









python 实现简单网络爬虫
这个学期一直在忙着做毕业设计,一直懒得写blog。想想还是记录一下为好。
功能描述:
1.分析链接文件,获取URL集合
2.获取URL对应网页,存储到本地特定文件夹
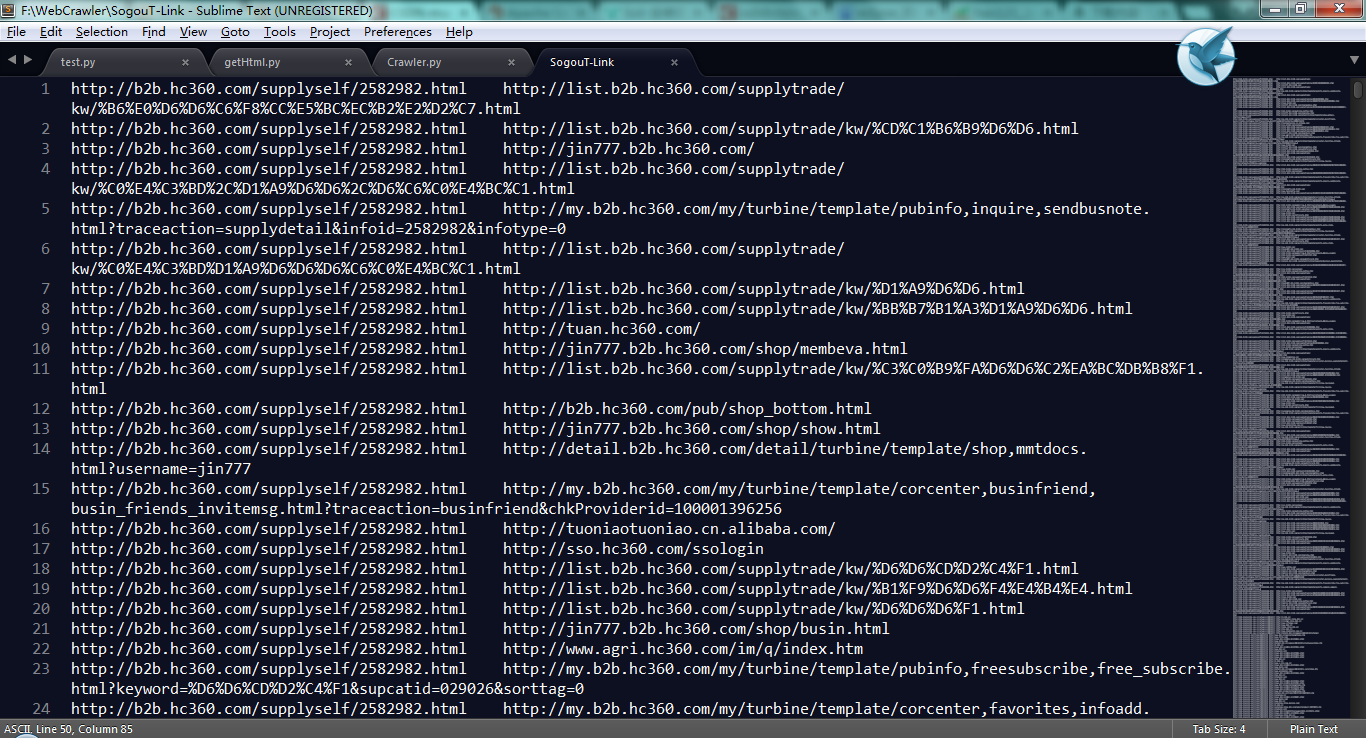
链接文件的格式:
每一行两个URL 类似:URL1 URL2 中间以 tab 键隔开。
Note:这样的格式是因为我使用的是Sogou实验室提供的数据,用来实现PageRank算法的,这种文件格式方便PageRank算法实现。你可以在here下载
Source Code
import urllib
import re
import os
import traceback
#下载url对应的html
def downLoadHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
#SogouT-Link.mini为链接文件
fp = open('F:\\WebCrawler\\SogouT-Link.mini','r')
#创建url集合,集合中元素唯一,确保不重复下载网页
urlset = set()
lines = fp.readlines()
fp.close()
for line in lines:
urls = line.split('\t')
urlset.add(urls[0])
urlset.add(urls[1])
for url in urlset:
print '[+]',url
id = 0
errCount = 0;
for url in urlset:
try:
f = open('F:\\WebCrawler\\data\\'+'%s.html'%id,mode='w')
print ('[+]start download %ss page\r\n' %id)
html = downLoadHtml(url)
f.write(html)
id = id + 1
except Exception as e:
print e
errCount += 1
finally:
f.close()运行
$python Crawler.py图示:
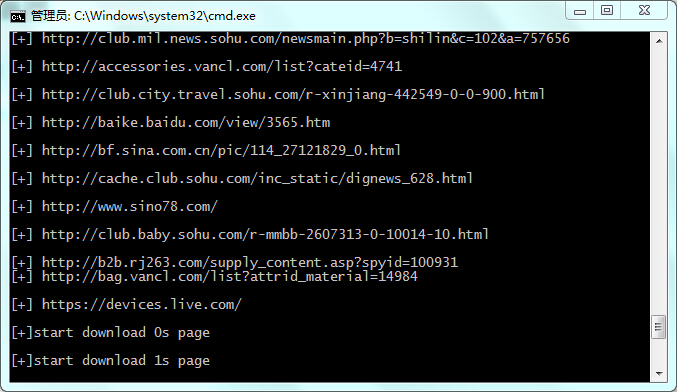
下载文件:















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









