







前段时间,和大家分享过一款语音克隆神器:
FishSpeech 实测,免费语音克隆神器,5分钟部署实战,让川普给你来段中文绕口令?
时隔 5 个月,fish-speech 发布重大更新,最新版本已到 1.5。
今日分享,将介绍 fish-speech 的最新更新,并带大家本地部署体验,为本地 TTS 选型提供参考。
1. Fish-Speech 简介
Fish Speech 1.5 目前支持13种语言,在匿名的 TTS Arena 上排名第二,仅次于闭源的 ElevenLabs。
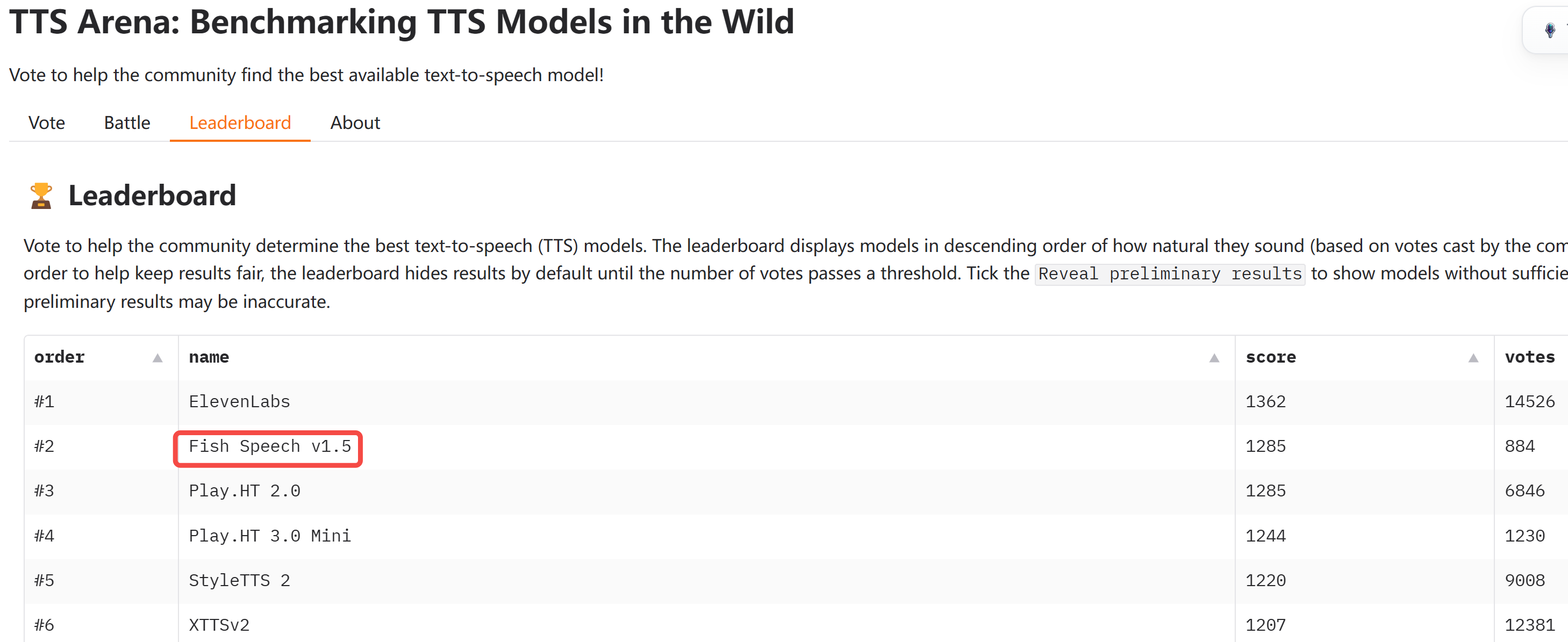
相比 1.4,Fish Speech 1.5 有哪些亮点?
- DualAR 架构:双自回归Transformer设计。主 Transformer 以 21Hz 运行,次Transformer将潜在状态转换为声学特征。计算效率和输出质量都优于传统的级联方法。
- 训练数据:拥有 100 万小时的多语言训练数据;
- 高准确率:英文单词错误率(WER)为3.5%,英文字符错误率(CER)为1.2%,中文字符错误率(CER)为1.3%;
- 低延迟:语音克隆延迟低于 150 毫秒。
- 强泛化:摒弃了传统的音素依赖,直接理解与处理文本,无需繁杂的语音规则库。
本次更新,预训练模型同样开源。
下面我们实操本地部署,看看效果如何?
2. 本地部署
首先,下载项目仓库,根据官方文档,安装环境依赖。
git clone https://github.com/fishaudio/fish-speech
cd fish-speech
然后,下载模型权重:
huggingface-cli download fishaudio/fish-speech-1.5 --local-dir checkpoints/fish-speech-1.5
# 或者
git clone https://hf-mirror.com/fishaudio/fish-speech-1.5
当然,也可以拉取官方最新镜像,采用 docker 容器的方式部署:
# 拉取镜像
docker pull fishaudio/fish-speech:latest-dev
# 运行镜像
docker run -d --name fish-speech --gpus all -p 7860:7860 fishaudio/fish-speech:latest-dev
2.1 服务端启动
项目中已经提供了部署代码,服务端一键启动代码如下:
export CUDA_VISIBLE_DEVICES=1
nohup python tools/api_server.py --listen 0.0.0.0:3003 --compile > server.log 2>&1 &
2.2 客户端请求
服务端成功启动后,在编写客户端请求时,需重点了解下请求体的组成。
在 tools/server/model_manager.py 中有加载模型的定义。
tools/schema.py中定义了语音合成接口 ServeTTSRequest中的所有字段:
class ServeTTSRequest(BaseModel):
text: str
references: list[ServeReferenceAudio] = []
reference_id: str | None = None
seed: int | None = None
use_memory_cache: Literal["on", "off"] = "off"
streaming: bool = False
这里重点需要关注的几个参数是:
text:待合成的文本;references:待克隆的参考音频和参考文本;reference_id:待克隆的音色 id,和references只需传入一个;seed:如果不需要语音克隆,用于固定语音合成的音色;use_memory_cache:传入references时会生效,使用缓存中的音频编码;streaming:是否进行流式合成。
tools/inference_engine 有模型推理的定义,inference函数主要做以下三件事:
- 加载参考音频(如果有);
- LLAMA model 进行推理;
- 解码器解码输出音频。
2.3 音色克隆
对于音色克隆而言,有两种方式:
- 如果传入
references:self.load_by_hash会将参考音频和参考文本编码后缓存,方便后续调用; - 如果传入
reference_id:self.load_by_id会在当前目录references文件夹下加载对应参考音频和参考文本。
下面分别给出 Python 端的请求示例代码:
1. 传入reference_id:
def test_tts():
url = 'http://localhost:3003/v1'
text = '2024年12月,随着大军缓缓前进,他忍不住琢磨起了回京之后会被派到什么艰苦的地方顶缸。要知道皇帝一向就是这么干的,几乎没让他过过什么安生日子。'
data = {
"text": text,
"reference_id": "zh-CN-XiaoxiaoNeural",
}
pydantic_data = ServeTTSRequest(**data)
response = requests.post(
f'{url}/tts',
data=ormsgpack.packb(pydantic_data, option=ormsgpack.OPT_SERIALIZE_PYDANTIC),
headers={'Content-Type': 'application/msgpack'}
)
with open("generated_audio.wav", "wb") as audio_file:
audio_file.write(response.content)
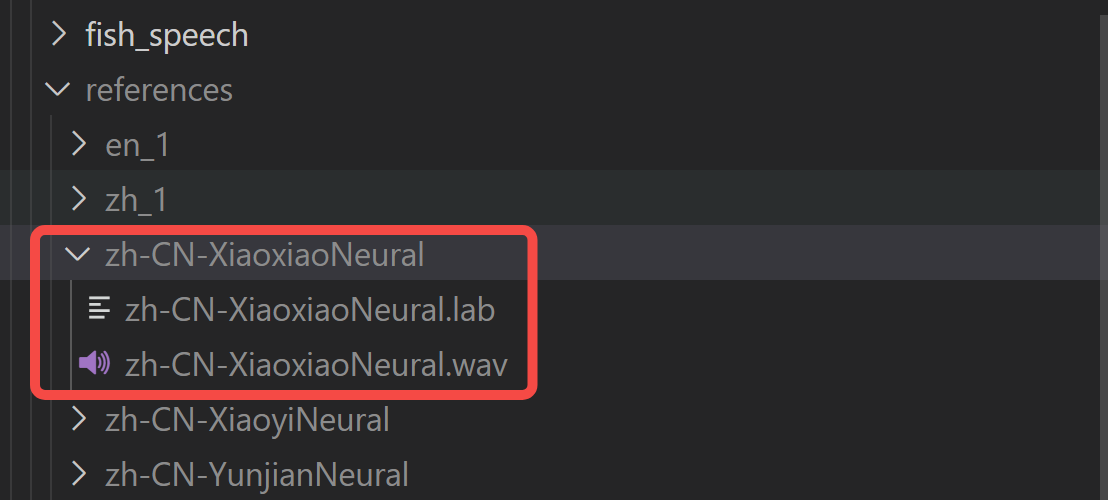
注意:这里需要确保传入的reference_id在当前目录的reference文件夹下有对应的参考音频和参考文本文件,如下图所示:
2. 传入references:
references是一个列表,列表元素定义如下:
class ServeReferenceAudio(BaseModel):
audio: bytes
text: str
因此,音频文件传入的是bytes:
def read_wav(file_path):
with open(file_path, "rb") as wav_file:
wav_content = wav_file.read()
return wav_content
然后,只需参考如下,修改请求参数即可:
data = {
"text": text,
"references":[ServeReferenceAudio(audio=read_wav(f'references/zh_1/zh_1.wav'), text='对,这就是我,万人敬仰的太乙真人。')]
}
2.4 流式输出
fish-speech 是支持流式输出的,只需添加 streaming 参数:
data = {
"text": text,
"reference_id": "zh-CN-XiaoxiaoNeural",
"streaming": True,
}
然后,修改 response 部分代码:
audio_content = b''
for chunk in response.iter_content(chunk_size=1024):
audio_content += chunk
with open("generated_audio.wav", "wb") as audio_file:
audio_file.write(audio_content)
3. 性能实测
3.1 显存占用
服务启动后,模型加载后的显存占用(不加 compile 参数):

服务启动后,模型加载后的显存占用(加 compile 参数):

模型推理时的显存占用情况(不加 compile 参数):

模型推理时的显存占用情况(加 compile 参数):

总结:compile 会将模型中部分函数编译成Torch Script,极大加快了推理速度,同时会带来 2G 显存增加。
下面实测推理速度如何。
3.2 速度测试
还是上方的文本示例,生成音频长度为 13 s。
- 不加 compile 参数,推理耗时 20 s
- 加 compile 参数,推理耗时 2 s
就问这个速度,竞品还有能打的么?
3.3 效果展示
还是上方的文本示例,生成效果如下:
2024年12月,随着大军缓缓前进,他忍不住琢磨起了回京之后会被派到什么艰苦的地方顶缸。要知道皇帝一向就是这么干的,几乎没让他过过什么安生日子。
完美复刻!
前段时间和大家分享过 F5-TTS:49K 下载!最强开源语音克隆TTS:本地部署实测,2秒复刻你的声音
F5-TTS 最大的问题:数字播报搞不定啊!而且耗时约是 fish-speech 的 3 倍!
写在最后
本文和大家分享了一款强大的语音克隆工具:fish-speech,从质量到速度,相比已有开源方案,有了全方位提升。
不知各位体验如何,欢迎评论区聊!
如果对你有帮助,欢迎点赞收藏备用。
为方便大家交流,新建了一个 AI 交流群,公众号后台「联系我」,拉你进群。

















 3397
3397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









