







前段时间,分享了低延迟小智AI服务端搭建的 ASR、LLM 和 TTS 部分:
这三个环节中,成本最高的当属 TTS。
上篇是本地TTS篇的第一篇:
低延迟小智AI服务端搭建-本地TTS篇:fishspeech流式推理
本篇,实测本地部署的 CosyVoice2.0,这也是阿里云上提供的云端 tts 采用的模型。
1. 关于 CosyVoice2.0
本地部署 cosyvoice2.0 并搭建音色克隆服务,笔者之前有分享过:阿里开源 CosyVoice 再升级!支持流式输出,本地部署实测,在此不再赘述。
相比 fishspeech,CosyVoice 可玩性更强,支持可控音频生成 语速调节等等。
不过,我们更关心的是 如何降低推理延时?
2. 加速推理
CosyVoice 官方仓库提供了 tensorrt 的加速方案,只需在模型加载时传参load_trt=True:
# Load model
cosyvoice = CosyVoice2('../pretrained_models/CosyVoice2-0.5B', load_trt=True, fp16=True)
此外,模型每次推理都需要处理参考音频和参考文本,这部分显然可以剥离开,提前处理好,并加入缓存。
为此,可以在 CosyVoice 实例中,新增注册音色的函数:
def register_voice(self, voice_id, voice_text, ref_audio):
st = time.time()
prompt_speech = load_wav(ref_audio, 16000)
prompt_text = self.frontend.text_normalize(voice_text, split=False, text_frontend=True)
output = self.frontend.frontend_prompt(prompt_text, prompt_speech, self.sample_rate)
self.speaker[voice_id] = output
print(f"register voice {voice_id} time: {time.time() - st}")
以注册 11s 的音频为例,需要 1.65s:
register voice zh_female_wanwanxiaohe_moon_bigtts time: 1.656615972518921
下面,一起来看下注册音色带来的加速效果:
- 原始推理:

- 注册音色后:

可以发现,同样一段语音合成,首段音频合成的 rtf 可从 2.8 降到 1.6!
2. 流式推理服务
笔者之前的教程中已提供 fastapi 封装的服务端部署代码:
阿里开源 CosyVoice 再升级!支持流式输出,本地部署实测
这里只需新增注册音色的接口:
@app.post("/register-voice")
async def register_voice(request: TTSRequest):
cosyvoice.register_voice(
voice_id=request.voice_id,
voice_text=request.voice_text,
ref_audio=os.path.join(local_voice_dir, f"{request.voice_id}.wav"),
)
return {"status": "success"}
@app.get("/list-voice")
async def list_voice():
keys = cosyvoice.speaker.keys()
return {"speakers": list(keys)}
为了和云端 TTS 的 API 接口对齐,还需封装一个 webscoket 服务,接收 fastapi 服务输出的音频流,并发送给客户端。
实现思路和上篇一样,不再赘述。
4. 硬件配置和响应延时
服务启动后的显存占用情况:

因为启用了 tensorrt 引擎,显存占用高了一倍,相比上篇的 fishspeech,性价比顿无!
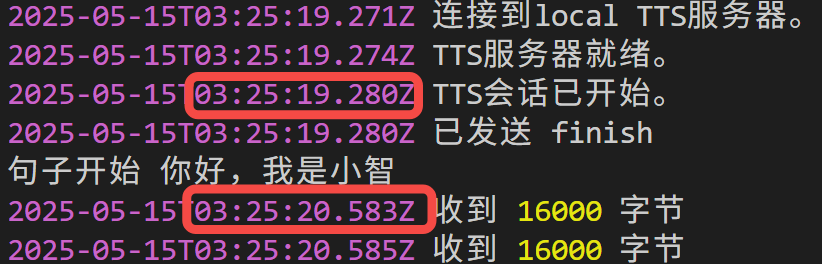
以下是在 RTX 4080 显卡上,流式推理,首个音频包到达客户端的延时情况。
在进行 tensorrt 加速,参考音频编码缓存的情况下,首包延时高达 1.3s:
最后,我们把接收到的 pcm 数据转成 wav,来感受一下音质。
参考音频来自小智火爆出圈的
台湾腔女生-湾湾小何
ffmpeg -f s16le -ar 24000 -ac 1 -i tts.pcm tts.wav
和上篇的 fishspeech 对比下呢:
写在最后
本文分享了小智AI服务端 本地TTS的实现,对cosyvoice的首包延时进行了实测。
如果对你有帮助,欢迎点赞收藏备用。
下篇,继续实测支持流式推理的 TTS 模型。
为方便大家交流,新建了一个 AI 交流群,公众号后台「联系我」,拉你进群。

















 1475
1475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









