






 本文档详细解答了Caffe深度学习框架在图像处理与训练过程中的常见问题,包括图像尺寸标准化、均值文件生成、内存溢出等问题,并提供了具体的解决办法。
本文档详细解答了Caffe深度学习框架在图像处理与训练过程中的常见问题,包括图像尺寸标准化、均值文件生成、内存溢出等问题,并提供了具体的解决办法。
1、均值计算是否需要统一图像的尺寸?
在图像计算均值时,应该先统一图像的尺寸,否则会报出错误的。
粘贴一部分官方语言:
均值削减是数据预处理中常见的处理方式,按照之前在学习ufldl教程PCA的一章时,对于图像介绍了两种:第一种常用的方式叫做dimension_mean(个人命名),是依据输入数据的维度,每个维度内进行削减,这个也是常见的做法;第二种叫做per_image_mean,ufldl教程上说,在natural images上训练网络时;给每个像素(这里只每个dimension)计算一个独立的均值和方差是make little sense的;这是因为图像本身具有统计不变性,即在图像的一部分的统计特性和另一部分相同。作者最后建议,如果你训练你的算法在非natural images(如mnist,或者在白背景存在单个独立的物体),其他类型的规则化是值得考虑的。但是当在natural images上训练时,per_image_mean是一个合理的默认选择。
这段话意在告诉我们在训练的图像不同,我们均值采用的方法亦可发生变化。
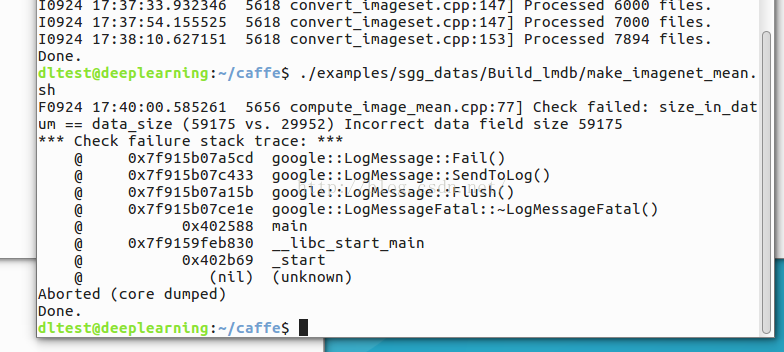
上图中很明显爆出了“size_in_datum == data_size ” 的错误。
下面是小编找到的问题原因:
在把图片转化到levelDB中遇到了Check failed: data.size() == data_size,归根究底还是源码没细看,找到出错的行在F0714 20:31:14.899121 26565 convert_imageset.cpp:84] convert_imageset.cpp中的第84行, CHECK_EQ(data.size(), data_size) << "Incorrect data field size " << data.size();就是说两个大小不一致,再看代码
int data_size;
bool data_size_initialized = false;
for (int line_id = 0; line_id < lines.size(); ++line_id) {
if (!ReadImageToDatum(root_folder + lines[line_id].first,lines[line_id].second, datum)) {
continue;
}
if (!data_size_initialized) {
data_size = datum.channels() * datum.height() * datum.width();
data_size_initialized = true;
} else {
const string& data = datum.data();
CHECK_EQ(data.size(), data_size) << "Incorrect data field size "
<< data.size();
}从上面的代码可知,第一次循环中,data_size_initialized=false,然后进入到if (!data_size_initialized) 中,把data_size设为了datum.channels() * datum.height() * datum.width(),同时把data_size_initialized=true,在以后的迭代中,都是执行else语句,从而加入图片大小不一致会报错,处理的办法可选的是,在转换到数据库levelDB前,让图片resize到一样的大小,或者把ReadImageToDatum改成ReadImageToDatum(root_folder + lines[line_id].first,lines[line_id].second,width,height ,datum)。
参考博文地址:http://blog.csdn.net/alan317/article/details/37772457
2、caffe实际运行中图像大小不一,放大缩小时都有可能失真,此时该如何处理数据?
如果处理的图像大小不一且过度放大或者过度缩小会造成图像严重失真且丢失信息,则不能直接对图像尺寸进行归一化。
措施:
可以采用一个居中的尺寸,例如统一图像的宽度为600,而高度根据宽度的大小按照比例进行缩放。处理完之后可以对图像进行切片处理,进而将图像尺寸进行归一化。
3、Crop_size的作用?
4、在网络配置文件中的 test_iter 值得确定
# reduce the learning rate after 8 epochs (4000 iters) by a factor of 10
# The train/test net protocol buffer definition
net: "examples/cifar10/cifar10_quick_train_test.prototxt"
# test_iter specifies how many forward passes the test should carry out.
# In the case of MNIST, we have test batch size 100 and 100 test iterations,
# covering the full 10,000 testing images.
test_iter: 100
# Carry out testing every 500 training iterations.
test_interval: 100
# The base learning rate, momentum and the weight decay of the network.
base_lr: 0.001
momentum: 0.9
weight_decay: 0.004
# The learning rate policy
lr_policy: "fixed"
# Display every 100 iterations
display: 100
# The maximum number of iterations
max_iter: 4000
# snapshot intermediate results
snapshot: 4000
snapshot_format: HDF5
snapshot_prefix: "examples/cifar10/cifar10_quick"
# solver mode: CPU or GPU
solver_mode: CPU在设置配置时,对于test_iter值的计算有一点模糊,不知是根据batch size 值与整体图像库(测试集合与训练集合)还是单独的某个图像集合数据计算获得。后来通过认真读给出的解释与实例,最终确定该值是batch size 值与测试图像集合计算获得的。若batch size 值为100,而训练集合含有6000幅图片,测试集含有1000幅图片,则test_iter值为1000/10,与训练集的图片量无关。
5、如何判断一个模型已经训练好,可以正常使用?
6、能否将caffe从Linux下导出,形成一个独立包?
7、Cannot copy param 0 weights from layer 'conv1'; shape mismatch.
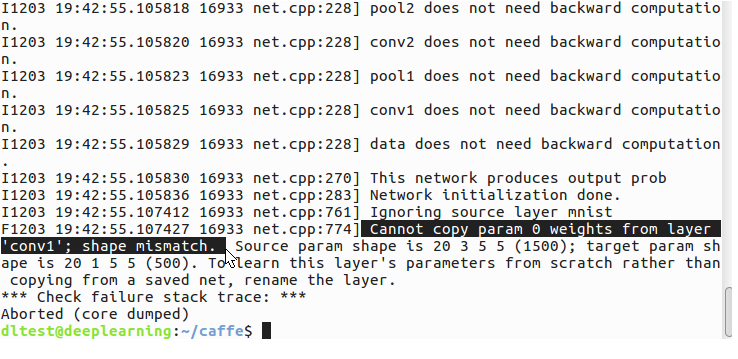
相关网页:http://stackoverflow.com/questions/37300317/caffe-error-cannot-copy-param-0-weights-from-layer-shape-mismatch
http://blog.csdn.net/ddqqfree123/article/details/52389337
http://blog.csdn.net/preston2006/article/details/53421889
网络上给出的解决方法:
|
|
Share the prototxt file that you used to train and test to pinpoint the issue. It should be mainly because the dimensions of the input image is not the same in both the test prototxt and train prototxt. Check the height, width and channel count of both the test and train prototxt
|
实际解决方法与解析:
“conv1” ; shape mismatch 已经很明确的给出了错误的原因,原始shape不一致,同时又很明确的指出了是cov1层出现的错误。所以直接找shape\cpnv1,之后才发现是训练模型文件与模型定义文件中的shape不相符,我训练时图像库中有的图像是一个通道,有的是使用的3个通道,所以默认使用三个通道,而我的模型定义文件中的shape,其通道数写的是1个通道,故出现错误。
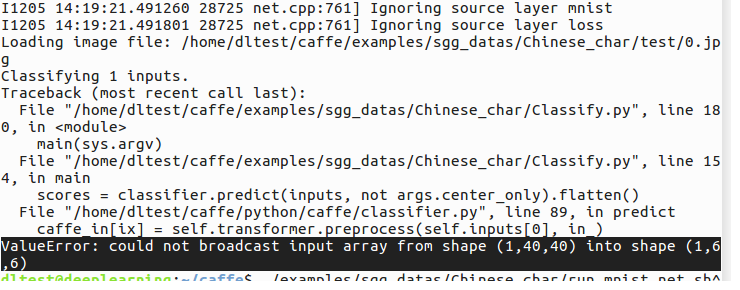
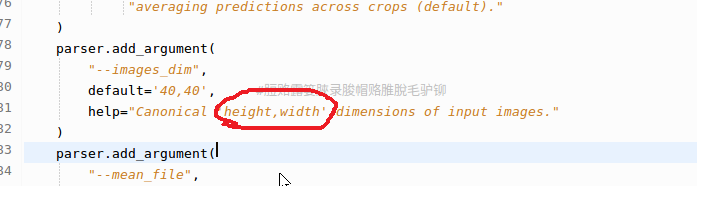
8、ValueError: could not broadcast input array from shape (1,40,40) into shape (1,6,6)
9、caffe 提示 build/examples/mnist/convert_mnist_data.bin: error while loading shared libraries: libprotobuf.so.8: cannot open shared object file: No such file or directory

解决方法:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/dell/local_install/lib如图所示:

10、在生成lmdb过程中提示:Check failed:mkdir( source.c_str() , 0744 ) == 0 ( -1 vs. 0 ) mkdir /home/dell/multiple_caffe/sgg_projects/codes/train_label_lmdb failed

从上述提示错误中很明显是 train_label_lmdb 出现错误。 所以从这点开始寻找突破点。最终找到的问题所在:在生成 lmdb 过程中,需要先删除原有的lmdb 文件,否则就会出现这种错误。在生成之前添加:
rm -rf $EXAMPLE/train_label_lmdb
11、生成均值文件时提示错误: Check failed: mdb_status == 0 (2 vs. 0) No such file or directory
小编出现这个错误是由于生成均值的文件中变量没有赋值正确,所以如果出现这个问题,现确定你的生成均值文件中的变量值都是正确的。
12、小编近期在使用caffe进行训练时,常出现 Check failed: error == cudaSuccess (2 vs. 0) out of memory 错误。
从错误提示可以看出是内存不够了。所以小编就加了一个8G 内存条(刚好手边有),可是加上了并没有多大的作用啊,还是照样报错。后来才找到解决方法。
解决方法:
batch_size太大了,一次性读入的图片太多了,所以就超出了显存。因此需要将train.prototxt中的文件train和test的batch_size调小一点。
参考博文:http://blog.csdn.net/qq_29596177/article/details/56692295

















 1079
1079


 到【灌水乐园】发言
到【灌水乐园】发言








