







Keras多输入多输出模型构建
1. 多输出模型构建
reference from : https://www.jianshu.com/p/6bcd63a0165c
多输出模型构建
使用keras函数式API构建网络:
# 输入层
inputs = tf.keras.layers.Input(shape=(64,64,3))
# 卷积层及全连接层等相关层
x = tf.keras.layers.Dense(256, activation=tf.nn.relu)(inputs)
# 多输出,定义两个输出,指定名字标识
fc_a=tf.keras.layers.Dense(name='fc_a',units=CLASS_NUM,activation=tf.nn.softmax)(x)
fc_b=tf.keras.layers.Dense(name='fc_b',units=CLASS_NUM,activation=tf.nn.softmax)(x)
# 单输入多输出
model = tf.keras.Model(inputs=inputs, outputs=[fc_a, fc_b])
# 目标函数定义,需与输出层名字对应
losses = {
'fc_a': 'categorical_crossentropy',
'fc_b': 'categorical_crossentropy'}
model.compile(optimizer=tf.train.AdamOptimizer(),
loss=losses,
metrics=['accuracy'])
自定义loss函数
def loss_a(y_true, y_pred):
return tf.keras.losses.categorical_crossentropy(y_true, y_pred)
def loss_b(y_true, y_pred):
return tf.keras.losses.meas_squared_error(y_true, y_pred)
losses = {
'fc_a': loss_a,
'fc_b': loss_b}
model.compile(optimizer=tf.train.AdamOptimizer(),
loss=losses,
metrics=['accuracy'])
批量训练
# data_generator返回的标签形式要是与多输出的数量对应的数组
def data_generator(sample_num, batch_size):
while True:
max_num = sample_num - (sample_num % batch_size)
for i in range(0, max_num, batch_size):
...
yield (batch_x, [batch_a, batch_b])
model.fit_generator(generator=data_generator(sample_num, batch_size),
steps_per_epoch=sample_num//batch_size,
epoches=EPOCHES,
verbose=1)
调试
在自定义的loss函数中,是以Sequence的方式来输入的,如果想调试查看loss的计算过程中的输出,直接print是无法打印值的,这是因为tensorflow的每次op都要以sess为基础来启动,如果想调试,可以用eager_execution模式:
import tensorflow.contrib.eager as tfe
tfe.enable_eager_execution()
np.set_printoptions(threshold=np.nan) # 输出所有元素
2. 多输入多输出模型(上)
reference from : https://blog.csdn.net/weixin_40920290/article/details/80917353
多输入多输出模型
主要输入(main_input): 新闻标题本身,即一系列词语.
辅助输入(aux_input): 接受额外的数据,例如新闻标题的发布时间等.
该模型将通过 两个损失函数 进行监督学习.
较早地在模型中使用主损失函数,是深度学习模型的一个良好正则方法.
下面用函数式API来实现它。
主要输入:接受新闻标题本身,即一个整数序列(每个整数编码一个词)。这些整数在 1 到 10000之间(10000个词的词汇表),且序列长度为100个词:

from keras.layers import Input, Embedding, LSTM, Dense
from keras.models import Model
# 标题输入:接收一个含有 100 个整数的序列,每个整数在 1 到 10000 之间。
# 注意我们可以通过传递一个 `name` 参数来命名任何层。
main_input = Input(shape=(100,), dtype='int32', name='main_input')
# Embedding 层将输入序列编码为一个稠密向量的序列,每个向量维度为 512。
x = Embedding(output_dim=512, input_dim=10000, input_length=100)(main_input)
# LSTM 层把向量序列转换成单个向量,它包含整个序列的上下文信息
lstm_out = LSTM(32)(x)
在这里我们添加辅助损失,使得即使在模型主损失很高的情况下,LSTM层和Embedding层都能被平稳地训练:
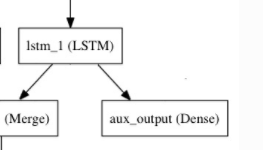
auxiliary_output = Dense(1, activation='sigmoid', name='aux_output')(lstm_out)
此时,我们将辅助输入数据与LSTM层的输出连接起来,输入到模型中:
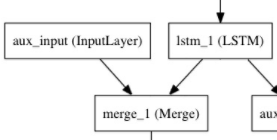
auxiliary_input = Input(shape=(5,), name='aux_input')
x = keras.layers.concatenate([lstm_out, auxiliary_input])
再添加剩余的层:
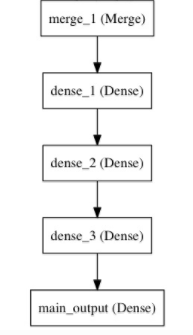
# 堆叠多个全连接网络层
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
# 最后添加主要的逻辑回归层
main_output = Dense(1, activation='sigmoid', name='main_output')(x)
(关键)定义这个具有两个输入和输出的模型:
model = Model(inputs=[main_input, auxiliary_input], outputs=[main_output, auxiliary_output])
编译模型时候分配损失函数权重
编译模型的时候,给 辅助损失 分配一个0.2的权重.
如果要为不同的输出指定不同的 loss_weights 或 loss,可以使用列表或字典.
在这里,我们给 loss 参数传递单个损失函数,这个损失将用于所有的输出。:
model.compile(optimizer='rmsprop', loss='binary_crossentropy',
loss_weights=[1., 0.2])
训练模型
我们可以通过传递输入数组和目标数组的列表来训练模型:
model.fit([headline_data, additional_data], [labels, labels],
epochs=50, batch_size=32)
另外一种编译、训练方式(利用字典)
由于输入和输出均被命名了(在定义时传递了一个 name 参数),我们也可以通过以下方式编译模型:
model.compile(optimizer='rmsprop',
loss={
'main_output': 'binary_crossentropy', 'aux_output': 'binary_crossentropy'},
loss_weights={
'main_output': 1., 'aux_output' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1125
1125











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









