







第十一章 使用Apriori算法进行关联分析
- Apriori算法
- 频繁项集生成
- 关联规则生成
从大规模数据集中寻找物品间的隐含关系被称作为关联分析(association analysis)和关联规则学习(association rule learning)。
11.1 关联分析
关联分析有两种形式:频繁项集、关联规则。频繁项集(frequent item sets)是经常出现在一块的物品的集合,关联规则(association rules)暗示两种物品之间可能存在很强的关系。使用频繁项集和关联规则,商家可以更好地理解他们的顾客。
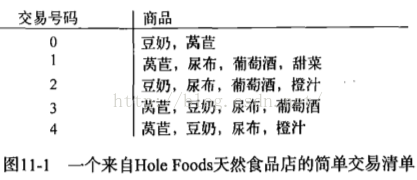
当寻找频繁项集时,有两个概念比较重要:支持度和可信度。
一个项集的支持度(support)被定义为数据集中包含该项集的记录所占的比例。由上图可以看出项集{豆奶}的支持度为4/5,项集{豆奶,尿布}的支持度为3/5。支持度是针对项集来说,因此可以定义一个最小支持度过滤较小支持度的项集。
可信度或置信度(confidence)是针对关联规则来定义的。可被定义为conf(B) = support({A,B})/support({A})。
支持度和置信度是用来量化关联分析是否成功的方法。
11.2 Apriori原理

上图显示了4种商品所有可能的组合。对给定的集合项集{0,3},需要遍历每条记录并检查是否同时包含0和3,扫描完后除以记录总数即可得支持度。对于包含N种物品的数据集共有2的N次方-1种项集组合,即使100种,也会有1.26×10的30次方种可能的项集组成。
为降低计算时间,可用Apriori原理:如果某个项集是频繁的,那么它的所有子集也是频繁的。逆反:如果一个项集是非频繁集,那么它的所有超集也是非频繁的。

11.3 使用Apriori算法来发现频繁集
Apriori算法的两个输入参数分别是最小支持度和数据集。首先生成所有单个物品的项集列表,得到满足最小支持度的项集,将其进行组合生成包含两个元素的项集,继续剔除不满足最小支持度的项集,重复直到所有项集都被去掉。
数据集扫描的伪代码:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 483
483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









