







前言
正则表达式(Regular Expression,在代码中常简写为 regex、regexp、RE 或 re)是预先定义好的一个“规则字符串”,通过这个“规则字符串”可以匹配、查找、替换那些符合“规则”的文本,也就是说正则表达式针对的目标是文本字符串。
虽然文本的查找和替换功能可通过字符串提供的方法实现,但是实现起来极为困难,而且运算效率也很低。而使用正则表达式实现这些功能会比较简单,而且效率很高,唯一的困难之处在于编写合适的正则表达式。
Python中正则表达式应用非常广泛,如数据挖掘、数据分析、网络爬虫、输入有效性验证等。Python也提供了利用正则表达式实现文本的匹配、查找和替换等操作的 re 模块。本文介绍的Python中的正则表达式与其他编程语言的正则表达式是通用的。
一、正则表达式字符串
正则表达式是一种字符串,正则表达式字符串是有普通字符和元字符(Meta Characters)组成的。
1)普通字符
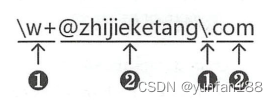
普通字符是按照字符字面意义表示的字符。下图1-1是验证域名为 zhijieketang.com 的邮箱的正则表达式,其中标号为②的字符(@zhijieketang 和 com)都属于普通字符,这里它们都表示字符本身字面意义。
2)元字符
元字符是预先定义好的一些特定字符,如上图1-1所示,其中标号为①的字符(\w+ 和 \.)都属于元字符。
1.1 元字符
元字符(Metacharacters)是用来描述其他字符的特殊字符,它由基本元字符和普通字符构成。其中基本元字符是构成元字符的组成要素。基本元字符主要有14个,具体如下图1-2所示。
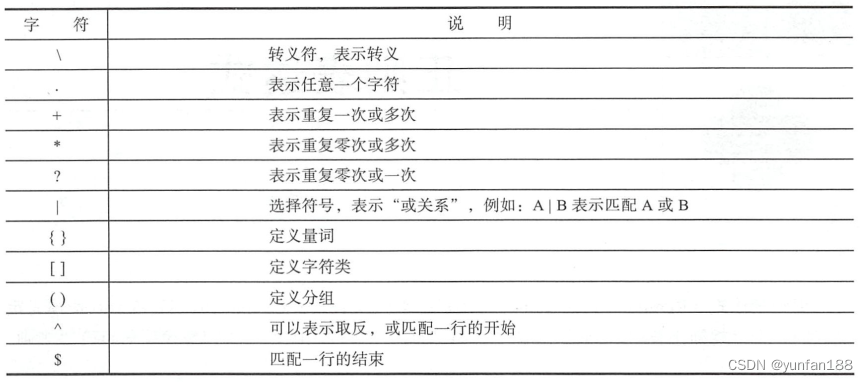
在上图1-1中,"\w+" 是元字符,它由两个基本元字符("\" 和 "+") 和一个普通字符 w 构成。另外,还有 "\." 元字符,它由两个基本元字符 "\" 和 "." 构成。
学习正则表达式某种意义上将就是在学习元字符的使用,元字符是正则表达式的重点也是难点。下面会分分门别类地介绍元字符的具体使用。
1.2 字符转义
在正则表达式中有时也需要字符转义,上图1-1中的 w 字符不表示英文字母 w,而是表示任何语言的单词字符(如英文单词、中文文字等)、数字和下划线等内容时,需要在 w 字母前加上反斜杠 “\”。“\” 反斜杠也是基本元字符,与Python中的字符转义是类似的。
不仅可以对普通字符进行转义,还可以对基本元字符进行转义。如上图1-1所示,其中点号 “.” 字符是希望按照点号的字面意义使用,作为 .com 域名的一部分,而不是作为点号基本元字符的意义使用,所以需要加反斜杠 “\” 进行转义,即 “\.” 才是表示点号“.” 的字面意义。
1.3 开始与结束字符
上图1-2中的基本元字符 ^ 和 $,它们可以用于匹配一行字符串的开始和结束。当以 ^ 开始时,要求一行字符串的开始位置匹配;当以 $ 结束时,要求一行字符串的结束位置匹配。所以正则表达式 \w+@zhijieketang\.com 和 ^\w+@zhijieketang\.com$ 是不同的。
示例代码如下:
# coding=utf-8
# 代码文件:regex_demo.py
# 正则表达式中开始(^)和结束($)元字符的使用
import re # --1
p1 = r'\w+@zhijieketang\.com' # --2 正则表达式
p2 = r'^\w+@zhijieketang\.com$' # --3 正则表达式
text = 'Tony`s email is tony_guan588@zhijieketang.com.'
m = re.search(p1, text) # --4
print(m) # 匹配成功
m = re.search(p2, text) # --5
print(m) # 不匹配
email = 'tony_guan588@zhijieketang.com'
m = re.search(p2, email) # --6
print(m) # 匹配成功运行结果如下:
> python regex_demo.py
<re.Match object; span=(16, 45), match='tony_guan588@zhijieketang.com'>
None
<re.Match object; span=(0, 29), match='tony_guan588@zhijieketang.com'>上述代码第1处是导入Python正则表达式模块 re。代码第2处和第3处定义了两个正则表达式。
代码第4处通过 re 模块的 search() 函数在字符串 text 中查找匹配 p1 正则表达式,如果找到第一个则返回 match 对象,如果没有找到则返回 None。注意 p1 正则表达式开始和结束没有 ^ 和 $ 符号,所以 re.search(p1, text) 会成功返回 match 对象,见输出结果。
代码第5处通过 search() 函数在字符串 text 中查找匹配 p2 正则表达式,由于 p2 正则表达式开始和结束有 ^ 和 $ 符号,匹配时要求 text 字符串开始和结束都要与正则表达式开始和结束匹配。\w 匹配的内容是:任何语言的单词字符(如英文单词、中文文字等)、数字和下划线等内容。其后的 + 的含义是:表示重复一次或多次。显然 text 字符串不满足 p2 正则表达式的匹配条件。
代码第6处中的 re.search(p2, email) 的 email 字符串开始和结束都能与 p2 正则表达式开始和结束匹配,所以会成功返回 match 对象。
注意:在正则表达式中本身包含很多反斜杠 “ \ ” 等特殊字符的字符串时,推荐使用Python中原始字符串表示正则表达式,否则需要对这些特殊字符进行转义,所以 p1 变量的的正则表达式也可以使用 '\\w+@zhijieketang\\.com' 普通字符串形式,不需要在前面加 r 前缀。
二、字符类
正则表达式可以使用字符类(Character Class),一个字符类定义一组字符,其中的任一字符出现在输入字符串中即匹配成功。注意每次匹配只能匹配字符类中的一个字符。
2.1 定义字符类
定义一个普通的字符类需要使用 " [ " 和 " ] " 元字符类。例如需在输入字符串中匹配Java 或 java,可以使用正则表达式 [Jj]ava。示例代码如下:
# coding=utf-8
# 代码文件:regex_demo2.py
# 正则表达式中定义字符类
import re
p = r'[Jj]ava'
# p = r'Java|java|JAVA'
m = re.search(p, 'I like Java and Python.')
print(m) # 匹配成功
m = re.search(p, 'I like JAVA and Python.') # --1
print(m) # 不匹配
m = re.search(p, 'I like java and Python.')
print(m) # 匹配成功运行结果如下:
> python regex_demo2.py
<re.Match object; span=(7, 11), match='Java'>
None
<re.Match object; span=(7, 11), match='java'>上述代码第1处中 JAVA 字符串不匹配正则表达式 [Jj]ava,其他的两个都是匹配的。
【提示】如果想 JAVA 字符串也能匹配,可以使用正则表达式 Java|java|JAVA,其中的 “|” 是基本元字符,表示 “或关系”,即 Java、java 或 JAVA 都可以匹配。
2.2 字符类取反
在正则表达式中指定不想出现的字符,可以在字符类前加 " ^ " 符号。示例代码如下:
# coding=utf-8
# 代码文件:regex_demo3.py
# 正则表达式中字符类取反
import re
p = r'[^0123456789]' # --1
m = re.search(p, '1000')
print(m) # 不匹配
m = re.search(p, 'Python 3')
print(m) # 匹配成功运行结果如下:
> python regex_demo3.py
None
<re.Match object; span=(0, 1), match='P'>上述代码第1处定义正则表达式 [^0123456789],它表示输入字符串中出现非 0~9 数字即匹配,即出现在 [0123456789] 以外的任意一个字符即匹配成功。
2.3 区间
上面 2.2 节示例中的 [^0123456789] 正则表达式,事实上有些麻烦,这种连续的数字可以使用区间表示。区间是用连字符 "-" 表示的。例如 [0123456789] 采用区间表示为 [0-9],[^0123456789] 采用区间表示为 [^0-9]。区间还可以表示连续的英文字母字符类。例如 [a-z] 表示所有小写字母字符类,[A-Z] 表示所有大写字母字符类。
另外,也可以表示多个不同区间,[A-Za-z0-9] 表示所有英文字母和数字字符类,[0-25-7] 表示 0、1、2、5、6、7 几个字符组成的字符类。
示例代码如下:
# coding=utf-8
# 代码文件:regex_demo4.py
# 正则表达式中使用区间的方法来表示字符类
import re
p1 = r'[A-Za-z0-9]'
p2 = r'[0-25-7]'
m = re.search(p1, 'A10.3')
print(m) # 匹配成功
m = re.search(p2, 'A3489C')
print(m) # 不匹配运行结果如下:
> python regex_demo4.py
<re.Match object; span=(0, 1), match='A'>
None2.4 预定义字符类
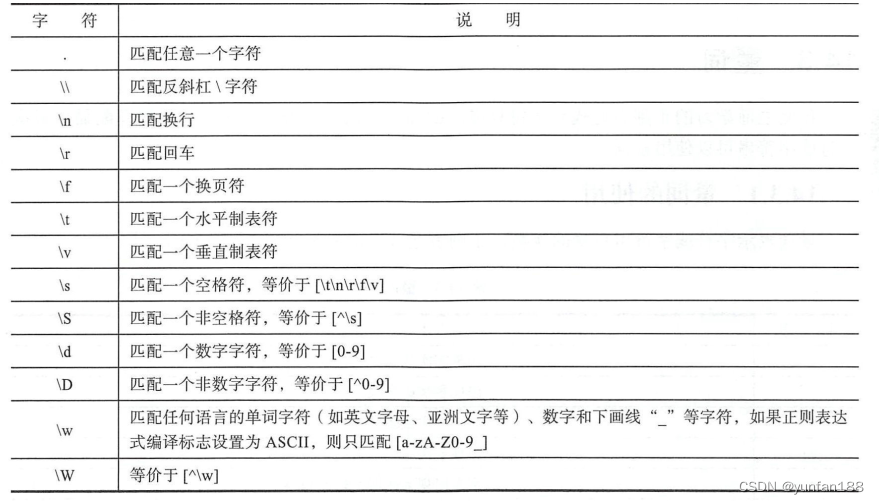
有些字符类很常用,例如 [0-9] 等。为了书写方便,正则表达式提供了预定于的字符类,例如预定义类 \d 等价于 [0-9] 字符类。预定义类如下图 2-3 所示。
示例代码如下:
# coding=utf-8
# 代码文件:regex_demo5.py
# 正则表达式中预定于的字符类
import re
# p = r'[^0123456789]'
p = r'\D' # --1
m = re.search(p, '1000')
print(m) # 匹配成功
m = re.search(p, 'Python 3')
print(m) # 不匹配
text = '你们好Hello'
m = re.search(r'\w', text) # --2
print(m) # 匹配成功运行结果如下:
> python regex_demo5.py
None
<re.Match object; span=(0, 1), match='P'>
<re.Match object; span=(0, 1), match='你'>上述代码第1处使用正则表达式 \D 替代 [^0123456789]。代码第2处通过正则表达式 \w 在 text 字符串中查找字符串,找到的结果是 '你' 字符,\w 默认是匹配任何语言的字符,所以找到中文的 '你' 字符。
三、量词
上文中学习的正则表达式元字符都只能匹配显示一次字符或字符串,如果想要匹配显示多次字符或字符串可以使用量词。
3.1 量词的使用
量词表述字符或字符串重复的次数,正则表达式中的量词如下图 3-4 所示。

量词的使用示例代码如下:
# coding=utf-8
# 代码文件:regex_demo6.py
# 正则表达式中量词的使用
import re
m = re.search(r'\d?', '87654321') # 出现数字字符1次
print(m) # 匹配字符'8'
m = re.search(r'\d?', 'ABC') # 出现数字字符0次
print(m) # 匹配字符''
m =re.search(r'\d*', '87654321') # 出现数字字符多次
print(m) # 匹配字符'87654321'
m = re.search(r'\d*', 'ABC') # 出现数字字符0次
print(m) # 匹配字符''
m = re.search(r'\d+', '87654321') # 出现数字字符多次
print(m) # 匹配字符'87654321'
m = re.search(r'\d+', 'ABC') # 没有出现至少一次数字字符
print(m) # 不匹配
m =re.search(r'\d{8}', '87654321') # 出现数字字符8次
print(m) # 匹配字符'87654321'
m =re.search(r'\d{8}', 'ABC')
print(m) # 不匹配
m =re.search(r'\d{7,8}', '87654321') # 出现数字字符8次
print(m) # 匹配字符'87654321'
m =re.search(r'\d{9,}', '87654321') #没有出现数字字符连续9次
print(m) # 不匹配运行结果如下:
> python regex_demo6.py
<re.Match object; span=(0, 1), match='8'>
<re.Match object; span=(0, 0), match=''>
<re.Match object; span=(0, 8), match='87654321'>
<re.Match object; span=(0, 0), match=''>
<re.Match object; span=(0, 8), match='87654321'>
None
<re.Match object; span=(0, 8), match='87654321'>
None
<re.Match object; span=(0, 8), match='87654321'>
None3.2 贪婪量词和懒惰量词
量词还可以分为贪婪量词和懒惰量词,贪婪量词尽可能多地匹配字符,懒惰量词会尽可能少地匹配字符。大多数计算机编程语言的正则表达式默认是贪婪量词,要想使用懒惰量词在量词后面加 "?" 元字符即可。
示例代码如下:
# coding=utf-8
# 代码文件:regex_demo7.py
# 正则表达式中贪婪量词和懒惰量词的区别和使用示例
import re
# 使用贪婪量词
m = re.search(r'\d{5,8}', '87654321') # 出现数字字符8次 --1
print(m) # 匹配字符'87654321'
# 使用懒惰量词
m =re.search(r'\d{5,8}?', '87654321') # 出现数字字符5次 --2
print(m) # 匹配字符'87654'运行结果如下:
> python regex_demo7.py
<re.Match object; span=(0, 8), match='87654321'>
<re.Match object; span=(0, 5), match='87654'>上述代码第1处使用了贪婪量词 {5,8},输入字符串 '87654321' 是长度8位的数字字符串,尽可能多地匹配字符结果是 '87654321'。代码第2处使用惰性量词 {5,8}?,输入字符串 '87654321' 是长度8位的数字字符串,尽可能少地匹配字符结果是 '87654'。
《注意》上面代码的正则表达式中的 {5,8} 中间不能有空格,否则会匹配不成功。
四、分组
本文上面学习的量词都只能重复一个字符,如果想让一个字符串作为整体使用量词,可将这个字符串放到一对小括号中,这就是分组(也称为子表达式)。
4.1 分组的使用
对正则表达式进行分组不仅可以对一个字符串整体使用量词,还可以在正则表达式中引用已经存在的分组。
示例代码如下:
# coding=utf-8
# 代码文件:regex_demo8.py
# 正则表达式中分组的使用
import re
p = r'(121){2}' # --1
m = re.search(p, '121121abcabc')
print(m) # 匹配成功
print(m.group()) # 返回匹配字符串 --2
print(m.group(1)) # 获得第一组匹配字符串 --3
p = r'(\d{3,4})-(\d{7,8})' # --4
m = re.search(p, '010-87654321')
print(m) # 匹配成功
print(m.group()) # 返回匹配字符串
print(m.groups()) # 获得所有分组的内容 --5运行结果如下:
> python regex_demo8.py
<re.Match object; span=(0, 6), match='121121'>
121121
121
<re.Match object; span=(0, 12), match='010-87654321'>
010-87654321
('010', '87654321')上述代码第1处定义的正则表达式 (121) 是将 '121' 字符串分为一组,(121){2} 表示对 '121' 重复2次,即 '121121'。代码第2处定义 match 对象的 group() 方法返回匹配的字符串,group() 方法语法如下:
match.group([group1, ...])其中参数 group1 是组编号,在正则表达式中组编号是从 1 开始的,所以代码第3处的表达式 m.group(1) 表示返回第一个组内容。
代码第4处定义的正则表达式可以用来验证固定电话号码,在 "-" 之前的是 3~4 位的区号,"-" 之后的是 7~8 位的电话号码。在该正则表达式中有两个分组。
代码第5处是 match 对象的 groups() 方法返回所有分组,返回值是一个元组。
4.2 分组命名
在Python程序中访问分组时,除了可以通过编号进行访问,还可以通过组名进行访问,前提是要在正则表达式中为分组命名。分组命名通过在组名开头添加 "?P<分组名>" 实现。
示例代码如下:
# coding=utf-8
# 代码文件:regex_demo9.py
# 正则表达式中为分组命名
import re
p = r'(?P<area_code>\d{3,4})-(?P<phone_code>\d{7,8})' # --1
m = re.search(p, '010-87654321')
print(m) # 匹配成功
print(m.group()) # 返回匹配字符串
print(m.groups()) # 获得所有分组的内容
# 通过组编号返回组内容
print(m.group(1))
print(m.group(2))
# 通过组名返回组内容
print(m.group('area_code')) # --2
print(m.group('phone_code')) # --3运行结果如下:
> python regex_demo9.py
<re.Match object; span=(0, 12), match='010-87654321'>
010-87654321
('010', '87654321')
010
87654321
010
87654321上述代码第1处定义了正则表达式,这个正则表达式与 4.1 节是一样的,可以用来验证电话号码,只是对其中的两个分组进行了命名。当在程序中访问这些带有名字的分组时,可以通过分组编号或分组名字访问,代码第2处和第3处就是通过分组名字访问分组内容。
4.3 反向引用分组
除了可以在程序代码中访问正则表达式匹配之后的分组内容,还可以在正则表达式内部引用之前的分组。
下面通过一个示例熟悉一下反向引用分组。假设由于工作需要想解析一段XML代码,需要找到某一个开始标签和结束标签,那么编写如下代码:
# coding=utf-8
# 代码文件:regex_demo10.py
# 正则表达式中为反向引用分组
import re
p = r'<([\w]+)>.*</([\w]+)>' # --1
m = re.search(p, '<a>abc</a>') # --2
print(m) # 匹配成功
m = re.search(p, '<a>abc</b>') # --3
print(m) # 匹配成功运行结果如下:
> python regex_demo10.py
<re.Match object; span=(0, 10), match='<a>abc</a>'>
<re.Match object; span=(0, 10), match='<a>abc</b>'>上述代码第1处定义的正则表达式分成了两组,两组内容完全一样。代码第2处和第3处在进行测试,结果发现它们都是匹配的。但是 <a>abc</b> 不是有效的XML代码,因为开始标签和结束标签应该是一致的。可见代码第1处的正则表达式不能保证开始标签和结束标签是一致的。为了解决这个问题,可以使用反向分组引用,即让第二组反向引用第一组。在正则表达式中反向引用分组的语法是:"\组编号",组编号是从 1 开始的。
重构上面的示例代码:
# coding=utf-8
# 代码文件:regex_demo10.py
# 正则表达式中为反向引用分组
import re
p = r'<([\w]+)>.*</\1>' # 使用反向引用 --1
m = re.search(p, '<a>abc</a>')
print(m) # 匹配成功
m = re.search(p, '<a>abc</b>')
print(m) # 匹配失败运行结果如下:
> python regex_demo10.py
<re.Match object; span=(0, 10), match='<a>abc</a>'>
None上述代码第1处是定义正则表达式,其中 \1 是反向引用第一个组。从运行结果可见,字符串 <a>abc</a> 是匹配的,而 <a>abc</b> 字符串不匹配。
4.4 非捕获分组
前面介绍的分组称为捕获分组。捕获分组的匹配子表达式结果暂时保存在内存中,以备表达式或其他程序引用,这个过程称为 “捕获”,捕获结果可以通过分组编号或组名进行引用。但是有时并不想引用子表达式的匹配结果,不想捕获匹配结果,只是将小括号作为一个整体进行匹配,此时可以使用非捕获分组,在组开头使用 "?:" 可以实现非捕获分组。
示例代码如下:
# coding=utf-8
# 代码文件:regex_demo11.py
# 正则表达式中非捕获分组分组的使用
import re
s = 'img1.jpg, img2.jpg, img3.bmp'
# 捕获分组
p = r'\w+(\.jpg)' # --1
mlist = re.findall(p, s)
print(mlist)
# 非捕获分组
p = r'\w+(?:\.jpg)' # --2
mlist = re.findall(p, s)
print(mlist)运行结果如下:
> python regex_demo11.py
['.jpg', '.jpg']
['img1.jpg', 'img2.jpg']上述代码实现了从字符串中查找 .jpg 结尾的文本,其中低吗第1处和第2处的正则表达式区别在于:前者是捕获分组,而后者是非捕获分组。捕获分组将括号中的内容作为子表达式进行捕获匹配,将匹配的子表达式(即分组的内容)返回,结果是 ['.jpg', '.jpg']。而非捕获分组将括号中的内容作为普通的正则表达式字符串进行整体匹配,即找到 .jpg 结尾的文本,所以最后的结果是 ['img1.jpg', 'img2.jpg']。
五、re模块
re 是 Python 内置的正则表达式模块,前面虽然已经使用过 re 模块的一些函数,但还有很多重要函数没有详细介绍,这一节将详细介绍这些函数。
5.1 search()和match()函数
search()和match()函数的区别如下:
- search():在输入的字符串中查找,返回第一个匹配内容,如果找到一个,返回match对象;如果没有找到,则返回None。
- match():在输入字符串开始处查找匹配内容,如果找到一个,返回match对象;如果没有找到,则返回None。
示例代码如下:
# coding=utf-8
# 代码文件: 14-正则表达式/regex_14.5.1.py
# re模块的search()和match()函数用法区别
import re
p = r'\w+@zhijieketang\.com' # 定义了一个正则表达式对象p
text = 'Tony`s email is tony_guan588@zhijieketang.com.' # --1
m = re.search(p, text)
print(m) # 匹配
m = re.match(p, text)
print(m) # 不匹配
email = 'tony_guan588@zhijieketang.com.' # --2
m = re.search(p, email)
print(m) # 匹配
m = re.match(p, email)
print(m) # 匹配
# match对象几个方法
print('match对象几个方法:') # --3
print(m.group())
print(m.start())
print(m.end())
print(m.span())运行结果如下:
>python regex_14.5.1.py
<re.Match object; span=(16, 45), match='tony_guan588@zhijieketang.com'>
None
<re.Match object; span=(0, 29), match='tony_guan588@zhijieketang.com'>
<re.Match object; span=(0, 29), match='tony_guan588@zhijieketang.com'>
match对象几个方法:
tony_guan588@zhijieketang.com
0
29
(0, 29)(1)上述代码第1处输入的text字符串开头不是email字符串(即不是:tony_guan588@zhijieketang.com),search()函数可以匹配成功,而match()函数却匹配失败。
(2)代码第2处输入的字符串开头就是email字符串(即:tony_guan588@zhijieketang.com),所以search()和match()都可以匹配成功。
(3)如果search()和match()函数匹配成功都返回match对象。match对象有一些常用方法,见代码第3处。
- group()方法返回匹配的字字符串;
- start()方法返回子字符串的开始索引;
- end()方法返回子字符串的结束索引;
- span()方法返回子字符串的区间跨度,它是一个二元素的元组。
5.2 findall() 和 finditer()函数
findall() 和 finditer() 函数的区别如下:
- findall():在输入字符串中查找所有匹配内容,如果匹配成功,则返回match列表对象,如果匹配失败则返回None。
- finaiter():在输入字符串中查找所有匹配内容,如果匹配成功,则返回容纳 match 的可迭代对象,通过迭代对象每次可以返回一个 match 对象,如果匹配失败则返回None。
示例代码如下:
# coding=utf-8
# 代码文件: 14-正则表达式/regex_14.5.2.py
# re模块的 findall()和 finditer()函数用法区别
import re
p = r'[Jj]ava' # 定义了一个正则表达式对象p
text = 'I like Java and java.'
match_list = re.findall(p, text) # --1
print(match_list)
match_iter = re.finditer(p, text) # --2
for m in match_iter: # --3
print(m.group())运行结果如下:
>python regex_14.5.2.py
['Java', 'java']
Java
java上述代码第1处的 findall() 函数返回 match 列表对象。代码第2处的 finditer() 函数返回可迭代对象。代码第3处通过 for 循环遍历可迭代对象。
5.3 字符串切割
字符串切割使用 split() 函数,该函数按照匹配的子字符串进行字符串分割,返回字符串列表对象。
re.split(pattern, string, maxsplit = 0, flags = 0)
# 其中参数 pattern 是正则表达式;参数 string 是要分割的字符串;
# 参数 maxplit 是最大分割次数,maxsplit 默认值是零,表示分割次数没有限制;参数 flags 是编译标志。示例代码如下:
# coding=utf-8
# 代码文件: 14-正则表达式/regex_14.5.3.py
# re模块的字符串切割函数split用法
import re
p = r'\d+' # 定义了一个正则表达式对象p,匹配一到多个数字
text = 'AB12CD34EF'
clist = re.split(p, text) # --1
print(clist)
clist = re.split(p, text, maxsplit = 1) # --2
print(clist)
clist = re.split(p, text, maxsplit = 2) # --3
print(clist)运行结果如下:
>python regex_14.5.3.py
['AB', 'CD', 'EF']
['AB', 'CD34EF']
['AB', 'CD', 'EF']上述代码调用 split() 函数通过数字对 'AB12CD34EF' 字符串进行分割,其中正则表达式 \d+ 表示匹配一到多个数字。
代码第1处的 split() 函数中参数 maxsplit 和 flags 都是函数默认参数值,分割的次数没有限制,所以分割结果是 ['AB', 'CD', 'EF'] 列表。
代码第2处的 split() 函数指定参数 maxsplit 为 1,也就是说,只对 text 字符串分割一次,所以分割结果是 ['AB', 'CD34EF'] 列表,列表元素的个数是 maxsplit + 1。
代码第3处的 split() 函数指定参数 maxsplit 为 2,2 是最大可能得分割次数,因此 maxsplit >= 2 与 maxsplit = 0 是一样的输出结果。
5.4 字符串替换
字符串替换使用 sub() 函数,该函数用于替换匹配的子字符串,返回值是替换后的新字符串。
re.sub(pattern, repl, string, count = 0, flags = 0)
# 参数 pattern 是正则表达式;
# 参数 repl 是替换字符串;
# 参数 string 是要提供的字符串;
# 参数 count 是要替换的最大次数,默认值是零,表示替换次数没有限制;
# 参数 flags 是编译标志。示例代码如下:
# coding=utf-8
# 代码文件: 14-正则表达式/regex_14.5.4.py
# re模块的字符串替换函数sub用法
import re
p = r'\d+' # 定义了一个正则表达式对象p,匹配一到多个数字
text = 'AB12CD34EF'
replace_text = re.sub(p, ' ', text) # --1
print(replace_text)
replace_text = re.sub(p, ' ', text, count = 1) # --2
print(replace_text)
replace_text = re.sub(p, ' ', text, count = 2) # --3
print(replace_text)运行结果如下:
>python regex_14.5.4.py
AB CD EF
AB CD34EF
AB CD EF上述代码调用 sub() 函数使用空格符替换 'AB12CD34EF' 字符串中的数字。
代码第1处的 sub() 函数中参数 count 和 flags 都是默认值,替换的最大次数没有限制,所以替换结果是 AB CD EF。
代码第2处的 sub() 函数指定参数 count 为 1,所以替换结果是 AB CD34EF。
代码第3处的 sub() 函数指定参数 count 为 2,2 是最大可能的替换次数,因此 count >= 2 和 count = 0 是一样的输出结果。
六、编译正则表达式
在实际项目开发中,为了提供开发效率,还可以对正则表达式进行编译。编译的正则表达式可以重复使用,这样能减少正则表达式的解析和验证,提高效率。
在 re 模块中的 compile() 函数可以编译正则表达式,compile函数语法如下:
re.compile(pattern[, flag = 0])
# 其中,参数 pattern 是正则表达式,参数 flags 是编译标志。
# compile()函数返回一个已编译的正则表达式对象 regex。6.1 已编译正则表达式对象
compile() 函数返回一个编译的正则表达式对象,该对象也提供了文本的匹配、查找和替换等操作的方法,这些方法与上文 4.5 节介绍的 re 模块函数功能类似。下表所示是已编译正则表达式对象方法与 re 模块函数对照表。

正则表达式方法需要一个已编译的正则表达式对象才能调用,这些方法与 re 模块函数功能类似,这里不再一一赘述。注意方法 search()、match()、findall() 和 finditer() 中的参数 pos 为开始查找的索引,参数 endpos 为结束查找的索引。
示例代码如下:
# coding=utf-8
# 代码文件: 14-正则表达式/regex_14.6.1.py
# 编译正则表达式及其用法
import re
p = r'\w+@zhijieketang\.com'
regex = re.compile(p) # --1
text = "Tony`s email is tony_guan588@zhijieketang.com"
m = regex.search(text)
print(m) # 匹配
m = regex.match(text)
print(m) # 不匹配
p = r'[Jj]ava'
regex = re.compile(p) # --2
text = "I like Java and java."
match_list = regex.findall(text)
print(match_list)
match_iter = regex.finditer(text)
i = 0
for m in match_iter:
print("iter{0}:{1}".format(i, m.group()))
i += 1
p = r'\d+'
regex = re.compile(p) # --3
text = "AB12CD34EF"
clist = regex.split(text)
print(clist)
replace_text = regex.sub(' ', text)
print(replace_text)运行结果如下:
> python regex_14.6.1.py
<re.Match object; span=(16, 45), match='tony_guan588@zhijieketang.com'>
None
['Java', 'java']
iter0:Java
iter1:java
['AB', 'CD', 'EF']
AB CD EF上述代码第 1 处、第 2 处和第 3 处都是编译正则表达式,然后通过已编译的正则表达式对象 regex 调用方法实现文本匹配、查找和替换等操作。这些方法与re 模块函数类似,这里不再赘述。
6.2 编译标志
compile() 函数编译正则表达式对象时,还可以设置编译标志。编译标志可以改变正则表达式引擎行为。本节将介绍几种常用的编译标志。
1)ASCII 和 Unicode
在上文中介绍过预定义字符类 \w 和 \W,其中 \w 匹配单词字符,在 Python 2 中是 ASCII 编码,在 Python 3 中则是 Unicode 编码,可以包含任何语言的单词字符。可以通过编译标志 re.ASCII(或 re.A)设置采用 ASCII 编码,通过编译标志 re.UNICODE(或 re.U)设置采用 Unicode 编码。
示例代码如下:
# coding=utf-8
# 代码文件: 14-正则表达式/regex_14.6.2_1.py
# 正则表达式的编译标志:ASCII和Unicode
import re
text = '你们好Hello'
p = r'\w+' # 定义正则表达式
regex = re.compile(p, re.U) # --1
m = regex.search(text) # --2
print(m) # 匹配
m = regex.match(text) # --3
print(m) # 匹配
regex = re.compile(p, re.A) # --4
m = regex.search(text) # --5
print(m) # 匹配
m = regex.match(text) # --6
print(m) # 不匹配运行结果如下:
> python regex_14.6.2_1.py
<re.Match object; span=(0, 8), match='你们好Hello'>
<re.Match object; span=(0, 8), match='你们好Hello'>
<re.Match object; span=(3, 8), match='Hello'>
None(1) 上述代码第 1 处设置编译标志为 Unicode 编码,代码第 2 处用 search() 方法匹配 “你们好Hello” 字符串,代码第3处的 match() 方法也可匹配 “你们好Hello” 字符串。
(2) 代码第 4 处设置编译标志为 ASCII 编码,代码第 5 处用 search() 方法匹配 “Hello” 字符串,而代码第 6 处的 match() 方法不可匹配。
2)忽略大小写
默认情况下,正则表达式引擎对大小写是敏感的,但有时在匹配过程中需要忽略大小写,可以通过编译标志 re.IGNOREECASE(或 re.I)实现。
示例代码如下:
# coding=utf-8
# 代码文件: 14-正则表达式/regex_14.6.2_2.py
# 正则表达式的编译标志:忽略大小写
import re
p = r'(java).*(python)' # --1
regex = re.compile(p, re.I) # --2
m = regex.search('I like Java and Python.')
print(m) # 匹配
m = regex.search('I like JAVA and Python.')
print(m) # 匹配
m = regex.search('I like java and Python.')
print(m) # 匹配运行结果如下:
> python regex_14.6.2_2.py
<re.Match object; span=(7, 22), match='Java and Python'>
<re.Match object; span=(7, 22), match='JAVA and Python'>
<re.Match object; span=(7, 22), match='java and Python'>上述代码第 1 处定义了正则表达式。代码第 2 处是编译正则表达式,设置编译参数 re.I 忽略大小写。由于忽略了大小写,代码中三个 search() 方法都能找到匹配的字符串。
3)点元字符匹配换行符
默认情况下正则表达式引擎中点 “.” 元字符可以匹配除换行符外的任何字符,但是有时需要点 “.” 元字符也能匹配换行符,这可以通过编译标志 re.DOTALL(或 re.S)实现。
示例代码如下:
# coding=utf-8
# 代码文件: 14-正则表达式/regex_14.6.2_3.py
# 正则表达式的编译标志re.DOTALL(或re.S):点元字符匹配换行符
import re
p = r'.+' # 正则表达式
regex = re.compile(p) # 没有带编译标志 --1
m = regex.search('Hello\nWorld.') # --2
print(m) # 匹配Hello
regex = re.compile(p, re.S) # --3
m = regex.search('Hello\nWorld.') # --4
print(m) # 匹配Hello\nWorld.运行结果如下:
> python regex_14.6.2_3.py
<re.Match object; span=(0, 5), match='Hello'>
<re.Match object; span=(0, 12), match='Hello\nWorld.'>上述代码第 1 处编译正则表达式时没有设置编译标志。代码第 2 处匹配结果是 'Hello' 字符串,因为正则表达式引擎遇到换行符 “\n” 时,认为它是不匹配的,就停止查找。而代码第 3 处编译了正则表达式,并设置编译标志 re.DOTALL。代码第 4 处匹配结果是 'Hello\nWorld.' 字符串,因为正则表达式引擎遇到换行符 “\n” 时认为它是匹配的,会继续查找。
4)多行模式
编译标志 re.MULTILINE(或 re.M)可以设置为多行模式,多行模式对于元字符 ^ 或 $ 行为会产生影响。默认情况下,^ 和 $ 匹配字符串的开始和结束,而在多行模式下,^ 和 $ 匹配任意一行的开始和结束。
示例代码如下:
# coding=utf-8
# 代码文件: 14-正则表达式/regex_14.6.2_4.py
# 正则表达式的编译标志re.MULTILINE(或re.M):多行模式
import re
p = r'^World' # 正则表达式 --1
regex = re.compile(p) # 没有带编译标志 --2
m = regex.search('Hello\nWorld.') # --3
print(m) # 不匹配
regex = re.compile(p, re.M) # --4
m = regex.search('Hello\nWorld.') # --5
print(m) # 匹配World运行结果如下:
> python regex_14.6.2_4.py
None
<re.Match object; span=(6, 11), match='World'>(1) 上述代码第 1 处定义了正则表达式 ^World,即匹配 World 开头的字符串。代码第 2 处进行编译时并没有设置多行模式,所以代码第 3 处 'Hello\nWorld.' 字符串是不匹配的,虽然 'Hello\nWorld.' 字符串事实上是两行,但默认情况 ^World 只匹配字符串的开始。
(2) 代码第 4 处重新编译了正则表达式,此时设置了编译标志 re.M,开启了多行模式。在多行模式下,^ 和 $ 匹配字符串任意一行的开始和结束,所以代码第 5 处会匹配 'World' 字符串。
5)详细模式
编译标志 re.VERBOSE(或 re.X)可以设置详细模式,详细模式下可以在正则表达式中添加注释,可以有空格和换行,这样编写的正则表达式非常便于阅读。
示例代码如下:
# coding=utf-8
# 代码文件: 14-正则表达式/regex_14.6.2_5.py
# 正则表达式的编译标志re.VERBOSE(或re.X):设置详细模式
import re
p = """(java) # 匹配java字符串
.* # 匹配任意字符零个或多个
(python) # 匹配python字符串
""" # --1
regex = re.compile(p, re.I | re.VERBOSE) # --2
m = regex.search('I like Java and Python.')
print(m) # 匹配
m = regex.search('I like JAVA and Python.')
print(m) # 匹配
m = regex.search('I like java and Python.')
print(m) # 匹配运行结果如下:
> python regex_14.6.2_5.py
<re.Match object; span=(7, 22), match='Java and Python'>
<re.Match object; span=(7, 22), match='JAVA and Python'>
<re.Match object; span=(7, 22), match='java and Python'>(1) 上述代码第 1 处定义的正则表达式原本是 (java).*(python),现在写成多行表示,其中还有注释和空格等内容。如果没有设置为详细模式,这样的正则表达式会抛出异常。由于正则表达式中包含了换行等符号,所以需要使用使用双重单引号或三重双引号括起来,而不是使用原始字符串。
(2) 代码第 2 处编译正则表达式时,设置了两个编译标志 re.I 和 re.VERBOSE,当需要设置多编译标志时,编译标志之间需要使用位或运算符 “|”。
七、正则表达式小结
本文主要讲述了Python正则表达式的概念和用法,正则表达式中理解各种元字符的含义和用法是难点也是重点。重点介绍了 Python 正则表达式的 re 模块,需要重点掌握 search()、match()、findall()、sub() 和 split() 等方法的使用。最后介绍了编译正则表达式,需要了解编译对象的方法和编译标志。
参考
《Python从小白到大牛》
《Python基础教程(第3版)》
《Python学习手册(第4版)》
















 308
308











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









