







xgboost算法原理
1.xgboost的介绍
xgboost的全称(extreme gradient boosting)极限梯度提升,经常被用在一些比赛中,其效果显著。它是大规模并行boosted tree 的工具,是目前最快最好的开源Boosted tree工具包。xgboost所应用的算法是gbdt(gradient boosting decision tree)的改进,既可以用于分类也可以用于回归问题中。
2.回归树和决策树的区别
事实上,分类和回归是一类东西,只不过分类的结果是离散值,回归是连续值,本质是一样的,都是特征到label之间的映射。决策树使用的是信息增益、信息增益率、基尼系数来判断树节点的分类点,但是回归树采用新的方式:预测误差,常用的有均方误差、对数误差等。而且节点不再是类别,而是数值,那么怎么确定节点的值呢?有的是节点内部样本的均值,有的是最优化计算出来的,比如xgboost。
3.boosting集成学习
boosting集成学习,由多个相关联的决策树联合决策,什么是相关联,举个例子,有一个样本是[(2,4,5)–>4],第一颗决策树用这个样本训练得到的预测值是3.3,那么第二颗决策树训练时的输入就变成了[(2,4,5)–>0.7],也就是说,下一棵决策树输入的样本会跟前面决策树的训练和预测相关。或者当前的决策树会去拟合上一棵决策树的预测结果跟目标lable之间的残差
与之对比的是随机森林,各个决策树是独立的、每个决策树在样本堆里随机选一批样本,随机选一批特征进行独立训练,各个决策树之间没有啥关系。
所以xgboost首先是一个boosting的集成学习,这样应该很通俗了
这个时候大家可能就能感觉到一个回归树形成的关键点:1) 分裂点依据什么来划分(如前面说的均方误差loss最小, 或者划分前后信息增益最大);2)分类后的节点预测值是多少(如前面所说,一种是将叶子节点中各个样本实际值的均值作为叶子节点预测值,或者计算所得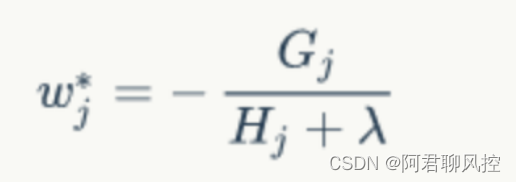
)
4.集成学习
在学习xgboost之前,我们需要了解集成思想。集成学习方法是指将多个学习模型组合,以获得最好的效果,使得组合后模型具有更强的泛化能力。另外xgboost是以分类回归树(cart树)进行组合的。故在此之前,我们先看下cart树:输入用户年龄、性别来判断用户是否喜欢玩游戏的的分值。由此,得到一棵cart树模型如下:

我们知道对于单个决策树模型很容易过拟合,并且不能在实际中有效应用。所以出现了集成学习。如下图,通过两颗树组合进行玩游戏得分值预测。其中tree1中队小男生的预测值为2,tree2中对于小男生的预测值是0.9。则该小男生的最后得分值为2.9.

以上集成学习推广到一般情况,其预测模型为:
yi = f1+f2+f3+…+fi (i为树的总数,fi表示第i棵树,yi表示样本的预测结果)
损失函数为; obj= l(y’0, y0)+l(y’1,y1)+…+l(y’n,yn)+正则(y‘0)+正则(y’1)+…+正则(y’n)
5.xgboost算法思路
首先明确下我们的目标,希望建立K个回归树,使得树群的预测值尽量接近真实值(准确率高),而且有尽量搞得泛化能力,从数学的角度看这是一个泛函最优化,多目标,看目标函数:



目标函数分经验风险和结构风险
经验风险:让模型尽可能的拟合训练数据,模型的准确率较高,衡量模型拟合训练数据的好坏程度;经验风险越小越好,模型的准确率越高;
结构风险:让模型尽可能的简单,参数尽可能少,简单的模型在测试数据集上的预测结果比较稳定,模型的泛化能力较好,尽量避免过拟合;结构风险描述树的复杂度的函数,越小复杂度越低,模型的泛化能力越强
从直观上看,目标要求预测误差尽量小(经验风险尽量小),叶子节点尽量少,节点数值尽量不极端(结构风险尽量小)
那么如何实现上述的目标呢?先说答案:贪心算法+最优化(二次优化)
通俗的讲贪心策略就是: 决策树时刻按照当前目标最优化决定,即眼前利益最大化决定。怎么用贪心策略呢?刚开始你有一群样本,放在第一个节点,这时候T=1,如果这里的l(w-yi)误差表示平方误差,那么上述函数就是关于w的二次函数求最小值,取最小值的点就是这个节点的预测值,最小的函数值为最小损失函数。
如果损失函数不是二次函数怎么办?哦,泰勒展开,不是二次的近似为二次。
如何建树呢?
那么需要解决2个问题:1)确定分裂用的feature,how? 最简单粗暴的是枚举,选择loss function 效果最好的那个特征 2)如何确立节点的w
a) 计算每个特征的最佳分裂点,方法:将该特征对应的样本值排序,分别计算每个特征值分裂后的增益值,将增益值最大的样本点作为该特征分裂点
b) 计算所有特征的分裂最佳增益值,选择增益值最大的特征作为要分裂的特征,划分样本为左右子树
c) 不断迭代第1)和2)步,直到达到的特定的阈值,树的划分结束,至此生成了一颗新的决策树
d) 根据第3)步的划分结果,计算每个叶子结点对应的预测值
e)把新生成的决策树添加到模型
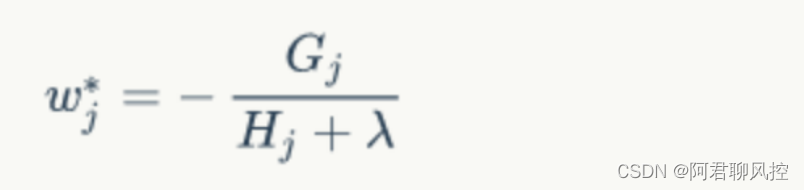
什么时候停止建树呢?
1)当引入的分列带来的增益小于一个阈值时,我们可以剪掉这个分裂,所以并不是每一次分裂loss function整体都会增加的,有的预测剪枝的意思,阈值参数为y 正则项中叶子节点树T的系数
2)当数达到最大深度的时候,则停止建立决策树,设置一个超参数max_depth ,树太深容易过拟合
- 当样本权重和小于设定阈值时,则停止建树,即超参数 min_child_weight, 大概意思是 一个叶子节点的样本太少,则终止同样是防止过拟合
那么节点分裂的时候是按照什么顺序来的,比如第一次分裂后有连个叶子节点,先分裂哪个?答:同一层级的(多级)并行,确定如何分裂或者不分裂成为叶子节点
xgboost算法是加法模型:每次往模型中加入一棵树,其损失函数便会发生变化。另外在加入第t棵树时,则前面第t-1棵树已经训练完成,此时前面t-1 棵树的正则项和训练误差都已成为常数项。对于每棵树的正则部分,我们将在后面细说。
6.总结
1)决策树叶子节点的预测值w是最优化求出来的,不是啥平均值或者规则指定的,这算是一个思路上的创新吧
2)正则化时防止过拟合的技术
3)支持自定义损失函数,只要能够进行泰勒展开(能求一阶导数和二阶导数)就行
4)支持并行化,这是xgboost的闪光点,boosting技术中下一颗树依赖上一颗树的训练和预测,所以树与树之间只能串行!但是,在选择最佳分裂点时,进行枚举的时候可以并行(据说这个时候也是树形成最耗时的阶段),即同级节点可并行
5)对连续值特征的分裂点的选择:当feature是离散值时分割点倒是很简单,比如“是否单身”来分裂节点计算增益很easy,但是月收入这种feature,取值很多,从5k-50k都有,总不可能每个分割点都试一下计算分裂增益吧?一是计算量,二是:出现叶子节点过少,过拟合。我们的常用习惯是划分区间(分桶),那么如何分桶呢?可以时等频分桶(每个桶内的样本数大致相同),也可以是等宽分桶(每个桶内的特征值相同),作者使用的是等频分桶,即共划分m个桶,每个桶内的样本树是:总样本树/m。
6)对缺失值的处理,当样本的第i个特征缺失时,无法利用该特征对样本进行划分,这里的做法是将该样本默认划分到指定的子节点,至于具体划分到哪个节点需要某算法来计算
算法的主要思想是,分别假设特征的缺失样本属于右子树和左子树,并且只在不缺失的样本上迭代,分别计算缺失样本属于右子树和左子树的增益,选择增益最大的方向为缺失数据的默认方向
7)可实现后剪枝
8)交叉验证,方便选择最好的参数,如果比发现30棵树预测已经很好了,不用进一步学习残差了,那么停止建树
9)行采样和列采样,随机森林的套路(防止过拟合)
10)shrinkage,你可以是几个回归树的叶子节点之和为预测值,也可以是加权值,比如第一棵树的预测值是3.3,label为4.0,第二棵树才学0.7 。。。再后面的树还学个鬼,所以给他打个折扣,比如3折,那么第二颗树训练的残差为4.0-3.3*0.3=3.01,作用是防止过拟合,有点像梯度下降中的学习率
11)该支持设置样本的权重,这个权重体现在梯度g和二阶梯度h上
12)跟深度学习对比下:
xgboost的第一感觉就是防止过拟合+各种支持分布式/并行,所以一般传言这种大杀器效果好(集成学习的高配)+训练效率高(分布式),与深度学习相比,对样本量和特征数据类型要求没那么苛刻,适用范围广。
深度神经网络通过对时空位置建模,能够很好的捕获图形、语音、文本等高维数据。而基于树模型的香港boost则能够很好地处理表格数据,同时还拥有一些深度神经网络所没有的特性(如:模型的可解释性、输入数据的不变性、更易于调参等)。














 3375
3375











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









