







最近,语音克隆领域精彩迭出!
前段时间刚分享过升级版 CosyVoice2:
阿里开源TTS CosyVoice 再升级!语音克隆玩出新花样,支持流式输出
最近,又看到一款开源的语音合成(TTS)系统。
今日分享,将介绍 Spark-TTS,并带大家本地部署体验,为本地 TTS 选型提供参考。
1. Spark-TTS 简介

与已有 TTS 方案相比,Spark-TTS 主要解决的是:控制能力有限、跨语言表现较差、声音风格固定等问题。
老规矩,简要介绍下项目亮点:
- 零样本语音克隆:实测 3 秒音频就足够;
- 跨语言支持:支持中文和英文;
- 可控音频生成::结合 Qwen-2.5,自动调整语气、停顿、强调等语音表达。
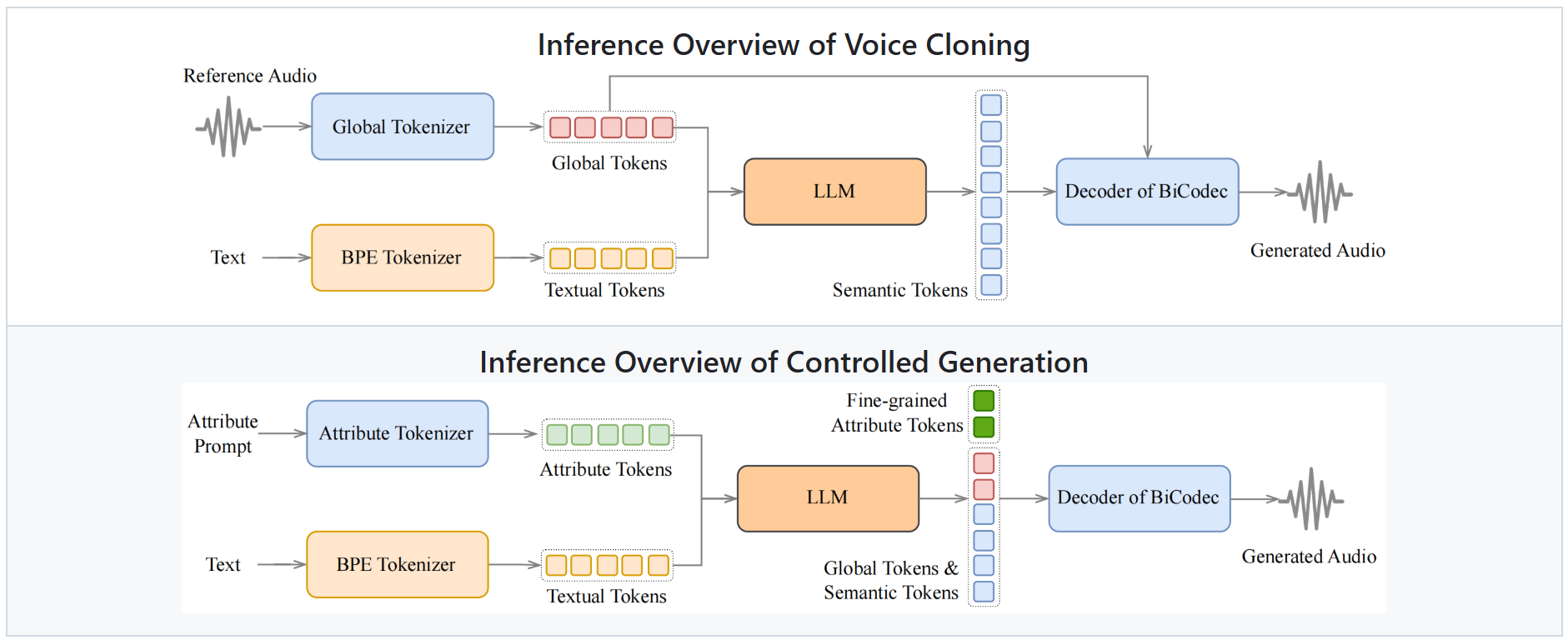
下图分别展示了 语音克隆 和 可控生成 的技术架构:
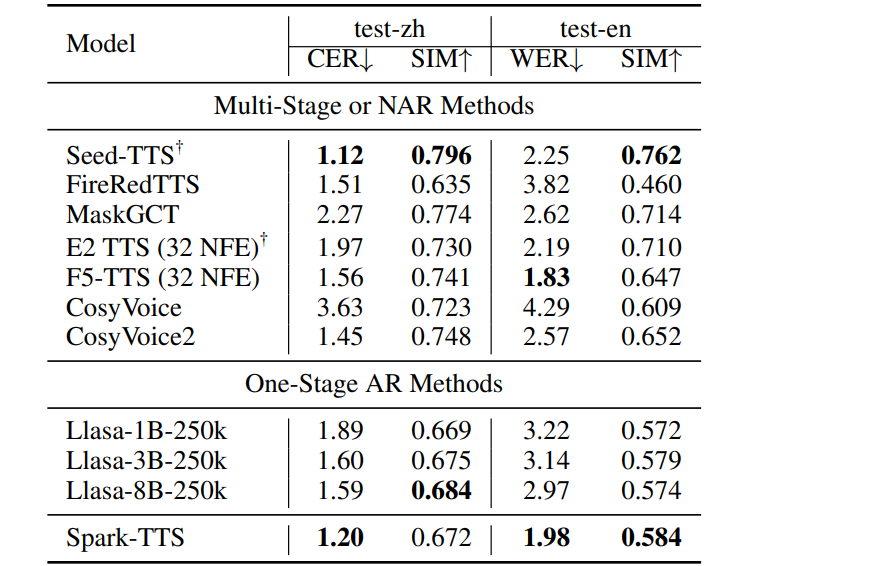
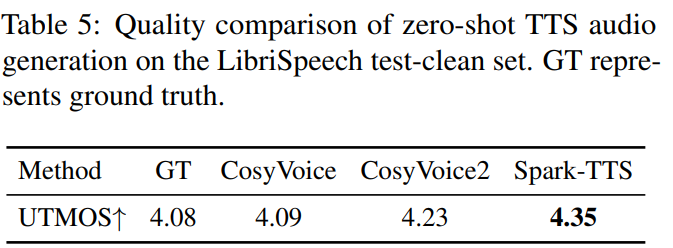
从技术报告上看,各项指标还是 SOTA,尤其是语音保真度:
不吹不擂,下面我们本地部署实测下,看看效果如何?
2. 本地部署
首先,下载项目仓库,安装环境依赖。
git clone https://github.com/SparkAudio/Spark-TTS
cd Spark-TTS
然后,拉取模型权重(国内用户推荐直接从 modelscope 下载):
pip install modelscope
modelscope download --model SparkAudio/Spark-TTS-0.5B --local_dir ./pretrained_models/Spark-TTS-0.5B
下载的模型权重保存到当前目录./pretrained_models/Spark-TTS-0.5B,大约占用 3.7G 空间,耗时 5min 左右。
2.1 速度测试
Spark-TTS 支持两种推理方式:
- 音色克隆
- 可控生成
我们先来测试下推理速度:
1. 音色克隆:
推理代码如下:
import time
import soundfile as sf
from cli.SparkTTS import SparkTTS
model = SparkTTS('./pretrained_models/Spark-TTS-0.5B')
start_time = time.time()
wav = model.inference(
text='你好,欢迎使用语音合成服务。',
prompt_speech_path='src/demos/trump/trump_en.wav',
)
speech_len = len(wav) / 16000
print('yield speech len {}, rtf {}'.format(speech_len, (time.time() - start_time) / speech_len))
sf.write('output.wav', wav, 16000)
yield speech len 2.82, rtf 1.9358745703460478
yield speech len 16.72, rtf 1.1224767950733314
2. 可控生成:
推理代码只需修改请求参数如下:
wav = model.inference(
text='你好,欢迎使用语音合成服务。',
gender='female',
pitch='moderate',
speed='moderate',
)
yield speech len 2.38, rtf 1.649330443694812
yield speech len 12.84, rtf 1.222021631734022
TTS 中通用的速度评估指标为 rtf,也即 推理耗时/生成音频耗时,指标越低,代表推理速度越快!
可以发现两种方式的 rtf 均大于 1!
2.2 显存占用
首先,模型加载后的显存占用:
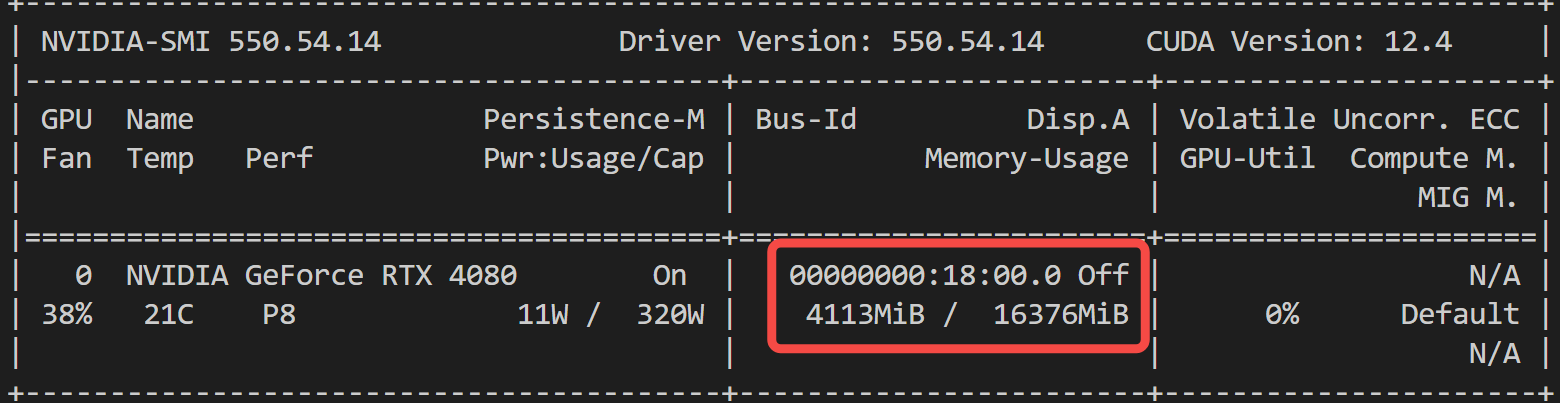
推理时显存占用:
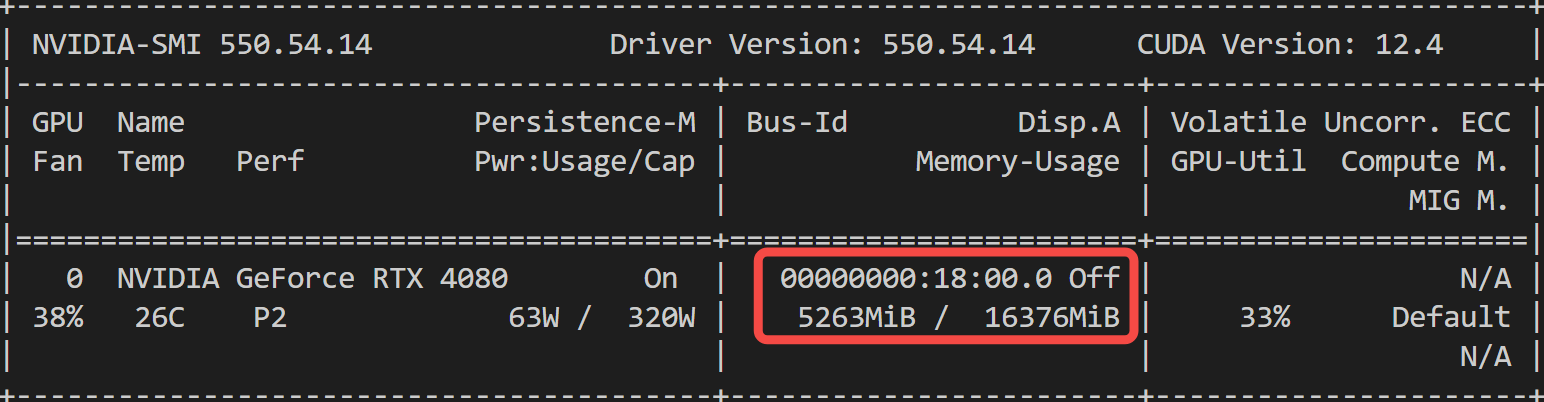
相比 CosyVoice2 依然不占优势!
2.3 效果展示
由于插入音频比较麻烦,感兴趣的朋友可前往官网查看:https://sparkaudio.github.io/spark-tts/
这里只说一点:对于数字播报这一老大难问题,翻车了!
测试文本如下:
2024年12月21日,你好,欢迎使用语音合成服务,共收录2000余种语言。
不知各位体验如何,欢迎评论区聊!
2.4 服务端部署
项目中没有提供部署代码,这里采用 FastAPI 完成服务端。(完整代码,可在文末自取)
首先,定义一个数据模型,用于接收POST请求中的数据:
class TTSRequest(BaseModel):
tts_text: str # 待合成的文本
voice_id: Optional[str] = None # 参考语音的id
voice_text: Optional[str] = None # 参考语音的文本
gender: Optional[str] = None # 性别 female | male
pitch: Optional[str] = None # 音高 very_low | low | moderate | high | very_high
speed: Optional[str] = None # 语速 very_low | low | moderate | high | very_high
接口功能函数:
@app.post("/sparktts")
def tts(request: TTSRequest):
with torch.no_grad():
if not request.tts_text:
return JSONResponse(status_code=400, content={'message': 'tts_text is required'})
if request.voice_id:
speech_path = f'{current_dir}/src/demos/{request.voice_id}.wav'
if not os.path.exists(speech_path):
return JSONResponse(status_code=400, content={'message': f'voice_id {request.voice_id} not found'})
wav = model.inference(
request.tts_text,
prompt_speech_path=speech_path,
)
elif request.gender:
wav = model.inference(
request.tts_text,
gender=request.gender,
pitch=request.pitch,
speed=request.speed,
)
else:
return JSONResponse(status_code=400, content={'message': 'voice_id or gender is required'})
headers = {
"Content-Type": "audio/pcm",
"X-Sample-Rate": "16000", # 假设采样率是 16kHz
"X-Channel-Count": "1" # 假设单声道
}
wav = (wav * 32767).astype(np.int16)
wav_bytes = io.BytesIO()
wav_bytes.write(wav.tobytes())
wav_bytes.seek(0)
return StreamingResponse(wav_bytes, media_type='audio/pcm', headers=headers)
注意:模型原始输出为 numpy,可转成 int16 以 pcm 格式输出。
最后,启动服务:
export CUDA_VISIBLE_DEVICES=0
nohup uvicorn spark_server:app --host 0.0.0.0 --port 3008 > server.log 2>&1 &
echo "Server started"
写在最后
本文分享了最新的开源语音克隆工具:Spark-TTS,并进行了本地部署实测。
有一说一,Spark-TTS 的生成保真度还是 OK 的,但就推理速度,相比 fish-speech / cosyvoice2,毫无优势可言。
如果对你有帮助,欢迎点赞收藏备用。
本文服务部署代码已上传云盘,有需要的朋友,公众号后台回复spark自取!
为方便大家交流,新建了一个 AI 交流群,公众号后台「联系我」,拉你进群。

















 4183
4183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









