







通用爬虫工作原理与特性
搜索器是搜索引擎中很关键也是很基础的构件。通常利用网络爬虫技术实现搜索器的功能。 不同应用,爬虫系统的实现方式各有千秋,但其具有通用的特性及流程框架。通用爬虫框架图如图3-1所示。
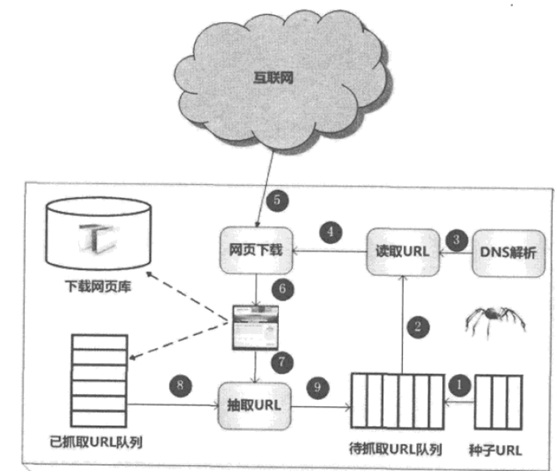
确定种子URL,将其放入待抓取URL队列,爬虫从该队列开始依次读取,将URL通过DNS解析,完成网址与IP地址的转换,将网页相对路径交给网页下载器下载网页内容。将已下载的本地网页库存储至页面库等待建立索引项等后续处理,并将该已下载URL放入已抓取URL队列中,避免重复抓取。同时对刚下载的网页,抽取所有链接信息,与已抓取URL队列对比,将为抓取URL加入到未抓取URL队列队尾。如此循环往复,直至未抓取URL队列清空。上述为爬虫通用工作流程,除此之外,高效的爬虫还应具备网页去重及网页反作弊的功能。
优秀的爬虫除了上述功能完整外,还具备如下通用特性。
高效性。主要衡量网页抓取速度。设计爬虫时,程序访问磁盘的操作方式及实现时数据结构的选择对爬虫的效率有至关重要的影响。
可扩展性。爬虫需要抓取的网页数据量巨大,通常通过扩展爬虫系统的方式来解决该问题。目前,大型网站爬虫均是分布式爬虫。即,多台服务器抓取,且每台服务器上部署多个爬虫项目,每个爬虫以多线程形式运行,增加并发。
健壮性。网页数据多样,爬虫经常会出现各种异常情况,甚至抓取服务器死机,健壮的服务器应该做到断点续爬。
友好性。频繁的爬取网页会对网站托管服务器造成极大的压力,或者有些网站并不希望所有数据都抓取。因此便出现了爬虫抓取协议和网页禁抓标记。爬虫抓取协议指网站所有者生成指定的robot.txt文件放于网站服务器根目录下,该文件内记录了不允许爬虫爬取的目录。网页禁抓协议只网页存在robots标记,并通过content指定禁止的操作方式。
从用户角度出发,优秀的爬虫应具备如下特性。抓取网页覆盖率大、抓取网页时新性及抓取网页重要性高(搜索精度高)。符合以上三点的网络爬虫,将为用户带来绝佳的用户体验。
- 暗网抓取
目前,搜索引擎主流的抓取策略主要有宽度优先遍历策略、非完全PageRank策略、OPIC策略(Online Page Importance Computation)、大站优先策略等。通过以上不同策略,对待抓取URL队列进行更新,通过常规的网页解析达到海量数据抓取。但是,很多网站的内容以数据库形式存在,并没有显示链接指向数据库内数据记录,需要用户输入查询后,才可能得到相关数据。于是,暗网技术应运而生。
暗网技术的关键在于如何全棉精确的查询条件。通常有如下策略。查询组合问题和文本框填写策略。
查询组合问题。Google提出了富含信息查询模板,并运用ISIT算法来提高系统效率。假定完整的查询有N个不同属性构成,每个属性Ni有M个不同的赋值项,当输入查询属性时,若有c个确定的属性被赋值,则称该模板为C维模板。富含信息查询模板是指对于每个固定的模板,若每个模板属性都被赋值,形成不同的查询组合,若查询返回的页面内容差异较大,则称该模板为富含信息模板。Google利用ISIT算法,从一维模板开始寻找富含信息模板,若存在扩展到二位,再次寻找富含信息模板,逐步增加维数,直至无富含信息模板。利用该方法,与完全组合相比,大幅度提升了系统效率。
文本框填写问题。通过人工网站定位,为不同网站提供不同的关键词汇表,爬虫依据此词汇表提交查询,并从相关返回信息中挖掘相关关键词,形成新的查询词表,依次查询,循环往复,直至无法下载到新内容为止。通过人工网站定位与递归迭代查询,尽可能覆盖数据库信息。















 2843
2843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









