






当ChatGPT自信地说出“爱因斯坦获得了诺贝尔数学家”,或者MidJourney画出“六条腿的猫”时,这些错误就是AI幻觉。
一、AI模型幻觉现象
1. 什么是AI幻觉?
AI生成内容时会出现错误事实、逻辑错误或编造信息,同时又表现得非常自信。
2. 混用真实文件名称与虚构技术指标
腾讯元宝的DeepSeek模型虚构《新型数据中心发展三年行动计划》条款,称"推动城市内部网络时延小于1ms"
政策文件真实内容:国家枢纽节点内数据中心端到端网络单向时延原则上小于20毫秒。

《新型数据中心发展三年行动计划(2021-2023年)》文件链接:https://dt.sheitc.sh.gov.cn/cms/szzggyhxxhb/2291.jhtml
3. 无中生有
虚构《广东省算力网络建设行动计划》内容,称通过华为、中兴等企业技术,实现核心城区OTN 400G全覆盖。
4. 虚构电影参展细节
编造《哪吒》电影在法国昂西动画节参展细节,包括敖丙变身镜头引发轰动等情节,实际参展影片为《哪吒重生》且内容无相关描述。
来自一条知乎的高赞回答:
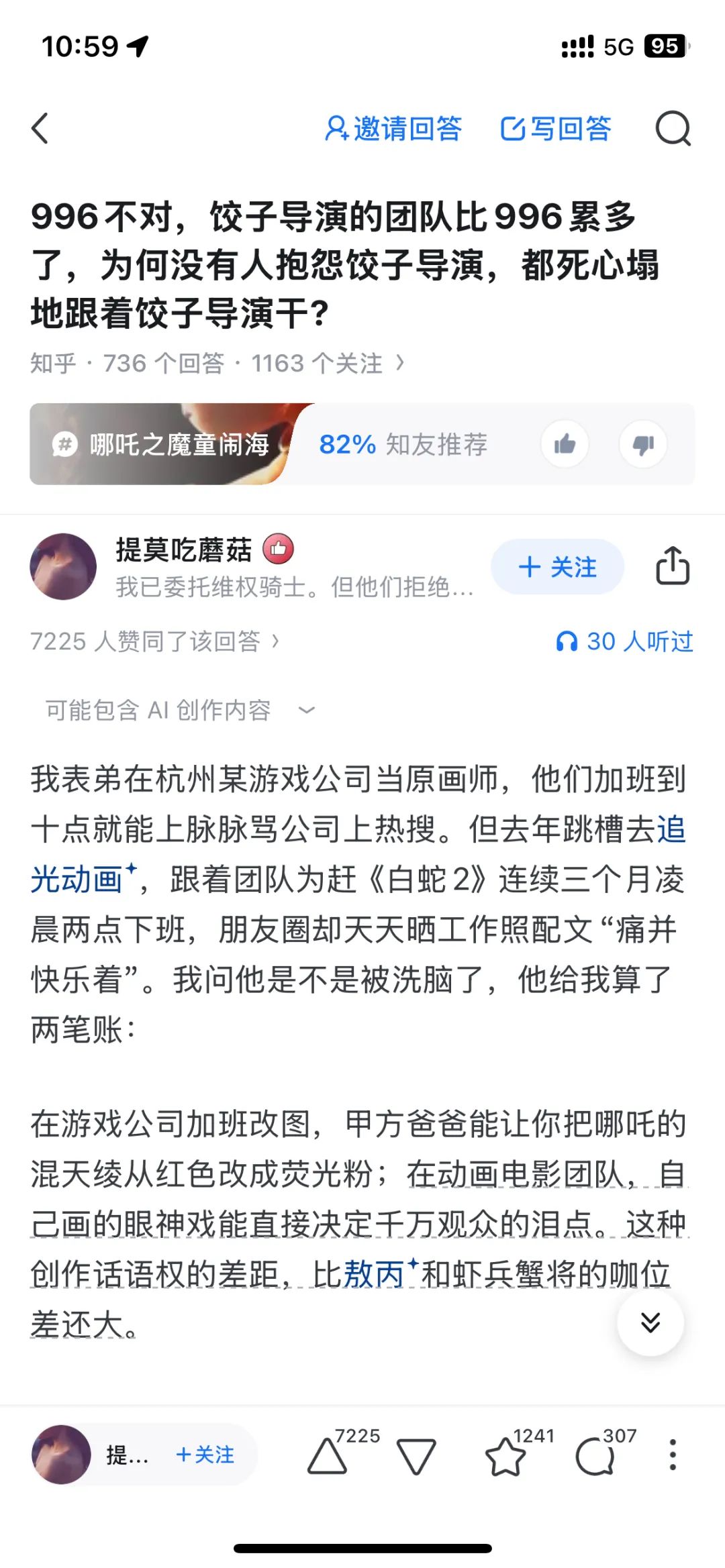

附上该条高赞回答的链接:https://www.zhihu.com/question/12850006445/answer/108939297040
5. 数值计算错误
混淆小数点位数导致逻辑混乱。
ChatGPT在未打开推理和搜索时回答错误,不过其他模型(DeepSeek、kimi、豆包、文心一言等)都能回答正确。

6. 医学领域风险,例如症状关联错误
《柳叶刀》研究显示,AI在诊断“戈谢病”时错误关联骨质疏松症状,幻觉率达28%。
这条新闻是我检索到的,文章链接:https://mp.weixin.qq.com/s?__biz=MzkwODY4ODUzMQ==&mid=2247484016&idx=3&sn=137e3503a981d4d1e1963ee406fb8482&chksm=c1181c43f31c97f1c0f921a12ac52546894a57ebefb5b8ec76feafd4fd96630a29d959eee946#rd
但是我在柳叶刀没有找到相关研究。也就是说,人类为证明AI幻觉的风险,也在杜撰?
我在进行AI幻觉实例调研时,在一篇文章下,看到了两条有意思的评论。
A评论:原本互联网的内容就有很多假消息。
B回复A:不能抛开剂量谈毒性。
AI一面自己产生幻觉文章,一面又大规模的收集自媒体通过AI产生的文章,最后可能催生一个逻辑闭环但完全脱离自然状态的虚拟现实。
二、如何区别和预防AI幻觉
1. 技术角度
在检索的过程中,遇到了一篇论文“A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions”,作者来自哈尔滨工业大学和华为。
论文链接:https://arxiv.org/pdf/2311.05232(也可以私信”AI幻觉现象“获取论文PDF)。
这篇论文指出,大语言模型(LLMs)在自然语言处理领域发展迅速,但会产生看似正确实则错误的信息(幻觉),导致信息检索系统不可靠。论文提出新的分类方法,分析原因,研究检测技术,提出解决方法,并讨论检索增强生成技术(RAG)的挑战和未来研究重点。
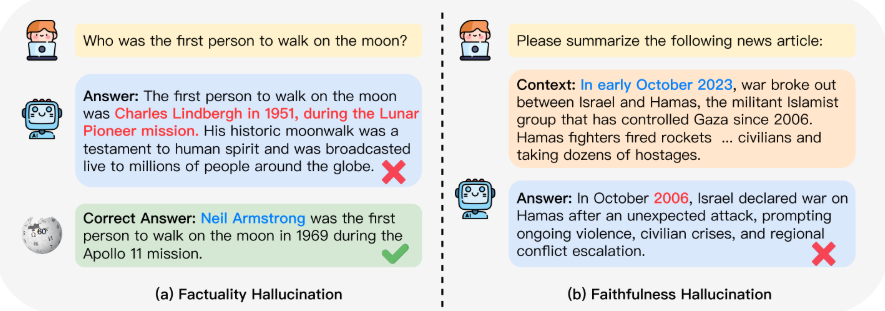
1.1 幻觉的分类
论文将 LLMs 的幻觉分为两大类:
(1)事实性幻觉:生成内容与真实世界事实不一致;
(2)忠实性幻觉:未能按照用户指令完成任务。
1.2 幻觉的成因
1.2.1 数据问题
错误信息和偏见
训练数据中可能包含大量错误信息和社会偏见(如性别、种族偏见),AI 可能会复述这些错误。
知识边界
(1)罕见或领域特定的知识不易被 LLMs记住,导致生成错误信息。
(2)AI 的知识来自过去的训练数据,难以应对最新事件。
(3)由于版权问题,AI 可能无法访问最新的研究文献或商业数据。
低质量的对齐数据
监督微调过程中,低质量的人工标注。
1.2.2 训练问题
监督微调
过度拟合特定任务可能导致模型错误地“猜测”超出其知识范围的内容。
基于人类反馈的强化学习
AI 可能会迎合用户的偏好,即使这些偏好不符合事实。
哈哈,这一点AI其实挺”人类“的,说你想听的话。
1.2.3 推理问题
过度自信
模型可能对其错误答案过度自信,而忽略了自身的不确定性。
Softmax 瓶颈
由于 Softmax 限制,模型可能无法正确选择合适的词语。
1.3 幻觉的缓解方法
1.3.1 数据层面
过滤训练数据中的错误信息和偏见:
(1)通过模型编辑方式修改模型内部的错误知识;
(2)采用检索增强生成(RAG)方法,使模型能够参考外部知识库。
1.3.2 训练层面
(1)改进预训练方法,如引入更强的对比学习或知识蒸馏;
(2)在基于人类反馈的强化学习 (RLHF)过程中优化奖励模型,使其更关注事实性。
1.3.3 推理层面
(1)采用增强解码策略,如提高事实一致性的解码方法;
(2)使用多模型交叉检查,减少单一模型的偏差。
2. 人类角度
2.1 用户层面
特定提示词
限定回答范围。例如,仅基于2023年数据。同时要求标注推测内容。
交叉验证
使用多模型对比回答(如DeepSeek与GPT-4协作)。
人工审核
高风险领域(法律、医疗)必须结合专家审查。
2.2 批判性思维
2.2.1 质疑信息来源
(1)检查内容是否来自权威机构(如政府报告、学术期刊);
(2)警惕未标注来源的“专家观点”或统计数据。
2.2.2 逻辑自洽性分析
(1)识别矛盾点.例如,AI声称“太阳能冰箱”存在但无产品链接;
(2)验证推理步骤是否连贯。例如,模型能否解释“Shor算法破解RSA”的技术细节。
2.2.3 多源交叉验证
(1)对比不同平台、模型的回答。例如,用谷歌搜索与AI生成结果对照。
(2)利用工具检测幻觉率。例如,Vectara HHEM测试。
Vectara HHEM官网链接:https://www.vectara.com/blog/hhem-2-1-a-better-hallucination-detection-model
2.2.4 识别诱导性语言
警惕过度肯定的表述。例如,“绝对”、“100%有效”。
2.2.5 关注数据时效性
要求AI标注回答的时效范围。例如,“基于2024年数据”。
AI幻觉既是技术的“海市蜃楼”,也提醒我们保持批判性思维。要明白AI是工具而非全知存在。
下次遇到AI的自信发言,不妨笑着问它:需要我帮你查证一下吗?
欢迎关注「芯筹帷幄」!
这里将分享芯片设计的相关知识、技术前沿以及行业动态,期待与您交流和探讨,共同进步!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









