






决策树
信息量越大 信息熵越大
信息和消除不确定性是相联系的
决策树的划分依据是信息增益 不确定性
sklearn选择基尼系数作为分类依据,该系数划分更加仔细
class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None,random_state=None)
决策树的结构,本地保存
sklearn.tree.export_graphviz() 该函数能够导出DOT格式 tree.export_graphviz(estimator,out_file='tree.dot’,feature_names=[‘’,’’])
决策树的优点:简单的理解和解释,树木可视化,需要很少的数据准备,其他技术通常需要数据归一化
缺点:决策树过拟合 树的建立太深
改进:剪枝cart算法(决策树API中已经实现
随机森林
集成学习方法-随机森林
集成学习方法通过建立几个模型组合的来解决单一预测问题,生成多个分类器、模型,各自独立地学习和做出预测,这些预测最后结合成单个预测,因此优于任何一个单分类的预测
随机森林是一个包含多个决策树的分类器,并且其输出的类别是有个别树输出的类别的众数而定。
随机森林建立多个决策树的过程:
单个树建立过程(1)随机在N个样本中选择一个,重复N次,样本有可能重复;(2)随机在M个特征当中选择m个特征,
随机有放回的抽样 即bootstrap抽样
随机森林API:class sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’, max_depth=None, bootstrap=True, random_state=None)
随机森林优点:在当前所有算法中,具有极好的准确率;能够有效地运行在大数据集上 ;能够处理具有高维特征的输入样本,而且不需要降维 ;能够评估各个特征在分类问题上的重要性 ;对于缺省值问题也能够获得很好得结果
K近邻算法
求距离 如果一个样本在特征空间中k个最相似(即特征空间中最接近)的样本中的大多数属于某一个类别,则该样本也属于这个类别
欧氏距离
sklearn.neighbors.KNeighborsClassifier
k取值 1,3,5
k值取很小:容易受异常点影响 k值取很大:容易受最近数据太多导致比例变化
k近邻算法不需要训练,不需要调参,设定K这个超参数即可
k近邻算法是懒惰算法,对测试样本分类时的计算量大,内存开销大
必须指定K值,k值选择不当则分类精度不能保证
使用场景:小数据场景,几千~几万样本,具体场景具体业务 去测试
朴素贝叶斯
联合概率:包含多个条件,且所有条件同时成立的概率 记作:P(A,B)
条件概率:就是事件A在另外一个事件B已经发生条件下的发生概率 记作:P(A|B) 特性:P(A1,A2|B) = P(A1|B)P(A2|B) 注意:此条件概率的成立,是由于A1,A2相互独立的结果
贝叶斯公式
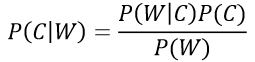
注:w为给定文档的特征值(频数统计,预测文档提供),c为文档类别
公式可以理解为: P(C│F1,F2,…)=P(F1,F2,… │C)P©/P(F1,F2,…) 其中c可以是不同类别
公式分为三个部分:
P©:每个文档类别的概率(某文档类别词数/总文档词数) P(W│C):给定类别下特征(被预测文档中出现的词)的概率
计算方法:P(F1│C)=Ni/N (训练文档中去计算) Ni为该F1词在C类别所有文档中出现的次数 N为所属类别C下的文档所有词出现的次数和
P(F1,F2,…) 预测文档中每个词的概率
拉普拉斯平滑
P(F1│C)=Ni+α/N+αm
α为指定的系数一般为1,m为训练文档中统计出的特征词个数
sklearn.naive_bayes.MultinomialNB(alpha=1.0)
没有超参数可以调整的 训练数据集如果质量不好,则分类效果不好
优点: 朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。 对缺失数据不太敏感,算法也比较简单,常用于文本分类。 分类准确度高,速度快
缺点: 需要知道先验概率P(F1,F2,…|C),因此在某些时候会由于假设的先验 模型的原因导致预测效果不佳。
分类模型的评估
在分类任务下,预测结果(Predicted Condition)与正确标记(True Condition)之间存在四种不同的组合,构成混淆矩阵(适用于多分类)

精确率:预测结果为正例样本中真实为正例的比例(查得准)
召回率:真实为正例的样本中预测结果为正例的比例(查的全,对正样本的区分能力)
其他分类标准,F1-score,反映了模型的稳健型
sklearn.metrics.classification_report(y_true, y_pred, target_names=None)
y_true:真实目标值 y_pred:估计器预测目标值 target_names:目标类别名称 return:每个类别精确率与召回率
模型的选择与调优
(1)交叉验证
数据分为训练集和验证集
将所有数据n等分,每一个等分交替做验证集 得出一个准确率得到一个模型, 求每个模型准确率的平均值
n折交叉验证
(2)网格搜索
通常情况下,有很多参数是需要手动指定的(如k-近邻算法中的K值), 这种叫超参数。但是手动过程繁杂,所以需要对模型预设几种超参数组 合。每组超参数都采用交叉验证来进行评估。最后选出最优参数组合建 立模型。
sklearn.model_selection.GridSearchCV(estimator, param_grid=None,cv=None)
estimator:估计器对象 param_grid:估计器参数(dict){“n_neighbors”:[1,3,5]} cv:指定几折交叉验证














 5989
5989











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









