







接触caffe一段时间了 ,一直没有自己完整的跑过自己的数据,现在使用在win10系统上配置好的caffe环境,使用caffeNet网络框架,对自己准备的图片数据集进行训练,并使用生成的模型对图片进行类别预测。接触时间比较短,有的地方理解不到位,现在整理下我处理的流程以及过程之中遇到过的问题,希望可以与大家互享经验,不足之处请大家多多指教。
在caffe目录examples下新建my_classify文件夹,其余文件均在该目录下;
一、制作数据集
1、准备图片
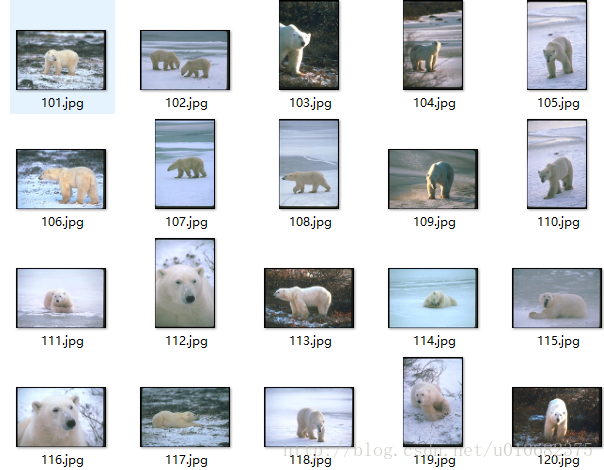
使用Corel数据集中的400图片,4类每类选取100张,其中90张作为训练集,10张作为测试集。所以训练集train中有360张图片,测试集test中有40张图片,分别存放在train与test文件夹中。
2、生成带标签的列表list.txt
分别在train与test文件中生成list.txt列表,切记标签要从0开始。我使用python脚本分别对每个类别图像生成标签 ,然后和在一起的。(方法有点笨,附上基本的生成列表的代码,可以写个循环,直接生成train的list.txt的)
import os
def generate(dir,label):
files = os.listdir(dir)
files.sort()
print '****************'
print 'input :',dir
print 'start...'
listText = open(dir+'\\'+'list.txt','w')
for file in files:
fileType = os.path.split(file)
if fileType[1] == '.txt':
continue
name = file + ' ' + str(int(label)) +'\n'
listText.write(name)
listText.close()
print 'down!'
print '****************'
if __name__ == '__main__':
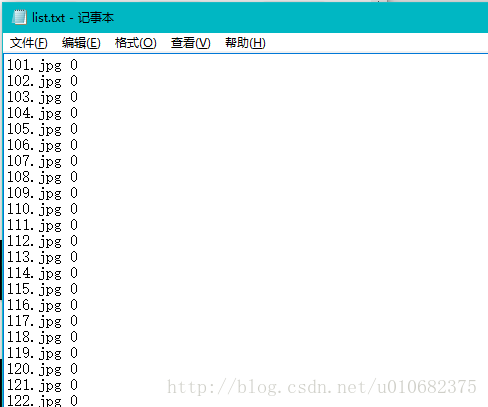
generate('D:\\caffe\\caffe-master\\examples\\my_classify\\Test',1) 生成的list.txt
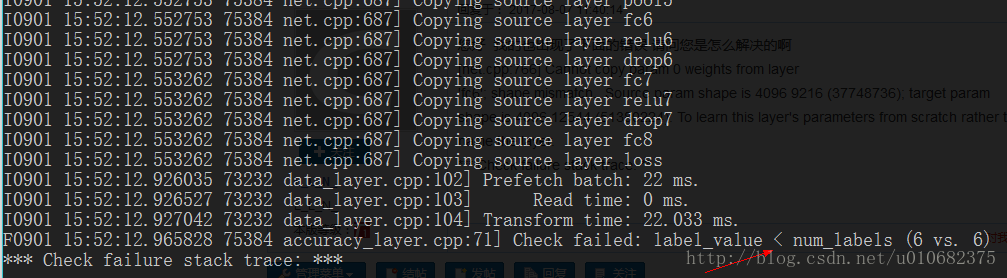
注:如果label标记不从0开始,可能会导致 label_value < num_labels 问题:
3、生成lmdb格式数据集,并生成二进制imagemean.binaryproto的均值文件(size 256 256)
采用windows批处理格式的文件.bat,文件名为:convert_and_computeMean.bat
D:\caffe\caffe-master\Build\x64\Debug\convert_imageset.exe --resize_height=256 --resize_width=256 --shuffle --backend="lmdb" train/ train/list.txt trainlmdb
D:\caffe\caffe-master\Build\x64\Debug\convert_imageset.exe --resize_height=256 --resize_width=256 --shuffle --backend="lmdb" test/ test/list.txt testlmdb
D:\caffe\caffe-master\Build\x64\Debug\compute_image_mean.exe trainlmdb image_mean.binaryproto
pause 运行结果:
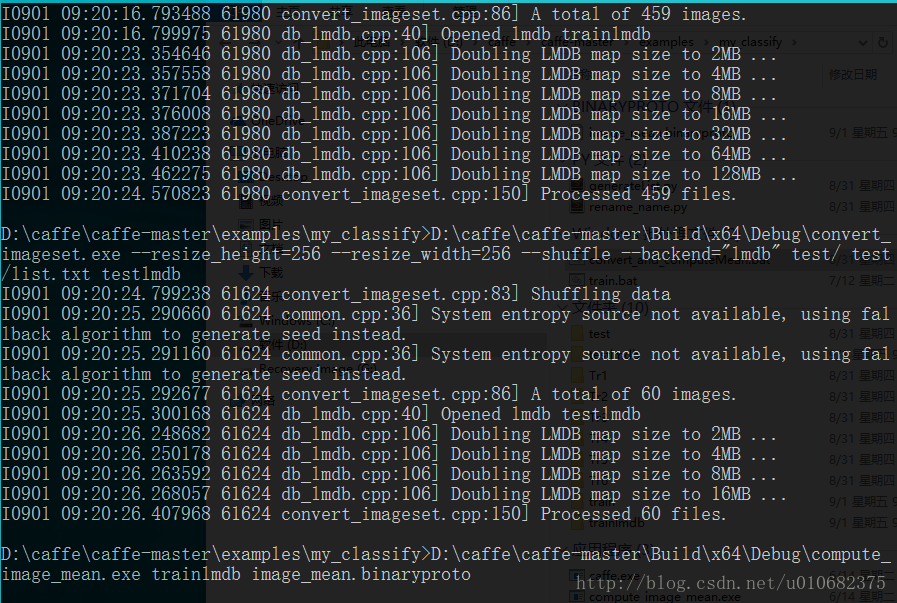
生成trainlmdb、testlmdb和image_mean.binaryproto三个文件
注:如果数据集有改动,要将原来生成的trainlmdb和testlmdb删除,否则会造成如下问题:

至此数据集制作部分完成。
二、新建网络模型train_val.prototxt和solver.prototxt两个文件
这里直接使用caffeNet的网络架构模型
需要做如下更改:
1、训练集与测试集的路径,直接改成了绝对路径;
2、batch_size改成了4,crop_size改成了与图片一般大小的256;
3、最后一层的num_output设置成4,因为只有4类。
name: "CaffeNet"
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size: 256
mean_file: "D:/caffe/caffe-master/examples/my_classify/image_mean.binaryproto"
}
data_param {
source: "D:/caffe/caffe-master/examples/my_classify/trainlmdb"
batch_size: 4
backend: LMDB
}
}
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mirror: false
crop_size: 256
mean_file: "D:/caffe/caffe-master/examples/my_classify/image_mean.binaryproto"
}
data_param {
source: "D:/caffe/caffe-master/examples/my_classify/testlmdb"
batch_size: 4
backend: LMDB
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 96
kernel_size: 11
stride: 4
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "conv1"
top: "conv1"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "norm1"
type: "LRN"
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "norm1"
top: "conv2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 2
kernel_size: 5
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "norm2"
type: "LRN"
bottom: "pool2"
top: "norm2"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv3"
type: "Convolution"
bottom: "norm2"
top: "conv3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "conv4"
type: "Convolution"
bottom: "conv3"
top: "conv4"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu4"
type: "ReLU"
bottom: "conv4"
top: "conv4"
}
layer {
name: "conv5"
type: "Convolution"
bottom: "conv4"
top: "conv5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu5"
type: "ReLU"
bottom: "conv5"
top: "conv5"
}
layer {
name: "pool5"
type: "Pooling"
bottom: "conv5"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "fc6"
type: "InnerProduct"
bottom: "pool5"
top: "fc6"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 4096
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu6"
type: "ReLU"
bottom: "fc6"
top: "fc6"
}
layer {
name: "drop6"
type: "Dropout"
bottom: "fc6"
top: "fc6"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc7"
type: "InnerProduct"
bottom: "fc6"
top: "fc7"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 4096
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu7"
type: "ReLU"
bottom: "fc7"
top: "fc7"
}
layer {
name: "drop7"
type: "Dropout"
bottom: "fc7"
top: "fc7"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 4
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "fc8"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "fc8"
bottom: "label"
top: "loss"
}solver.prototxt文件
net: "D:/caffe/caffe-master/examples/my_classify/train_val.prototxt"
test_iter: 2
test_interval: 50
base_lr: 0.001
lr_policy: "step"
gamma: 0.1
stepsize: 100
display: 20
max_iter: 500
momentum: 0.9
weight_decay: 0.005
solver_mode: GPU
snapshot: 200
snapshot_prefix: "D:/caffe/caffe-master/examples/my_classify/train"至此网络搭建部分结束,接下来可以开始训练
三、训练
新建train.bat文件
caffe.exe train --solver=solver.prototxt --gpu=all
pause 训练结果,其中accuracy=0.625挺低的,首先训练集不够多,其次迭代次数较少
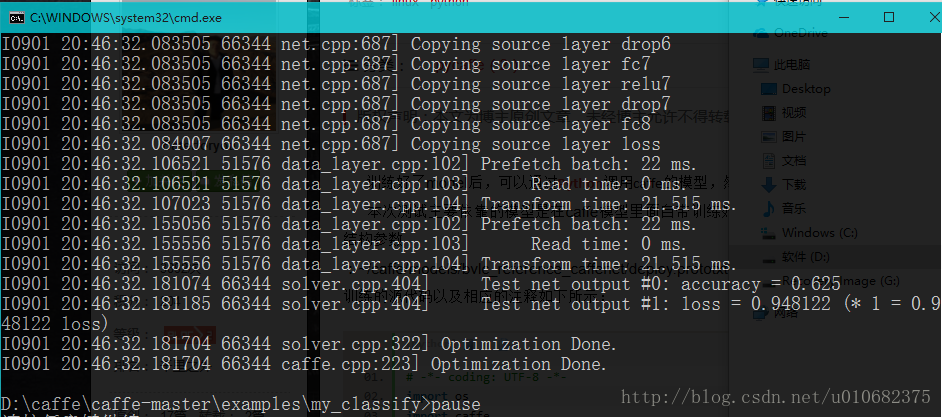
训练结束会生成xxx.caffemodel和xxx.solverstate分别存储训练过程的参数和中段的参数信息
四、利用生成的模型使用python接口测试自己的数据
1、通过脚本将image_mean.binaryproto转换成python可以识别的mean.npy文件
import caffe
import numpy as np
MEAN_PROTO_PATH = 'image_mean.binaryproto'
MEAN_NPY_PATH = 'mean.npy'
blob = caffe.proto.caffe_pb2.BlobProto()
data = open(MEAN_PROTO_PATH, 'rb' ).read()
blob.ParseFromString(data)
array = np.array(caffe.io.blobproto_to_array(blob))
mean_npy = array[0]
np.save(MEAN_NPY_PATH ,mean_npy)2、编写与train_val.prototxt对应的deploy.prototxt用于测试的网络模型
name: "CaffeNet"
layer {
name: "data"
type: "Input"
top: "data"
input_param { shape: { dim: 10 dim: 3 dim: 256 dim: 256 } }
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
convolution_param {
num_output: 96
kernel_size: 11
stride: 4
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "conv1"
top: "conv1"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "norm1"
type: "LRN"
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "norm1"
top: "conv2"
convolution_param {
num_output: 256
pad: 2
kernel_size: 5
group: 2
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "norm2"
type: "LRN"
bottom: "pool2"
top: "norm2"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv3"
type: "Convolution"
bottom: "norm2"
top: "conv3"
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "conv4"
type: "Convolution"
bottom: "conv3"
top: "conv4"
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
group: 2
}
}
layer {
name: "relu4"
type: "ReLU"
bottom: "conv4"
top: "conv4"
}
layer {
name: "conv5"
type: "Convolution"
bottom: "conv4"
top: "conv5"
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
group: 2
}
}
layer {
name: "relu5"
type: "ReLU"
bottom: "conv5"
top: "conv5"
}
layer {
name: "pool5"
type: "Pooling"
bottom: "conv5"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "fc6"
type: "InnerProduct"
bottom: "pool5"
top: "fc6"
inner_product_param {
num_output: 4096
}
}
layer {
name: "relu6"
type: "ReLU"
bottom: "fc6"
top: "fc6"
}
layer {
name: "drop6"
type: "Dropout"
bottom: "fc6"
top: "fc6"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc7"
type: "InnerProduct"
bottom: "fc6"
top: "fc7"
inner_product_param {
num_output: 4096
}
}
layer {
name: "relu7"
type: "ReLU"
bottom: "fc7"
top: "fc7"
}
layer {
name: "drop7"
type: "Dropout"
bottom: "fc7"
top: "fc7"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
inner_product_param {
num_output: 4
}
}
layer {
name: "prob"
type: "Softmax"
bottom: "fc8"
top: "prob"
}3、编写python接口
import caffe
import numpy as np
root = 'D:/caffe/caffe-master/examples/my_classify/'
#设置测试网络
deploy = root + 'deploy.prototxt'
#添加训练的网络权重参数
caffe_model = root + 'train_iter_500.caffemodel'
#测试图片
img = root + '4.jpg'
#标签文件
label_file = root + 'label.txt'
#均值文件
mean_file = root + 'mean.npy'
#设置使用GPU
caffe.set_model_gpu()
#构造一个net
net = caffe.Net(deploy,caffe_model,caffe.TEST)
# 得到data的形状,这里的图片是默认matplotlib底层加载的
transformer = caffe.io.Transformer({'data':net.blobs['data'].data.shape})
# matplotlib加载的image是像素[0-1],图片的数据格式[weight,high,channels],RGB
# caffe加载的图片需要的是[0-255]像素,数据格式[channels,weight,high],BGR,那么就需要转换
transformer.set_transpose('data', (2,0,1))
transformer.set_mean('data', np.load(mean_file).mean(1).mean(1))
# 图片像素放大到[0-255]
transformer.set_raw_scale('data', 255)
# RGB-->BGR 转换
transformer.set_channel_swap('data', (2,1,0))
#设置输入的图片shape,1张,3通道,长宽都是256
net.blobs['data'].reshape(1,3,256,256)
#加载图片
im = caffe.io.load_image(img)
net.blobs['data'].data[...] = transformer.preprocess('data', im)
#输出每层网络的name和shape
for layer_name,blob in net.blobs.iteritems():
print layer_name + '\t' + str(blob.data.shape)
#网络向前传播
out = net.forward()
labels = np.loadtxt(label_file,str,delimiter = '\t')
prob = net.blobs['prob'].data[0].flatten()
print prob
order = prob.argsort()[-1]
#输出类别
print 'the class is:',labels[order]
测试图片为:
分类结果为:
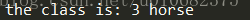















 1101
1101

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









