







C++虚函数的实现机制
C++中的虚函数的作用主要是实现了多态的机制,多态,简而言之就是用父类型别的指针指向其子类的实例,然后通过父类的指针调用实际子类的成员函数。这种技术可以让父类的指针有“多种形态”,这是一种泛型技术。所谓泛型技术,就是试图使用不变的代码来实现可变的算法。比如:模板技术,RTTI技术,虚函数技术,要么是试图做到在编译时决议,要么试图做到运行时决议。
什么是虚函数?
简单地说,那些被virtual关键字修饰的成员函数,就是虚函数。 基类中声明为虚函数的成员方法,到达子类时仍然是虚函数,即使子类中重新定义基类虚函数时未使用virtual修饰。
虚函数的作用是什么?
虚函数可以让成员函数操作具有一般化,用基类的指针指向不同的派生类的对象时,基类指针调用其虚成员函数,则会调用其真正指向对象的成员函数,而不是基类中定义的成员函数(只要派生类改写了该成员函数)。若不是虚函数,则不管基类指针指向的哪个派生类对象,调用时都会调用基类中定义的那个函数。
虚函数的实现机制?
虚函数(Virtual Function)是通过一张虚函数表(VirtualTable)和虚函数表指针(Virtual Table Pointer)来实现的。简称为vtbl和vptr。一个vtbl通常是一个函数指针数组(一些编译器使用链表来代替数组,但是基本方法都是一样的)在程序中的每个类只要声明(或继承)虚函数的类都有一个 vtbl ,而其中的每一项保存的是该 class 的各个虚函数实现体的指针。
class C1
{
public:
C1();
virtual ~C1();
virtual voidf1();
virtual int f2(char c) const;
virtual void f3(const string& s);
void f4() const;
...
}
C1的Virtual table 看起来如下图:

注意非虚函数 f4 不在表中,而且C1的构造函数也不在。非虚函数(包括构造函数,
它也被定义为非虚函数)就像普通的 C 函数那样被实现。
如果有一个 C2 类继承自 C1,重新定义了它继承的一些虚函数,并加入了它自己的一些虚函数
class C2: public C1
{
public:
C2(); // 非虚函数
virtual ~C2(); //重定义函数
virtual void f1(); //重定义函数
virtual void f5(char *str); // 新的虚函数
...
}
它的 virtual table 每一项指向与对象相适合的函数。 这些项中包括指向没有被 C2 重定义的 C1 虚函数的指针:

基类的虚函数表的创建:
首先在基类声明中找到所有的虚函数,按照其声明顺序,编码0,1,2,3,4……,然后按照此声明顺序为基类创建一个虚函数表,其内容就是指向这些虚函数的函数指针,按照虚函数声明的顺序将这些虚函数的地址填入虚函数表中。
对于子类的虚函数表:
首先将基类的虚函数表复制到该子类的虚函数表中。若子类重写了基类的虚函数,则将子类的虚函数表中存放的函数地址(未重写前存放的是子类的虚函数的函数地址)更新为重写后函数的函数指针。若子类增加了一些虚函数的声明,则将这些虚函数的地址加到该类虚函数表的后面。
为了实现多态的机制,你必须为每个包含虚函数的类的 virtual talbe 留出空间。类的 vtbl 的大小与类中声明的虚函数的数量成正比(包括从基类继承的虚函数)。
对于virtualtable pointer,每个声明了虚函数类的对象都带有它,它是一个看不见的数据成员,指向对应类的virtualtable。这个看不见的数据成员也称为 vptr,被编译器加在对象里,位置只有才编译器知道。从理论上讲,我们可以认为包含有虚函数的对象的布局是这样的:

这幅图片表示vptr 位于对象的底部, 但是不要被它欺骗,不同的编译器放置它的位置也不同。存在继承的情况下,一个对象的vptr 经常被数据成员所包围。
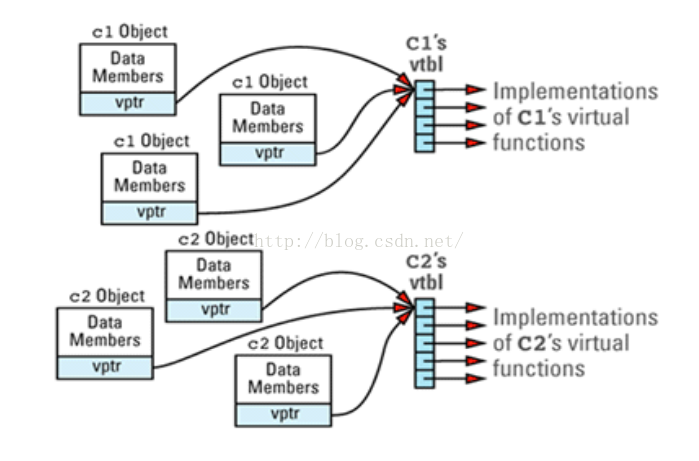
假如我们有一个程序,包含几个 C1 和 C2 对象。 对象、vptr和刚才我们讲述的 vtbl之间的关系,在程序里我们可以这样去想象:
虚函数表是如何访问的?
考虑这段这段程序代码:
void makeACall(C1 *pC1)
{
pC1->f1();
}
通过指针 pC1 调用虚拟函数 f1。仅仅看这段代码,你不会知道它调用的是那一个 f1函数――C1::f1 或 C2::f1,因为pC1 可以指向 C1 对象也可以指向 C2 对象。
编译器生成的代码会做如下这些事情:
通过对象的 vptr 找到类的 vtbl。 这是一个简单的操作, 因为编译器知道在对象内哪里能找到 vptr(毕竟是由编译器放置的它们)。 因此这个代价只是一个偏移调整(以得到vptr)和一个指针的间接寻址(以得到 vtbl)。
找到对应 vtbl 内的指向被调用函数的指针(在上例中是 f1)。 这也是很简单的,因为编译器为每个虚函数在 vtbl 内分配了一个唯一的索引。这一步的代价只是在 vtbl 数组内的一个偏移。
调用第二步找到的的指针所指向的函数。如果我们假设每个对象有一个隐藏的数据叫做 vptr,而且 f1 在 vtbl 中的索引为 i,此语句pC1->f1();
生成的代码就是这样的
(*pC1->vptr[i])(pC1); //调用被 vtbl 中第 i 个单元指向的函数,而
//pC1->vptr指向的是 vtbl;pC1 被做为 this 指针//传递给函数。
虚函数的实现机制付出的代价
不要将虚函数声明为 inline ,因为虚函数是运行时绑定的,而 inline 是编译时展开的,即使你对虚函数使用 inline ,编译器也通常会忽略。
虚函数的第二个成本:必须为每个拥有虚函数的类的对象,付出一个指针的代价,即 vptr ,它是一个隐藏的 data member,用来指向所属类的 vtbl。
调用一个虚函数的成本,基本上和通过一个函数指针调用函数相同,虚函数本身并不构成性能上的瓶颈。
虚函数的第三个成本:事实上等于放弃了 inline。(如果虚函数是通过对象被调用,倒是可以 inline,不过一般都是通过对象的指针或引用调用的)
#include <iostream>
struct B1
{
virtual void fun1(){}
int id;
};
struct B2
{
virtual void fun2(){}
};
struct B3
{
virtual void fun3(){}
};
struct D : virtual B1, virtual B2, virtual B3
{
virtual void fun(){}
void fun1(){}
void fun2(){}
void fun3(){}
};
int main()
{
std::cout<<sizeof(B1)<<std::endl; //8
std::cout<<sizeof(B2)<<std::endl; //4
std::cout<<sizeof(B3)<<std::endl; //4
std::cout<<sizeof(D)<<std::endl; //16
}
//D 中只包含了三个 vptr ,D和B1共享了一个。















 9162
9162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









