







一、ptmalloc
1.1 特点
- 使用空闲链表bins管理用户free掉的内存作为下次使用,而不是直接还给os,可避免频繁的系统调用,降低内存分配的开销;
- 若分配区锁竞争激烈,会导致非主分区快速增长,当非主分区数量达到阈值之后,会因为无法分配新的非主分区而导致线程阻塞,从而影响ptmalloc的效率;
- 先申请的内存先释放会导致内存无法收缩。这是因为ptmalloc的内存收缩是从Top chunk开始的,若Top chunk相邻的内存未释放,则Top chunk以下的所有内存都不能释放,从而导致内存泄漏;
- 申请/释放内存都需要加锁。
1.2 操作系统内存布局
linux 32位操作系统:
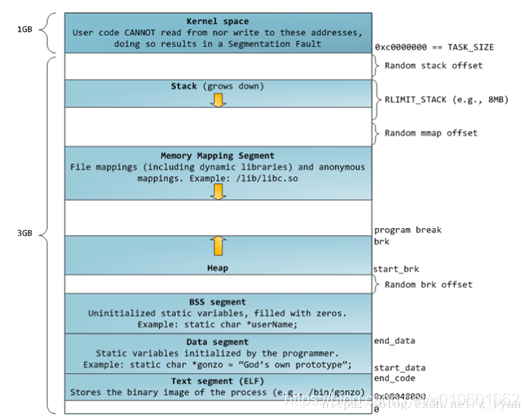
- heap从低地址向高地址扩展,与mmap相对扩展,直至耗尽虚拟地址空间中的剩余区域;
- offset:随机偏移量,避免通过缓冲区溢出进行攻击;
- 应用程序所使用的主要是heap/mmap,前者通过sbrk->brk进行申请,后者通过mmap/unmmap将一个文件映射进内存;
1.3 malloc原理
由于brk/mmap属于系统调用,若每次都使用它们申请内存,则每次都会产生系统调用,影响性能;其次,由于堆是从低地址到高地址扩展的数据结构,若高地址内存未释放,则低地址内存即使已被释放也无法回收,故这种申请方式容易产生内存碎片。
基于这种原因,malloc采用内存池的管理方式(ptmalloc),ptmalloc 采用边界标记法将内存划分成很多块,从而对内存的分配与回收进行管理。为了保证内存分配的高效性,ptmalloc会预先向操作系统申请一块内存,当申请/释放内存时,ptmalloc会将这些内存管理起来,并通过一些策略来判断是否将其回收给操作系统。这样做的最大好处就是,使内存的申请/释放更为高效,避免产生过多的内存碎片。
1.4 主分配区/非主分配区
旧版本的ptmalloc只有一个主分配区,而线程在分配/释放内存时都需要对主分配区加锁,因此对多线程不友好。改进后的ptmalloc由一个主分配区和若干个非主分配区构成,它们通过一个环形链表进行管理。
- 非主分配区只增不减;
- 分配内存时,需要遍历环形链表,找到一个未被任何线程锁定的非分配区。若存在这样一个分配区,则锁定,否则新增一个非主分配区,插入环形链表并锁定;
- 主分配区与非主分配区的区别:主分配区可以通过sbrk/mmap分配内存,非主分配区只能通过mmap分配内存;
1.5 chunk
ptmalloc中分配/释放的内存都被表示成chunk。chunk按结构可分为使用中和空闲两种类型。
使用中的chunk:
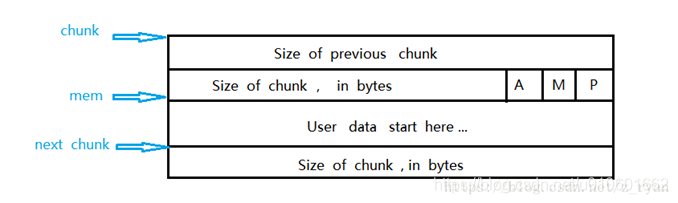
说明:
- chunk指针:指向chunk的开始地址;mem指针:指向用户内存块的开始地址;
- A:主分区/非主分区标识符,0:主分配区分配,1:非主分配区分配;
- M:0:heap区域分配,1:mmap映射区域分配;
- P:前一个chunk的状态, 0:前一个chunk为空闲(此时prev_size有效), 1:前一个chunk正在使用(此时prev_size无效)。ptmalloc 分配的第一个块总是将P置为1, 以防止程序引用不存在的chunk区域。
- P主要用于内存块的合并操作。
空闲的chunk:

说明:
- 空闲的chunk只有AP状态,无M状态;
- 原本是用户数据区的地方存储了四个指针:
1)fd/bk:分别指向后/前一个空闲chunk。malloc通过这两个指针将大小相近的chunk连成一个双向链表;
2)fd_nextsize/bk_nextsize:存在于large bin中,用于加快在large bin中查找最近匹配的空闲chunk。不同的chunk链表又是通过bins或者fastbins来组织的。
1.6 空闲链表bins
用户free掉的内存,ptmalloc并不会马上还给os,而是用空闲链表bins管理起来了,这样当下次malloc一块内存时,ptmalloc会直接从bins上寻找一块合适大小的内存块分配给用户使用。这样的好处可以避免频繁的系统调用,降低内存分配的开销。
ptmalloc按chunk的大小将bins分成四类:fast/unsorted/small/large bins。
- fast bins:
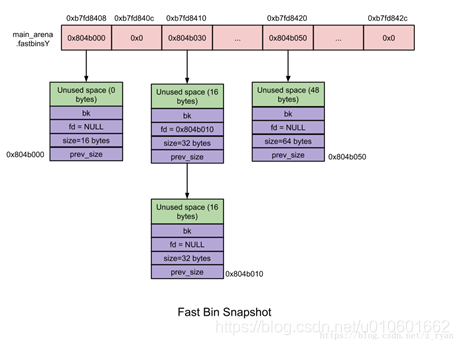
unsorted/small/large bins的高速缓冲区,大约有10个定长队列。每个fast bin都存储着一条空闲chunk的单链表,增删chunk都发生在链表的前端。
当用户释放一块不大于max_fast(默认值64B)的chunk时,会默认会被放到fast bins上。当需要给用户分配的 chunk <= max_fast时,malloc首先会到fast bins上寻找是否有合适的chunk。
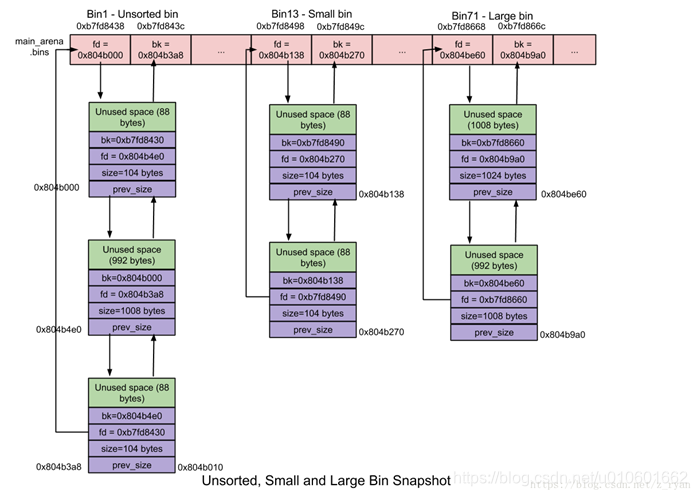
- unsorted bins:
bins 数组的第一个元素,用于加快分配速度。当用户释放的内存大于max_fast或fast bins合并后的chunk都会首先插入unsorted bin中; - small bins:
小于512字节的chunk称为small chunk,而保存small chunks的bin被称为small bin。small bin存储在bins数组第2个至第65个位置,前后两个bin相差8个字节,同一个bin中的chunk大小相同。 - large bins:
大于等于512字节的chunk称为large chunk,而保存large chunks的bin被称为large bin。large bin位于small bins后面。每一个large bin包含了给定范围内的chunk,large bin内的chunk按先大小后最近使用时间递减排序。
并不是所有chunk都按以上四种方式进行组织,以下两种情况例外:
- Top chunk:
分配区的顶部空闲内存,当所有的bins上都不能满足内存分配要求时,就会使用top chunk进行分配。
若Top chunk的大小大于用户请求的内存大小时,则分割top chunk成两部分:User chunk(用户请求大小)和Remainder chunk(剩余大小)。其中Remainder chunk将成为新的Top chunk;
当Top chunk的大小小于用户请求的内存大小时,则通过sbrk(main arena)或mmap(thread arena)系统调用来扩容Top chunk。 - mmaped chunk:
当用户请求的内存非常大(大于分配阀值,默认128K)时,需被mmap映射,则会放到mmaped chunk上,当释放mmaped chunk上的内存的时候会直接还给os。
1.7 内存分配
- 锁定一个分配区,防止多线程冲突;
- 将用户请求分配的内存大小向上取整到class_size;
- 若class_size < max_fast(64B),则检查fast bins是否存在适合的chunk。存在则分配结束,否则继续;
- 运行到此步,说明fast bins上未有合适的chunk或class_size > 64B且class_size<512B,则检查small bins是否存在合适的chunk。存在则分配结束,否则继续;
- 遍历fast bins,将相邻的chunk合并后链接到unsorted bin中。
若unsorted bins中只有一个chunk且大于class_size,则切割并将剩余chunk重新放回unsorted bins;
若unsorted bins中有class_size大小的chunk,则从unsorted bins删除并返回;
若unsorted bins中的chunk属于small bins的范围,则插入small bins的头部;
若unsorted bins中的chunk属于large bins的范围,则插入large bins。 - 运行到此步&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7806
7806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









