










查看keras模型结构
from tensorflow import keras
# 查看模型层及参数
deepxi.model.summary()
# 将模型结构保存为图片
model_img_name = args.ver + '-' + args.network_type + '.png'
keras.utils.plot_model(deepxi.model, model_img_name, show_shapes=True)
示例:
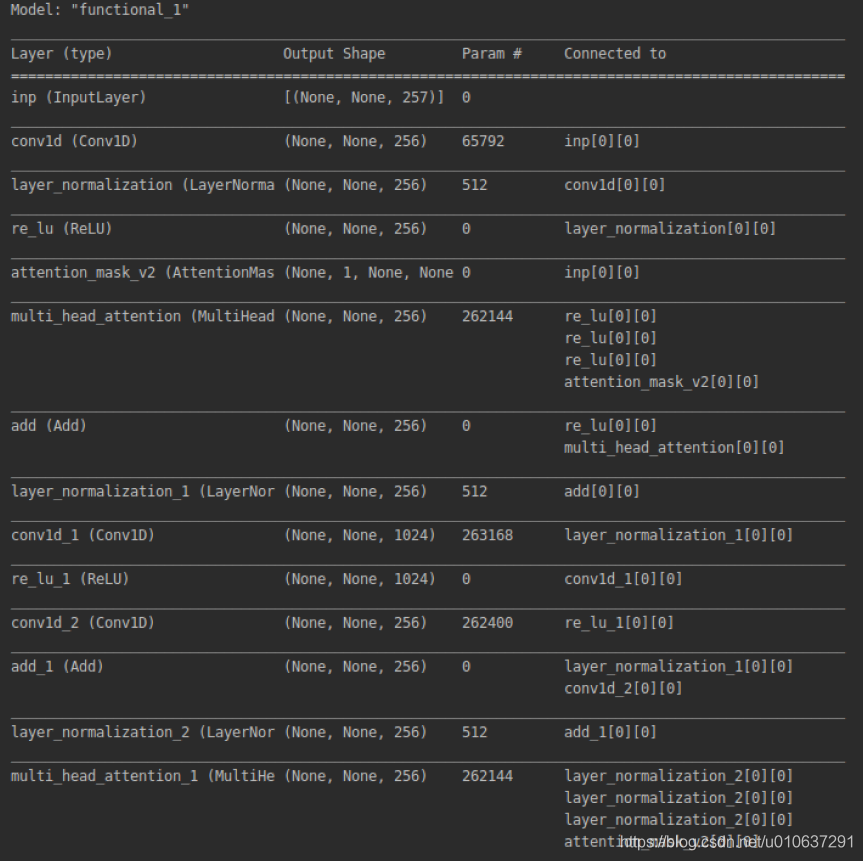
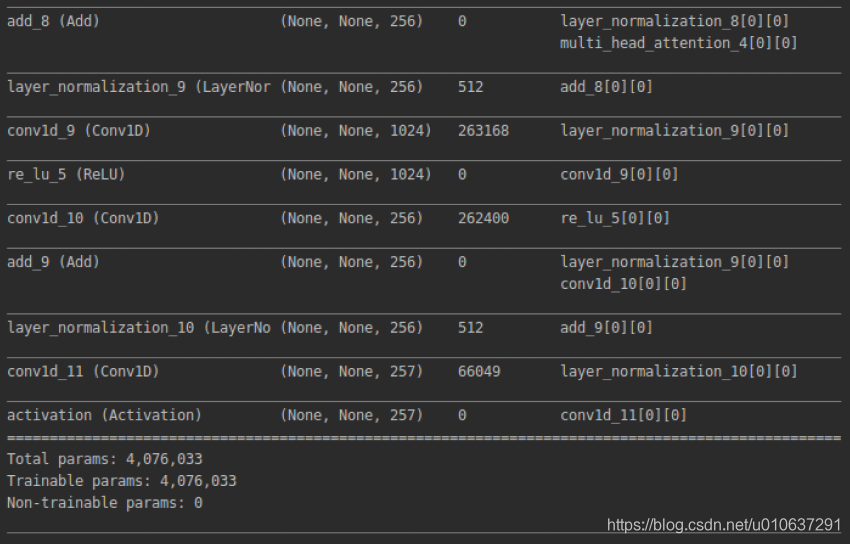
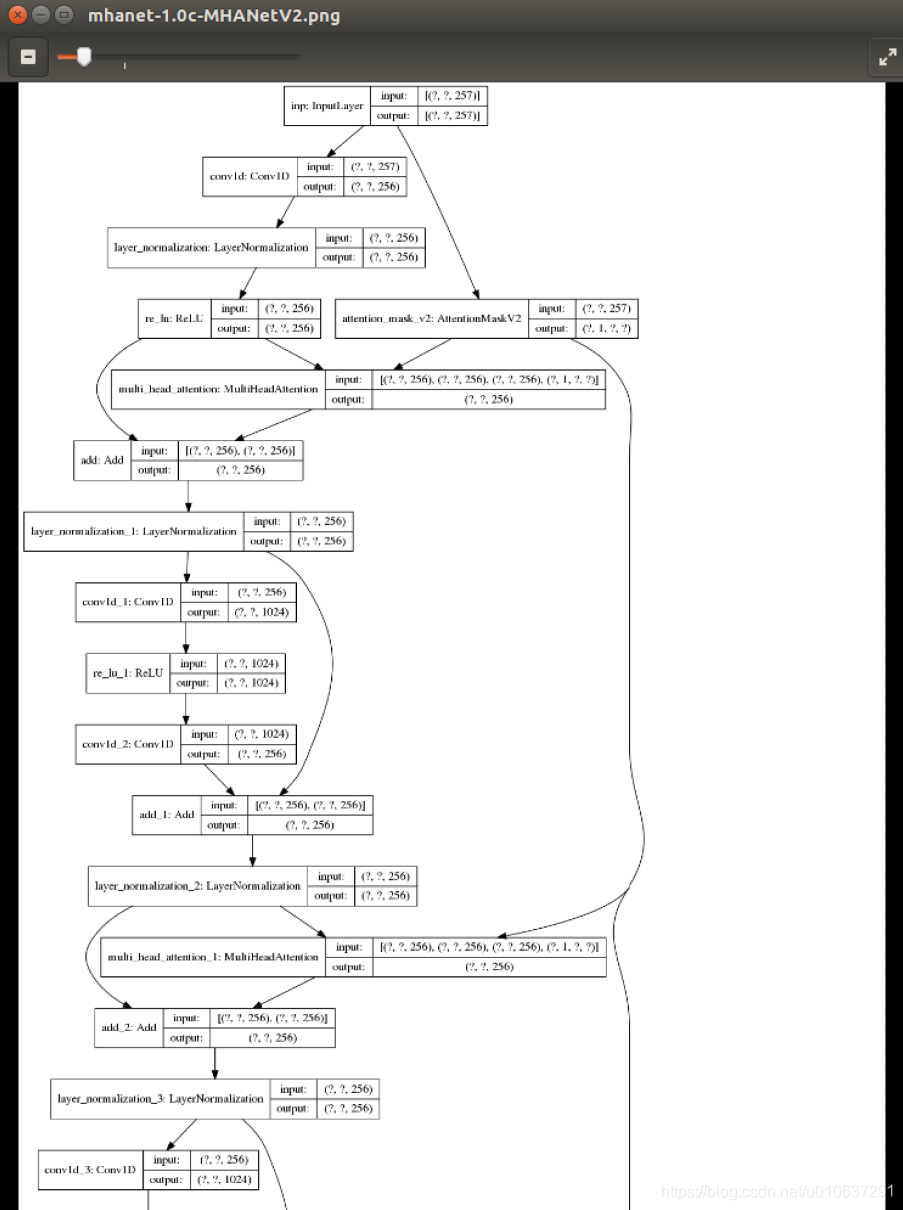
查看keras模型参数
可参考:【模型参数】tensorflow1.x (slim) 和tensorflow2.x (keras) 的查看模型参数方式:https://blog.csdn.net/u010637291/article/details/108143002
# 给定keras模型,如deepxi.model, deepxi模型可参考: https://github.com/anicolson/DeepXi
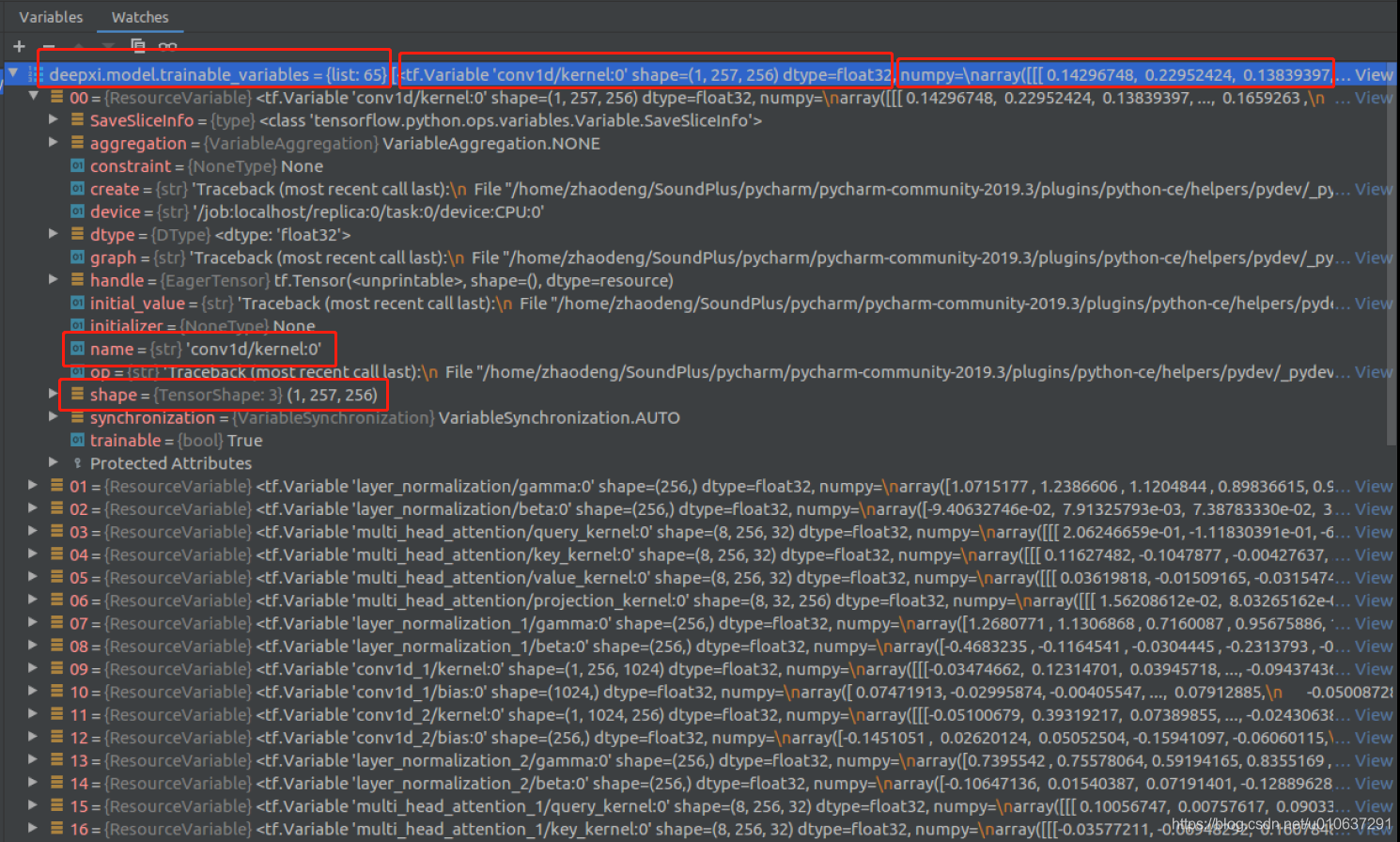
# 查看模型可训练参数
for v in deepxi.model.trainable_variables:
print(str(v.name) + ', ' + str(v.shape)) # 变量名+变量shape
print(str(v.value)) # 变量值
# 查看所有参数:
model_variables = deepxi.model.variables
for v in model_variables:
print(str(v.name) + ', ' + str(v.shape))
示例:在watch窗口查看deepxi.model.trainable_variables,可查看到共有65个变量,每一个变量的名字、shape和值均可查看:
查看keras模型每层输入/输出
查看模型每层输出:
def print_layer_output(deepxi):
from tensorflow.keras import backend as K
inp = deepxi.model.input # input
outputs = [layer.output for layer in deepxi.model.layers] # all layer outputs
functors = [K.function([inp], [out]) for out in outputs] # evaluation functions
# Testing with a wav file
test_x, test_x_len, _, test_x_base_names = Batch('../deepxi_dataset/deepxi_test_set/test_noisy_speech_1')
print("Processing observations...")
inp_batch, supplementary_batch, n_frames = deepxi.observation_batch(test_x, test_x_len)
# 模型每一层输出
layer_outs = [func([inp_batch, 1.]) for func in functors]
# Writing to a file
output = open('layer_output.txt', 'w+')
for i in range(len(layer_outs)): #
for j in range(len(layer_outs[i][0][0])):
for k in range(len(layer_outs[i][0][0][j])):
# print(layer_outs[i][0][0][j][k], end='\t')
output.write(str(layer_outs[i][0][0][j][k]) + ' ')
# print()
output.write('\n')
# print()
# print()
output.write('\n')
output.write('\n')
print('done')
return layer_outs
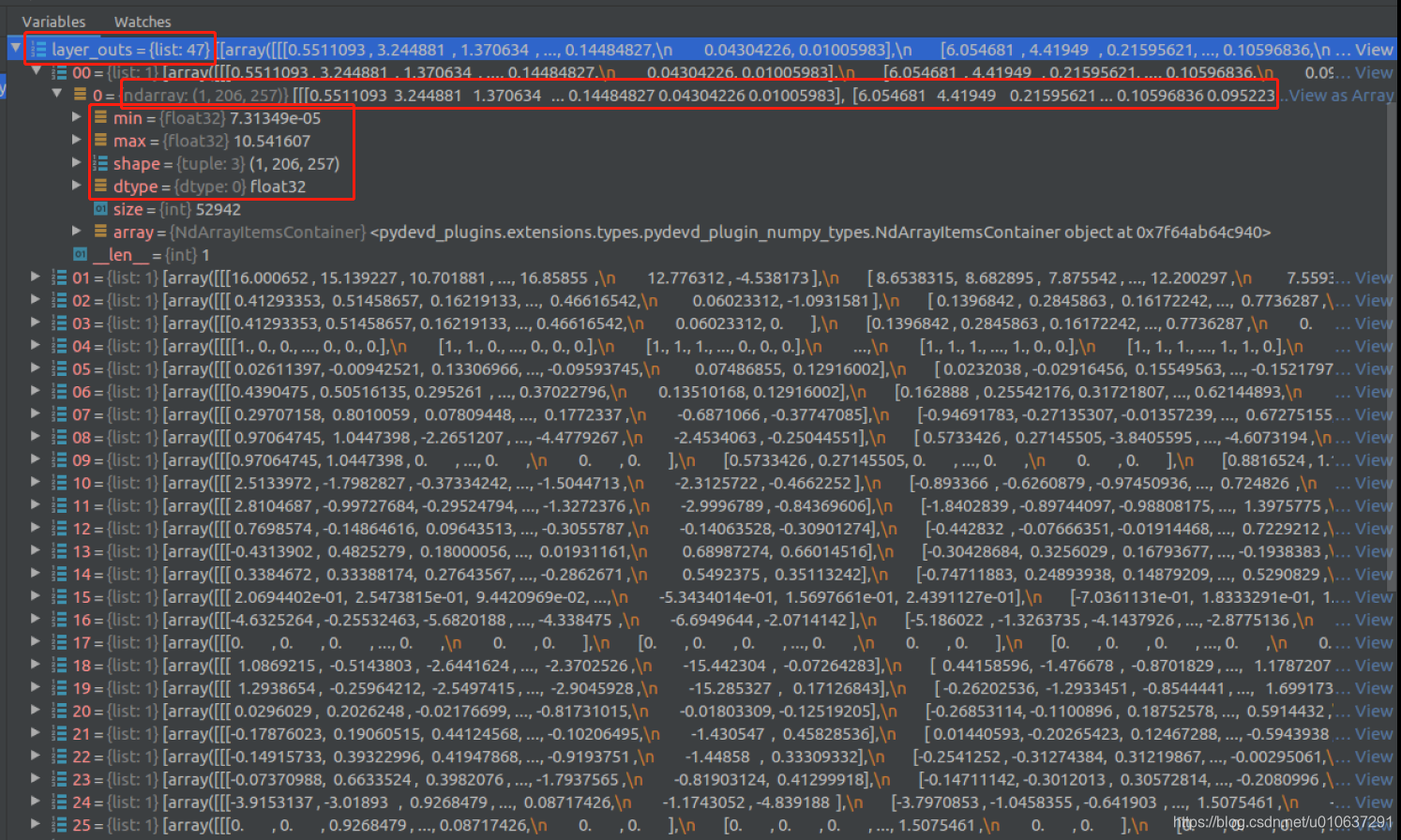
示例:layer_outs:可查看共有47层,每层的参数值、最大最小值及dtype等均可查看
在此,完成的操作有:
1)针对某一个wav文件,模型的每层输出;
2)针对一个dataset,模型的每层输出。
def print_layer_output_4wav(deepxi, wavfile = '../deepxi_dataset/deepxi_test_set/test_noisy_speech_1/6930-81414-0003_SIGNAL021_0dB.wav'):
'''
Generating outputs of all layers
@param deepxi: our pretrained deepxi
@param wavfile: a certain wav file with its dir and name.
@return:
'''
from tensorflow.keras import backend as K
from deepxi.utils import read_wav
import numpy as np
input = deepxi.model.input # input
outputs = [layer.output for layer in deepxi.model.layers] # all layer outputs
functors = [K.function([input], [output]) for output in outputs] # evaluation functions
# Reading the wav file
(wav, _fs) = read_wav(wavfile)
# Observing
inp, _supplementary = deepxi.inp_tgt.observation(wav)
# Batching
n_frames = deepxi.inp_tgt.n_frames(len(wav))
inp_batch = np.zeros([1, n_frames, deepxi.inp_tgt.n_feat], np.float32)
inp_batch[0, :n_frames, :] = inp
# outputs of all layers
layer_outs = [func([inp_batch, 1.]) for func in functors]
return layer_outs
def generate_train_dataset(deepxi):
from deepxi import utils
import math
from deepxi.args import get_args
args = get_args()
if args.set_path != "set":
args.data_path = args.data_path + '/' + args.set_path.rsplit('/', 1)[-1] # data path.
train_s_path = args.set_path + '/train_clean_speech' # path to the clean speech training set.
train_d_path = args.set_path + '/train_noise' # path to the noise training set.
train_s_list = utils.batch_list(train_s_path, 'clean_speech', args.data_path)
train_d_list = utils.batch_list(train_d_path, 'noise', args.data_path)
deepxi.train_s_list = train_s_list
deepxi.train_d_list = train_d_list
deepxi.mbatch_size = args.mbatch_size
deepxi.n_examples = len(train_s_list)
deepxi.n_iter = math.ceil(deepxi.n_examples / deepxi.mbatch_size)
dataset = deepxi.dataset(n_epochs=200)
return dataset
def print_layer_output_4dataset(deepxi, dataset):
'''
@param deepxi:
@param dataset:
@return:
'''
from tensorflow.keras import backend as K
input = deepxi.model.input # input
outputs = [layer.output for layer in deepxi.model.layers] # all layer outputs
functors = [K.function([input], [output]) for output in outputs] # evaluation functions
layer_outs_batch = []
for (inp_batch, _tgt_batch, _seq_mask_batch) in dataset.as_numpy_iterator():
layer_outs = [func([inp_batch, 1.]) for func in functors]
layer_outs_batch.append(layer_outs)
return layer_outs_batch
if __name__ == '__main__':
# pretrained model
from quantization_test.create_load_test_model import create_model, load_variables_for_model
deepxi = create_model()
pretrained_deepxi = load_variables_for_model(deepxi)
# summary model
summary_save_model(pretrained_deepxi)
# print variables
print_model_variables(pretrained_deepxi)
# print outputs of all layers, according to a wav file
layer_outputs = print_layer_output_4wav(pretrained_deepxi)
# print outputs of all layers, according to a dataset
dataset = generate_train_dataset(pretrained_deepxi)
layer_outputs_batch = print_layer_output_4dataset(pretrained_deepxi, dataset)
print('done')
同理,可查看每层的输入:
inp = deepxi.model.input # input
inputs = [layer.input for layer in deepxi.model.layers if (isinstance(layer, keras.layers.ReLU) or isinstance(layer, keras.layers.Activation))] # activation layer inputs
outputs = [layer.output for layer in deepxi.model.layers if (isinstance(layer, keras.layers.ReLU) or isinstance(layer, keras.layers.Activation))]
functors_inp = [K.function([inp], [input]) for input in inputs]
functors_outp = [K.function([inp], [output]) for output in outputs]
# Testing
test_x, test_x_len, _, test_x_base_names = Batch(testing_path)
print("Processing observations...")
inp_batch, supplementary_batch, n_frames = deepxi.observation_batch(test_x, test_x_len)
layer_ins = [func(inp_batch) for func in functors_inp]















 4950
4950











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









