







案例说明
一家跨国旅游企业想对公司近8年历史消费客户做一个分析,了解客户的特征,从而针对不同客户的特征做出相应的营销策略,最大化投入产出比。通过识别高价值、高潜力的客户,实行差异化的客户管理策略,优化客户体验。为实现这一目标,通过客户分群技术,将具有相似特性的客户聚到相同类中,为每个不同特点的客户群体提供具有针对性、个性化的营销和管理活动。

建模分析思路:
1.对于有相关性的变量进行降维,减少变量数目;将变量进行分组,使得同一组的变量能尽量解释业务的一个方面。
2.由于k-means仅用于连续型变量聚类,因此需要对变量进行预处理。对于有序分类变量,如果分类水平较多可以按照连续变量处理,否则按无序分类处理,再进入模型;无序分类变量数目较少时,可以使用其哑变量编码进入模型。
3.在离散变量不多的情况下,可以做哑变量变换后进入模型。
数据预处理
1.填补缺失值
fill_cols = ['interested_travel','computer_owner','HH_adults_num']
fill_values = {col:travel[col].mode()[0] for col in fill_cols}
travel = travel.fillna(fill_values)
利用众数进行填补
2.修正错误值
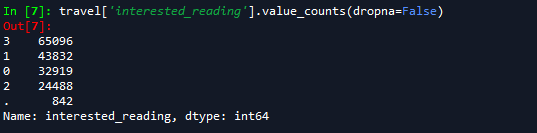
在该数据集中,HH_has_children的分类水平以字符形式表示,需要转换为整型,同时其中的缺失值应当表示没有小孩,因此替换为0;阅读爱好中包含错误信息“.”,将其以0进行替换。
travel['interested_reading'].value_counts(dropna=False)
travel['HH_has_children']=travel['HH_has_children'].replace({'N':0,'Y':1,np.NaN:0})
travel['interested_reading']=travel['interested_reading'].replace({'.':'0'}).astype('int')
3.对离散变量进行处理
_cols=['interested_travel',
'computer_owner',
'marital',
'interested_golf',
'interested_gambling',
'HH_has_children',
'interested_reading']
sample = travel[_cols].sample(3000,random_state=12345)
from itertools import combinations
from scipy import stats
for colA,colB in combinations(_cols,2):
crosstab = pd.crosstab(sample[colA],sample[colB])
pval = stats.chi2_contingency(crosstab)[1]
if pval >0.05:
print('p-value = %0.3f between "%s" and "%s" '%(pval,colA,colB))

这些有相关关系的离散变量大部分都在表述“用户爱好”这一维度,通过变换,将这些变量整合为一个连续变量。可以将旅行、电脑、高尔夫、博彩、阅读这几个分类变量综合成一个“爱好广度”指标,代表了用户休闲娱乐爱好;而连续型的interesrted_spor
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 427
427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









