










一、理论
https://www.zybuluo.com/yxd/note/611571
训练流程:
1 估计初值
2 按如下方式构造M颗树
2.1 随机选取部分样本作为本颗树的训练数据
2.2 按如下方式寻找最优分裂点,进行N次叶子节点的分裂
2.2.1 对当前所有叶子节点
2.2.1.1 计算该叶子节点的最优划分以及其增益(损失函数减少量)
2.2.1.2 选择增益最大的叶子节点及其划分点,进行分裂,将样本划分到子节点中
2.2.1.3 更新样本估计值
由于数据太少,我们限定叶子节点做多有两个,即每棵树都只有一个分枝,并且限定只学两棵树。我们会得到如下图2所示结果:
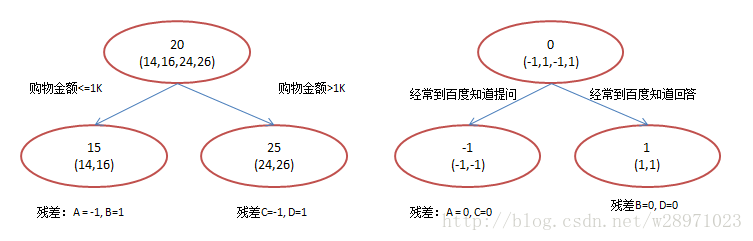
在第一棵树分枝和图1一样,由于A,B年龄较为相近,C,D年龄较为相近,他们被分为两拨,每拨用平均年龄作为预测值。此时计算残差(残差的意思就是: A的预测值 + A的残差 = A的实际值),所以A的残差就是16-15=1(注意,A的预测值是指前面所有树累加的和,这里前面只有一棵树所以直接是15,如果还有树则需要都累加起来作为A的预测值)。进而得到A,B,C,D的残差分别为-1,1,-1,1。然后我们拿残差替代A,B,C,D的原值,到第二棵树去学习,如果我们的预测值和它们的残差相等,则只需把第二棵树的结论累加到第一棵树上就能得到真实年龄了。这里的数据显然是我可以做的,第二棵树只有两个值1和-1,直接分成两个节点。此时所有人的残差都是0,即每个人都得到了真实的预测值。
换句话说,现在A,B,C,D的预测值都和真实年龄一致了。Perfect!:
A: 14岁高一学生,购物较少,经常问学长问题;预测年龄A = 15 – 1 = 14
B: 16岁高三学生;购物较少,经常被学弟问问题;预测年龄B = 15 + 1 = 16
C: 24岁应届毕业生;购物较多,经常问师兄问题;预测年龄C = 25 – 1 = 24
D: 26岁工作两年员工;购物较多,经常被师弟问问题;预测年龄D = 25 + 1 = 26
- 使用场景
二、GBRT
- 使用场景
三、实现
- python
- scala

Reference:















 6917
6917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









