







XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。同时它还提供超100个内建函数
https://www.w3school.com.cn/xpath/index.asp
初始化
from lxml import etree
html = etree.HTML(text)
或 html = etree.parse(’./test.html’,etree.HTMLParser())
例:
from lxml import etree
text = '''
<div>
<ul>
<li class="item-0"><a href = "link1.html">first item</a></li>
<li class="item-1"><a href = "link2.html">secomd item</a></li>
<li class="item-inactive"><a href = "link3.html">third item</a></li>
<li class="item-1"><a href = "link4.html">fourth item</a></li>
<li class="item-0"><a href = "link5.html">fifth item</a>
</ul>
</div>
'''
#初始化HTML文本,构造解析
html = etree.HTML(text)
result = etree.tostring(html)
print(type(result))
#将bytes类型结果用decode()方法转成str
print(result.decode('utf-8'))
结果:
<class 'bytes'>
<html><body><div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">secomd item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</li></ul>
</div>
</body></html>
#读取文件进行解析 文件内容为text中的内容
html = etree.parse('./test.html',etree.HTMLParser())
result = etree.tostring(html)
print(result.decode('utf-8'))
结果:略
节点
https://www.w3school.com.cn/xpath/xpath_nodes.asp
节点(Node)
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。XML 文档是被作为节点树来对待的。树的根被称为文档节点或者根节点。
节点关系
父(Parent):每个元素以及属性都有一个父。
子(Children):元素节点可有零个、一个或多个子。
同胞(Sibling):拥有相同的父的节点。
先辈(Ancestor):某节点的父、父的父,等等。
后代(Descendant):某个节点的子,子的子,等等。
##XPath常用规则

所有节点
html = etree.parse('./test.html',etree.HTMLParser())
#所有节点'//'从当前节点选取子孙节点,'/'从当前节点选取子节点,'.'当前节点,'..'当前节点父节点
result =html.xpath('//*')
print(result)
#选取li节点
result = html.xpath('//li')
print(result)
结果:
[<Element html at 0x26e4908>, <Element body at 0x26e4a08>, <Element div at 0x26e4a48>, <Element ul at 0x26e4a88>, <Element li at 0x26e4ac8>, <Element a at 0x26e4b48>, <Element li at 0x26e4b88>, <Element a at 0x26e4bc8>, <Element li at 0x26e4c08>, <Element a at 0x26e4b08>, <Element li at 0x26e4c48>, <Element a at 0x26e4c88>, <Element li at 0x26e4cc8>, <Element a at 0x26e4d08>]
[<Element li at 0x26e4ac8>, <Element li at 0x26e4b88>, <Element li at 0x26e4c08>, <Element li at 0x26e4c48>, <Element li at 0x26e4cc8>]
子节点
#子节点
html = etree.parse('./test.html',etree.HTMLParser())
result = html.xpath('//li/a')
print(result)
result = html.xpath('//li//a')
print(result)
#注意('//ul//a')和('//ul/a')前者可有结果因为ul子孙节点有a,
# 后者无结果,因为ul子节点后没有a节点
result = html.xpath('//ul//a')
print(result)
result = html.xpath('//ul/a')
print(result)
结果:
[<Element a at 0x2e7da08>, <Element a at 0x2e7da48>, <Element a at 0x2e7da88>, <Element a at 0x2e7dac8>, <Element a at 0x2e7db08>]
[<Element a at 0x2e7da08>, <Element a at 0x2e7da48>, <Element a at 0x2e7da88>, <Element a at 0x2e7dac8>, <Element a at 0x2e7db08>]
[<Element a at 0x2e7da08>, <Element a at 0x2e7da48>, <Element a at 0x2e7da88>, <Element a at 0x2e7dac8>, <Element a at 0x2e7db08>]
[]
父节点
#父节点
html = etree.parse('./test.html',etree.HTMLParser())
#..获取父节点
result = html.xpath('//a[@href = "link4.html"]/../@class')
print(result)
#parent获取父节点
result = html.xpath('//a[@href = "link4.html"]/parent::*/@class')
print(result)
结果:
['item-1']
['item-1']
属性值@
# 属性值[@]
html = etree.parse('test.html',etree.HTMLParser())
result = html.xpath('//li[@class="item-0"]')
print(result)
------------------------
[<Element li at 0x2bfba48>, <Element li at 0x2bfba88>]
文本获取
result = html.xpath('//li[@class="item-0"]/text()')
print(result)
result = html.xpath('//li[@class="item-0"]/a/text()')
print(result)
result = html.xpath('//li[@class="item-0"]//text()')
print(result)
-------------------------------------
['\r\n']
['first item', 'fifth item']
['first item', 'fifth item', '\r\n']
属性获取
result = html.xpath('//li/a/@href')
print(result)
-----------------------------------------
['link1.html', 'link2.html', 'link3.html', 'link4.html', 'link5.html']
属性多值匹配
text = '''
<li class="li li-first"><a href="link.html">first item</a></li>
<li class="li li-first"><a href="link2.html">second item</a></li>
'''
html = etree.HTML(text)
result = html.xpath('//li[@class="li"]/a/text()')
print(result)
#contains()函数 第一参数传入属性名称,第二个参数传入属性值
result = html.xpath('//li[contains(@class,"li")]/a/text()')
print(result)
result = html.xpath('//li[contains(@class,"li-first")]/a/text()')
print(result)
result = html.xpath('//a[contains(@href,"link.html")]/text()')
print(result)
-------------------------------
[]
['first item', 'second item']
['first item', 'second item']
['first item']
多属性匹配
text = '''
<li class="li li-first" name="item"><a href="link.html">first item</a></li>
'''
html = etree.HTML(text)
result = html.xpath('//li[contains(@class,"li")and @name="item"]/a/text()')
print(result)
----------------------------
['first item']

按序选择
text = '''
<div>
<ul>
<li class="item-0"><a href = "link1.html">first item</a></li>
<li class="item-1"><a href = "link2.html">secomd item</a></li>
<li class="item-inactive"><a href = "link3.html">third item</a></li>
<li class="item-1"><a href = "link4.html">fourth item</a></li>
<li class="item-0"><a href = "link5.html">fifth item</a>
</ul>
</div>
'''
html = etree.HTML(text)
result = html.xpath('//li/a/text()')
print(result)
result = html.xpath('//li[1]/a/text()')
print(result)
result = html.xpath('//li[last()]/a/text()')
print(result)
result = html.xpath('//li[position()<3]/a/text()')
print(result)
# xpath中有100多种函数
------------------------------------
['first item', 'secomd item', 'third item', 'fourth item', 'fifth item']
['first item']
['fifth item']
['first item', 'secomd item']
xpath函数
https://www.w3school.com.cn/xpath/xpath_functions.asp
节点轴选择(即XPath轴)
text = '''
<div>
<ul>
<li class="item-0"><a href = "link1.html"><span>first item</span></a></li>
<li class="item-1"><a href = "link2.html">secomd item</a></li>
<li class="item-inactive"><a href = "link3.html">third item</a></li>
<li class="item-1"><a href = "link4.html">fourth item</a></li>
<li class="item-0"><a href = "link5.html">fifth item</a>
</ul>
</div>
'''
html = etree.HTML(text)
#ancestor获取li所有祖先节点
result = html.xpath('//li[1]/ancestor::*')
print(result)
#获取div这个祖先节点
result = html.xpath('//li[1]/ancestor::div')
print(result)
#获取li属性值
result = html.xpath('//li[1]/attribute::*')
print(result)
#获取子节点
result = html.xpath('//li[1]/child::a[@href="link1.html"]')
print(result)
#返回span节点
result = html.xpath('//li[1]/descendant::span')
print(result)
#当前节点之后的所有节点
result = html.xpath('//li[1]/following::*')
print(result)
result = html.xpath('//li[1]/following::*[2]')
print(result)
#当前节点之后的同级节点
result = html.xpath('//li[1]/following-sibling::*')
print(result)
------------------------------
[<Element html at 0x2bee988>, <Element body at 0x2bee908>, <Element div at 0x2bee8c8>, <Element ul at 0x2bee9c8>]
[<Element div at 0x2bee8c8>]
['item-0']
[<Element a at 0x2bee908>]
[<Element span at 0x2bee9c8>]
[<Element li at 0x2bee8c8>, <Element a at 0x2bee908>, <Element li at 0x2beea08>, <Element a at 0x2beea48>, <Element li at 0x2beea88>, <Element a at 0x2beeb08>, <Element li at 0x2beeb48>, <Element a at 0x2beeb88>]
[<Element a at 0x2bee908>]
[<Element li at 0x2beeac8>, <Element li at 0x2beea08>, <Element li at 0x2beea48>, <Element li at 0x2beea88>]
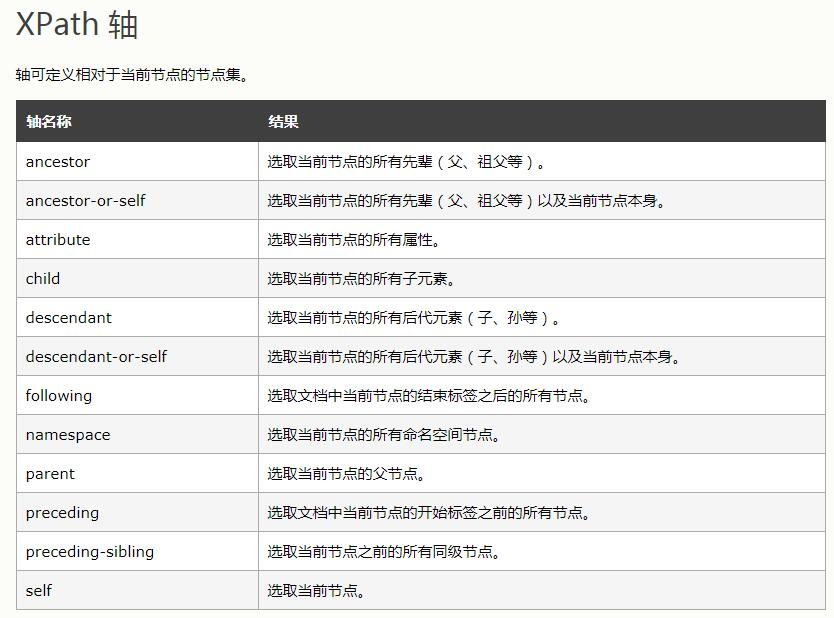
XPath轴
https://www.w3school.com.cn/xpath/xpath_axes.asp
小结:关于xpath:主要掌握节点(所有节点、子节点、父节点、属性值)、轴、函数。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









