







说明:本文所讲的Spark资源调度与任务调度是standalone模式下的调度,其它模式下的调度(如Yarn、Mesos等)暂不涉及。
我们结合具体的应用案例——WordCount.scala 来详细说明Spark是如何进行资源调度与任务调度的。WordCount.scala代码:
package com.beijing.scala.spark.operator
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object WC {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(conf)
val linesRDD = sc.textFile("cs")
val wordsRDD = linesRDD.flatMap { _.split(" ") }
val pairRDD = wordsRDD.map { (_,1) }
val resultRDD = pairRDD.reduceByKey(_+_)
resultRDD.sortBy(_._2).foreach(println)
sc.stop()
}
}
这个案例是计算某一文本中各个单词出现的次数,其具体的运算逻辑不用关注,我们关注的是在该应用提交到Spark集群的时候,Spark是如何进行资源和任务的调度的。
提交应用到Spark集群的命令:
./spark-submit --master spark://hadoop1:7077 --deploy-mode client --class com.beijing.scala.spark.operator.WC ../lib/WC.jar
命令说明:
spark-submit : 是SPARK_HOME/bin下的一个命令
--master : master主机的地址
--deploy-mode : 部署模式。分为client模式 与 cluster模式。两种模式的区别在后文会有介绍。
--class : 应用的入口。 此处是WC类中的main()方法。
../lib/WC.jar : jar包的路径
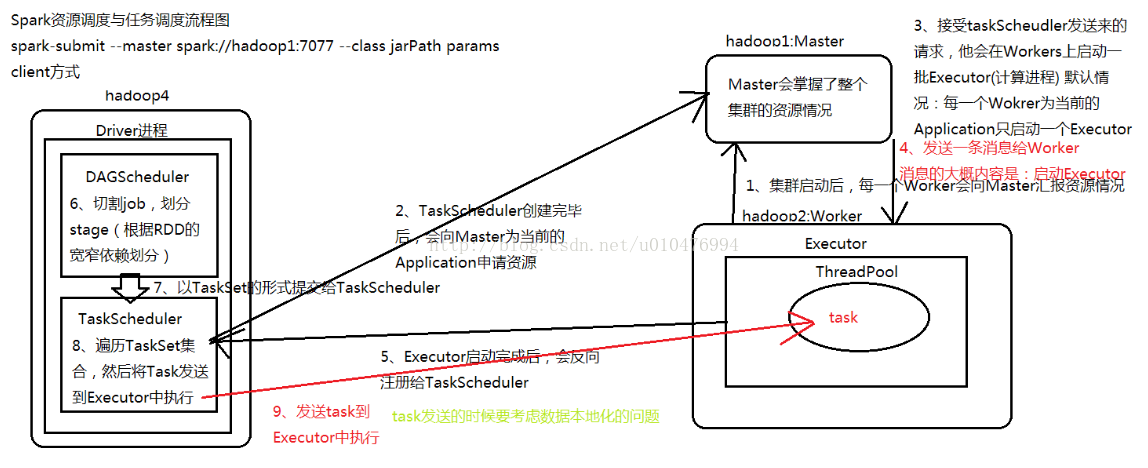
在使用上述命令提交应用后,Spark会执行一系列的操作,来完成资源调度与任务调度的工作。下面我们跟随代码一步步的拆分,详细的了解每一行代码会执行什么操作。首先,我们通过图示来了解一下Spark集群的情况:
在我的Spark集群中,一共有三台主机:hadoop1~hadoop3,其中hadoop1作为master 节点,hadoop2、hadoop3作为Worker节点,两台Worker节点功能相同,为了图示清晰,在图示中省略了hadoop3。hadoop4是Spark集群的客户端。
资源调度与任务调度的详细流程:
1、Spark集群启动时, 所有的Worker节点会想master节点上报自身的资源信息,这样master节点就掌握了集群中每一个worker节点有多少资源可供使用。
2、在客户端(hadoop4)通过spark-submit命令提交任务时,Spark会根据路径找到Application的入口函数,并依次执行函数语句:
val conf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(conf)
在创建SparkContext对象的过程中,Spark会通过底层代码创建两个对象: DAGScheduler(负责切分job,划分stage) 和 TaskScheduler(负责task分发) 。 TaskScheduler对象创建完毕后,会向master为当前的Application申请资源。
3、master(hadoop1节点) 接收到来自TaskScheduler的请求后,会在Workers上启动一批Executor(用于计算的进程)。默认情况下,每一个Worker会为当前的Application创建一个Executor进程。
4、master节点继续向worker节点发送消息,启动Executors。这时,每个Executor进程会创建一个ThreadPool,以供使用。
5、Executor启动完成后,会反向注册给TaskScheduler,这样TaskScheduler对象就会持有一个可用的Executor的列表。
6、跟随代码继续往下走,会遇到flatMap、map、reduceByKey、foreach,其中前三个算子是transformation类的算子,foreach是Action类算子。Transformation类的算子都是懒执行,Action类的算子都是立即执行。所以,直到执行到foreach时,才会触发运算。这时,由DAGSchedulor类对job进行切割(每遇到一个Action类算子,就算一个job),划分stage。划分的依据是根据RDD的宽窄依赖划分的。
7、DAGScheduler 以TaskSet的形式,将task提交给TaskScheduler。
8、TaskScheduler会遍历每一个task , 然后将task发送给Executor执行(由于TaskScheduler保留有Executor的列表,所以TaskScheduler知道task应该发送给哪些Executor)。在task发送的时候,spark会自动考虑到数据本地化的问题(即在数据所在的节点上执行task)。
9、遇到sc.stop(),释放所有资源。
补充:
Spark 与 MapReduce 的区别(Spark为什么比MR运算速度快)?
1、Spark是基于内存迭代的,而MR是基于磁盘迭代的;
2、Spark的计算模式是pipeline模式, 即1+1+1=3
MR的计算模式是: 1+1=2 , 2+1=3
3、Spark是可以进行资源复用的,而MR无法进行资源复用
注:Spark的资源复用指的是:同一个Application中,不同的job之间可以进行资源复用,而Application之间是无法进行资源复用的。
4、Spark是粗粒度的资源调度
MR是细粒度的资源调度
注:粗粒度与细粒度:
粗粒度(典型:spark):在Application执行之前,将所有的资源全部申请完毕。申请成功后,再进行任务的调度,当所有的任务执行完毕后,才会释放这部分资源。
细粒度(典型:MR):在Application执行之前,不需要将资源全部申请好,执行进行任务调度。在每一个task执行之前,自己去申请资源,资源申请成功后,才会执行任务。当任务执行完成后,立即释放这部分资源。
优缺点:
Spark的优点即是MR的缺点,Spark的缺点是MR的优点。
| Spark | MR | |
| 优点 | 在每一个task执行之前,不需要自己去申请资源,task启动的时间短,相应的stage、job和application耗费的时间变短 | 一个task执行完毕后,会立即释放这部分资源,集群的资源可以充分利用 |
| 缺点 | 在所有的task执行完毕后才会释放资源,导致集群的资源无法充分利用 | 每一个task在执行之前,需要自己去申请资源,这样就导致task启动时间变长,进而导致stage、job、application的运行时间变长 |
Spark部署模式:client模式 与 cluster模式:
以client模式部署时, Driver进程会在客户端创建,因此可以在client上跟踪到task的运行情况 以及 task的运行结果。
以cluster模式部署时,Driver进程会在集群中的某一台Worker主机上创建,因此在客户端上无法跟踪到task的运行情况和运行结果。task的运行情况和运行结果可以通过web的方式加以查看(spark://hadoop1: 8080,选择已完成的task,可查看详情)。















 179
179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









