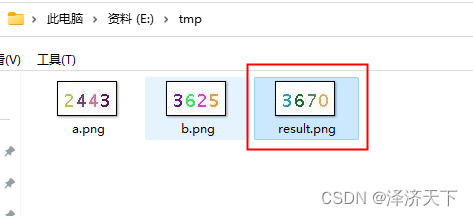
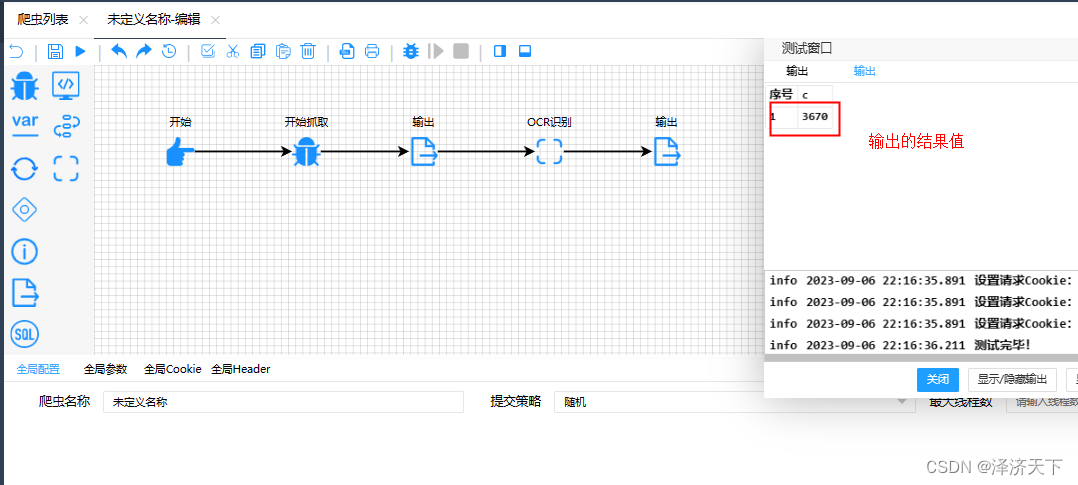
可以看到文件存在且文件对应的验证码和输出的验证码一致,实验结束。
总的来说,整个流程还是非常简单的,借助于spiderflow非常优秀的插件机制,ocr插件的出现使得ocr的使用非常方便,给作者点个大大的赞。
当然这个ocr插件只实现了百度OCR的集成,如果需要别的平台可参考添加实现即可。
3.2 直接上传并识别
上面我们实现了文件保存到本地再上传到ocr的过程,可以说是为了验证。接下来我们直接上传http响应到ocr来实现。
3.2.1 新建爬虫,拖拽组件如下图
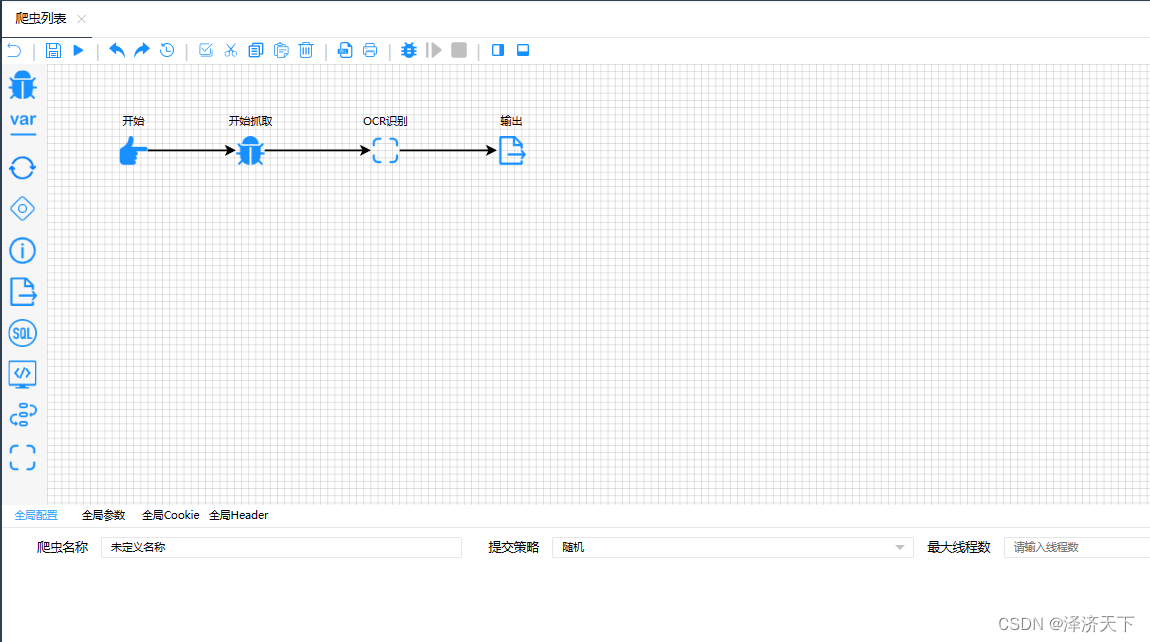
相比上个实现过程少了保存文件的过程,可想而知也就没有了读取文件的过程
3.2.2 爬虫配置
爬虫配置与3.1.1中配置一致,配置URL, header和cookie,不再赘述。
3.2.3 OCR配置
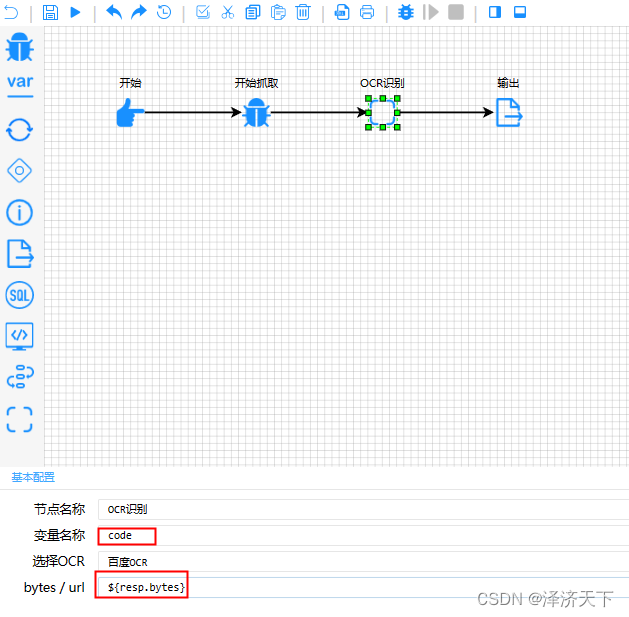
3.2.4 输出结果
配置同3.1.4,运行结果如下图:
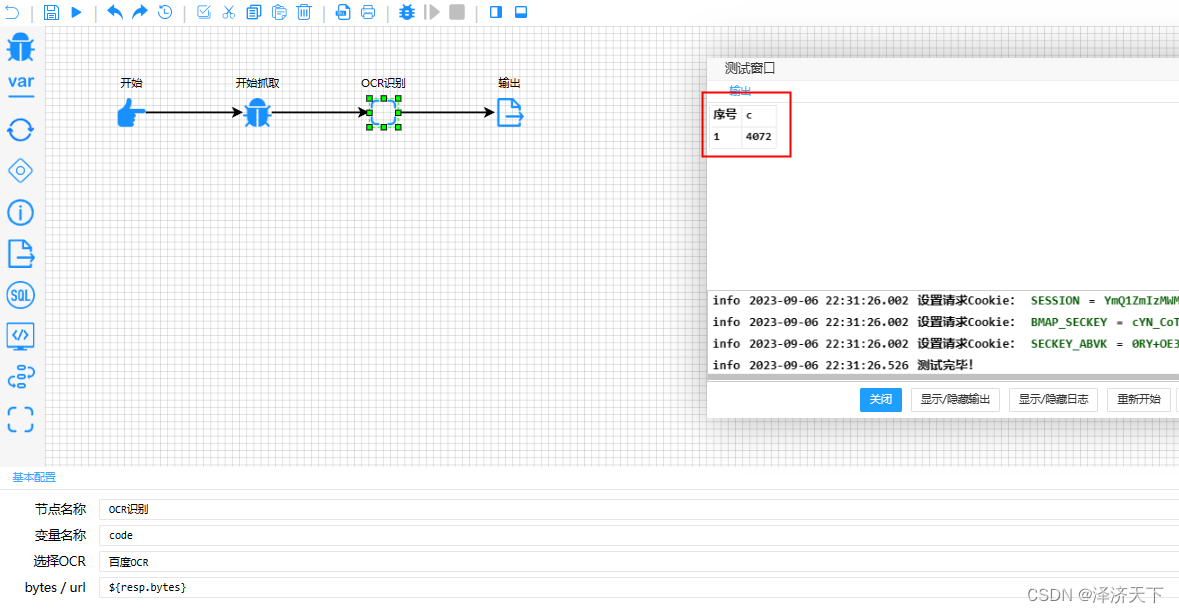
4. 获取base64对应的验证码
思路一: 解析base64为本地图片,再上传
关于解析base64为本地图片,原代码是有点问题的,简单调整下即可,涉及文件FileFunctionExecutor.java
需要添加和修改的方法如下:
/**
* 新添加的方法,兼容图片的base64编码
*/
private static byte[] toBytes(String content, String charset){
if(content.startsWith("data:")){
String data = content.substring(content.indexOf(",") + 1);
BASE64Decoder decoder = new BASE64Decoder();
try {
//Base64解码
byte[] b = decoder.decodeBuffer(data);
for (int i = 0; i < b.length; ++i) {
if (b[i] < 0) {
//调整异常数据
b[i] += 256;
}
}
return b;
}catch(Exception ex) {
ex.printStackTrace();
}
}
return StringFunctionExecutor.bytes(content, charset);
}
/**
* toBytes方法使用
* 修改原有方法
*/
@Comment("写出文件")
@Example("${file.write('e:/result.html',resp.html,'UTF-8',false)}")
public static void write(String path,String content,String charset,boolean append) throws IOException{
write(path,toBytes(content, charset),append);
}
关于字符串转byte数组,原文件中是直接调用StringFunctionExecutor.bytes(content, charset)来完成的,这种并不能兼容图片的base64,所以做了个简单的调整。
对应爬虫的流程图配置如下:
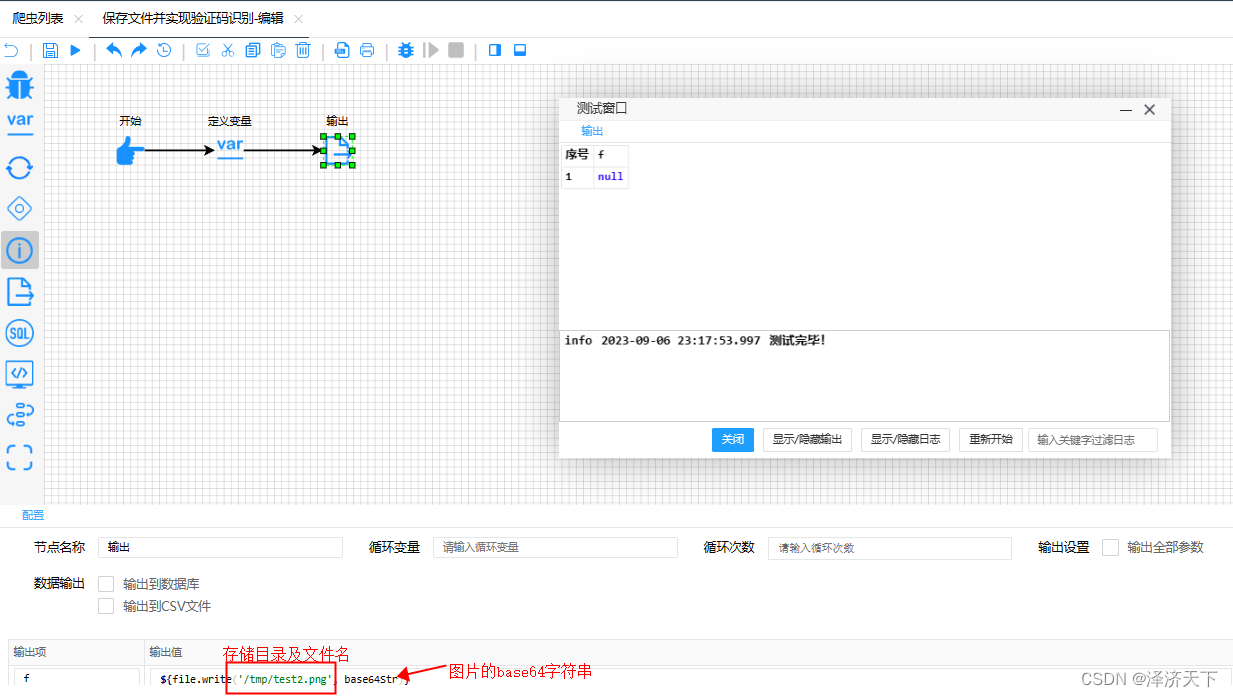
查看本地图片,如下:
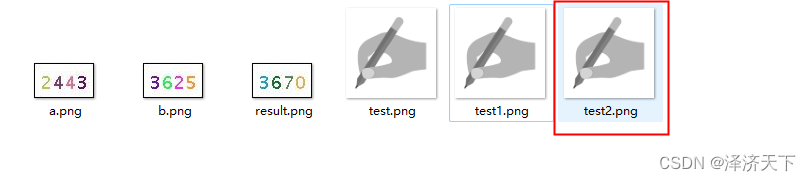
可以看到文件可以正常转换及存储, 接下来就可以上传这个文件到OCR实现识别了,步骤同3.1
这种方式不一定是最优解,确实能想到的最直接的办法(想到了另一种方式,暂且保留吧)
PS: 这里为了示例随便找了个图片通过在线转的base64,实际情况一般是通过接口获取。
思路二:获取到图片对应的base64字符串的byte数组
聪明的小伙伴一定都猜到了,这里要改写base64解码的相关代码了。
涉及到的类Base64FunctionExecutor.java, 具体实现留给各位小伙伴去探索吧。
补充@20231125:
有小伙伴问到思路二的实现方式,这里提供一种供参考。
- 在
Base64FunctionExecutot.java类中添加如下方法:
@Comment("根据stream进行base64加密")
@Example("${base64.streamToBytes(resp.stream)}")
public static byte[] streamToBytes(InputStream inputStream) throws Exception {
return IOUtils.toByteArray(inputStream);
}
- 修改流程图中ocr配置如下图:
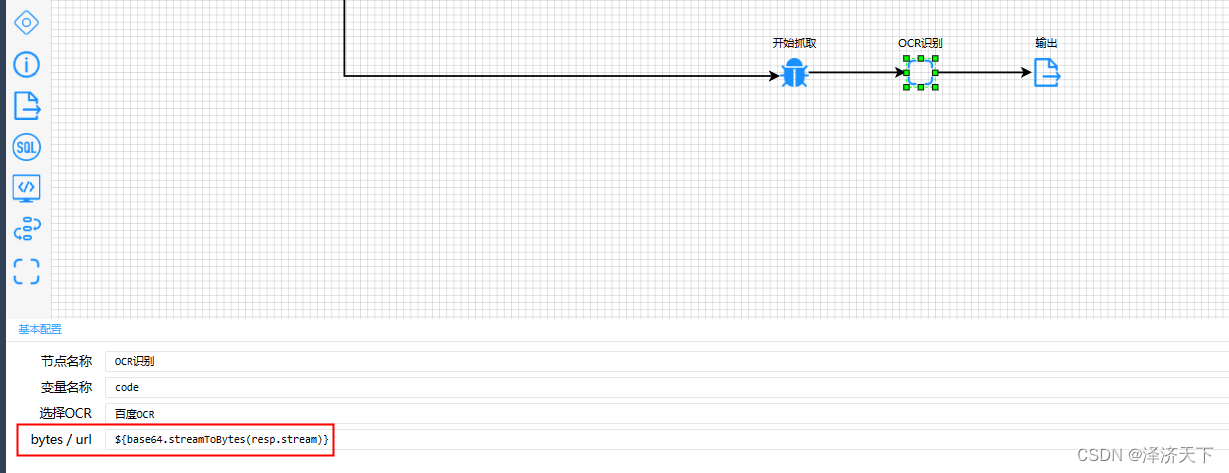
- 重启应用 运行流程即可,测试截图如下:
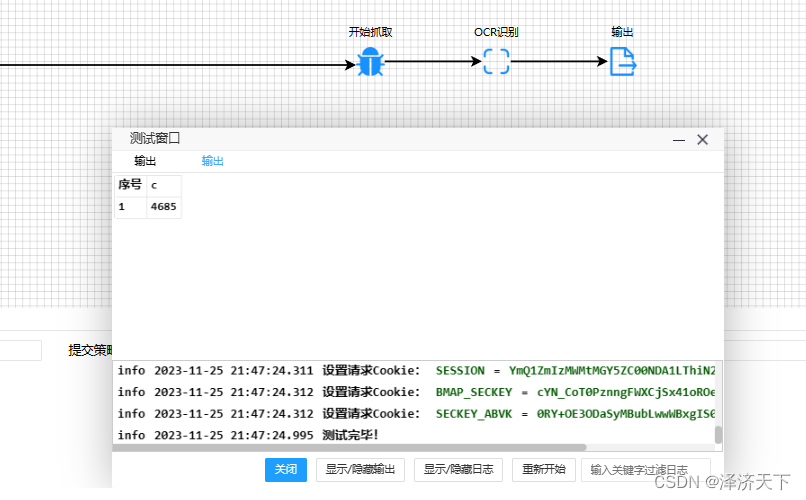
以上是通过inputstream实现的,也可以尝试其他方式,不再赘述。
思路三:各位小伙伴有更好的主意欢迎留言
到此本文要介绍的内容就结束了。
总结
本文介绍了基于spiderflow+ocr插件实现的图片验证码的获取与识别,整体过程相对来说比较简单,希望能对大家有所帮助吧。
spiderflow提供了非常优秀的插件机制,具备很高的扩展性,值得我们学习和研究,同时提供了很多很实用的方法。
实现了验证码的获取和识别,离实现登录又近了一步,为难的是网站提交的密码数据是加密后的,即使知道了用户名密码也要找到正确的加密算法才行,需要用到js逆向,还是得继续努力呀~~~~
如果本文对你有所帮助,欢迎一键三连~~~
针对以上内容或者spiderflow有任何疑问欢迎留言交流~~~~

















 810
810











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











