







什么是哈希表
哈希表(Hash table,也叫散列表),是一种将键( key)映射为值( value)从而实现快速查找的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数(也就哈希函数),存放记录的数组叫做散列表。
记录的存储位置=f(key)
这里的对应关系f称为散列函数,也称为哈希函数(hash function),采用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间称为散列表或哈希表(Hash table)。
哈希表hashtable(key, value) 就是把key通过一个固定的哈希函数转换成一个整型数字,然后将该数字对数组长度进行取余操作,取余结果就是数组的下标(也就是索引值),将value存储在以该数字为下标的数组空间里。
在简易实现中,散列表包含一个底层数组和一个散列函数(hash function)。插入一个值及其对应的键时,散列函数会将键映射为数组的一个索引。然后,这个值就会存储到数组中该索引对应的位置上。当然,这种简易实现方法是不够完善的,因为所有可能的键(key)必须转化为各不相同的散列值,否则一不小心就可能改写某些数据。因此,为了防止这类“碰撞冲突”,这个数组会变得非常大,以便放下所有可能的键。
哈希表和数组、链表一样,也是一种数据结构。
散列函数必须满足的要求:
- 一致性。每次输入相同的key,得到的value必须是相同的。
- 不同的输入(key)映射到不同的数字。例如, 如果一个散列函数不管输入是什么都返回1,它就不是好的散列函数。最理想的情况是,将不同的输入映射到不同的数字。
散列函数将输入(key)映射为数字作为数组的下标,定位到value所在的内存空间。如此,查找所需的时间复杂度为O(1),和数组的一样。
哈希表示例
假如,我有一个product数组,存放的是商品的价格:(eggs, 2.50), (milk, 2.00), (apple, 8.99), (pear, 5.99), (banana, 4.99)。
映射关系:eggs ==> 0, milk ==>1, apple ==>2, pear ==>3, banana ==>4
输入输出:product["eggs"] = 2.50, product["milk"] = 2.00, product["apple"] = 8.99, product["pear"] = 5.99, product["banana"] = 4.99
这里的key=商品名称,value=商品价格。
总结:在该示例中,我们使用散列函数和数组来创建哈希表。上面所说的映射关系就是哈希函数,很多优秀的编程语言都提供了对哈希函数的实现。如Python中的dict,Go语言中的map。下面我用Python语言来实现上面的例子。
>>> product = dict()
>>> product["eggs"] = 2.50
>>> product["milk"] = 2.00
>>> product["apple"] = 8.99
>>> product["pear"] = 5.99
>>> product["banana"] = 4.99
>>> print(product)
{'milk': 2.0, 'pear': 5.99, 'banana': 4.99, 'eggs': 2.5, 'apple': 8.99}哈希表的实现
我们先来说说数组和链表的特点
数组:查找容易,插入和删除困难。
链表:查找困难,插入和删除容易。
而哈希表兼具数组查找和链表插入和删除容易的优点。哈希表、数组、链表时间复杂度对比如下:

O(1)表示常量时间。
O(n)表示线性时间。
O(logn)表示对数时间。
O(1) < O(logn) < O(n)
【说明】在平均情况下,哈希表的查找(获取给定索引的元素)速度和数组一样快,而插入和删除速度和链表一样快,因此它兼具二者的优点。但在最糟糕的情况下,哈希表的各种操作的速度都很慢。因此,在构造哈希表时,避开最糟糕的情况至关重要。
哈希表的实现方法有多种,接下来介绍最常用的一种方法——拉链法。如图所示:
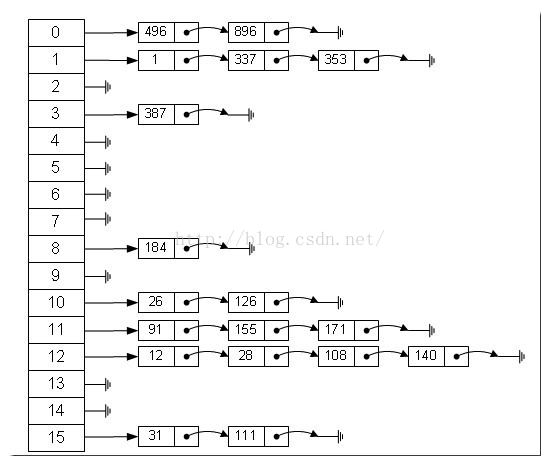
左边是一个数组,数组成员是指针变量,指向一个单链表的头结点。上面我们说到哈希函数总是将不同的键映射到数组不同的位置。实际上,几乎不可能编写出这样的哈希函数,这样不可避免就会产生冲突(collision),即存在有多个key通过映射关系得到的数组索引值都是相同的。解决办法就是在这个数组索引值位置存储一个链表。这是,查找key对应的value值,需要先找到正确的链表位置,再从链表中找出这个value的位置。
使用拉链法创建的哈希表,存在的一种极端情况,第一个位置的链表很长很长,散列表中所有的元素都存放在这个链表中,这与将所有元素存放在一个链表的情况一样糟糕:哈希表的查找速度会很慢。为了避免这样的情况发生,就需要设计出好的哈希函数,好的哈希函数很少会导致冲突。而最理想的情况是,哈希函数将key均匀地映射到哈希表的不同位置。
避免冲突
在构造哈希表的时候,可能会产生碰撞冲突(Collision)。为了避免冲突,需要有:
- 较低的填装因子
- 良好的哈希函数
装填因子
装填因子 = (散列表包含的元素个数) / (哈希表的长度)
装填因子反映了哈希表的装满程度。装填因子越小,则哈希表发生冲突的可能性就越小;反之,装填因子越大,表示哈希表中已填入的元素个数越多,再填记录时,发生冲突的可能性就越大。
当装填因子 > 1时,这意味着哈希表的元素个数 > 哈希表的长度,需要调整哈希表的长度,这个过程称为resizing。通常的做法是将哈希表的长度按2的倍数增加。通常而言,一旦装填因子大于0.7,就需要调整哈希表的长度。
良好的哈希函数
良好的哈希函数能够让元素在哈希表中均匀分布。而糟糕的哈希函数会让元素扎堆,导致大量冲突的发生。
哈希表的应用
- 将哈希表用于查找
使用哈希表用于查找,查找速度非常快,平均时间复杂度是O(1),即常量时间。给定一个key值,就能直接找到这个元素在哈希表中的位置,不需要像二分法那样,需要进行比较,逐步缩小范围的查找方式。
- 用于信息安全领域的加密算法
现在常见的加密算法SHA1 SHA256 SHA384 SHA512,通过哈希函数将一些不同长度的信息转化成杂乱的N位的编码,这些编码值叫做Hash值. 也可以说,Hash就是找到一种数据内容和数据存储地址之间的映射关系。
- 防止重复
使用哈希表来检查是否重复,速度非常快。防止重复,实际上也是一种查找,即查重。
- 将哈希表用作缓存
缓存是一种常见的加速方式,所有的大型网站都使用了缓存技术,而缓存的数据则存储在哈希表中的。将访问量很大的网页存储在哈希表中,当有用户访问的时候,就可以直接将保存在哈希表中的网页返回给用户,而不必每次都让服务器去生成网页。用户请求的URL是哈希表的key,对应的网页数据是value。















 1117
1117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









