







一、导言
谱聚类(Spectral Clustering)因为其严谨的理论基础及其能够处理复杂聚类形状的优势,在实践中存在大规模的应用。
对谱聚类有一定了解的同学一定知道,谱聚类有两种解释的观点:图分割和随机游走,Laplacian矩阵的特征值分解如何等价(近似)与图分割或随机游走的数学证明不在本篇博客的范围内。
当我们被给定一个dataset,不管我们用哪一种方式去求解Laplacian矩阵的特征值和特征向量,最终得到的是该dataset内所有样本点所属的cluster。这就引入了该篇博客想要阐述的问题:
当我们更新dataset中的样本点或向dataset中增加样本点,是否存在某种(近似)方法能够在低时间复杂度上动态更新特征值和特征向量,能够避免每次重新求解。
本博客主要参考论文“Incremental spectral clustering by efficiently updating the eigen-system”,以下即对该论文的核心观点进行深度解读。
二、算法原理
1、先导
该篇博客内涉及到非常多谱聚类的背景知识,这些前导知识对理解谱聚类的增量更新方式非常重要,建议读者优先阅读Von Luxburg的”A tutorial on spectral clustering”,见文献[1]。
博客中的算法原理、公式推导主要参考文献[2],爱智求真的读者可以直接阅读原文文献。
另外,该博客以算法展示和可行性论证为主;而公式推导部分非常繁杂,有时间我会在以后的博客中深究推导。
2、 问题引入
当我们对下图中的a进行谱聚类(聚类数量=2)的时候,我们发现 ABC 和 DEF 能够成为两个聚类。但当我们调整 EdgeCD=0.1 至 EdgeCD=0.5 、同时增加 EdgeFG=0.5 的时候,通过谱聚类发现 ABCD 和 EFG 成为两个聚类。

当“边的增删改”动作非常频繁,且我们要处理的图非常大的时候,每次全图进行谱聚类的开销会无法承担。
那么接下来论文中提出了一种很实用的算法框架,能够在近似O(n)的时间复杂度上对谱聚类得到的特征值和特征向量进行更新。
3、Incidence vector & Incidence matrix
incidence vector的定义如下:
Incidence vector rij(w) 是一个列向量(长度为样本点的数量),第 i 个位置上的值为
w‾‾√ 、第 j 个位置上的值为−w‾‾√ ,其余位置的值为 0 。
incidence matrix的定义如下:
Incidence matrix
R 的每一列为一个incidence vector。
由定义我们可以发现,incidence matrix R 内包含了相似度矩阵的所有信息。下面我们用一个6个节点的网络进行示意:
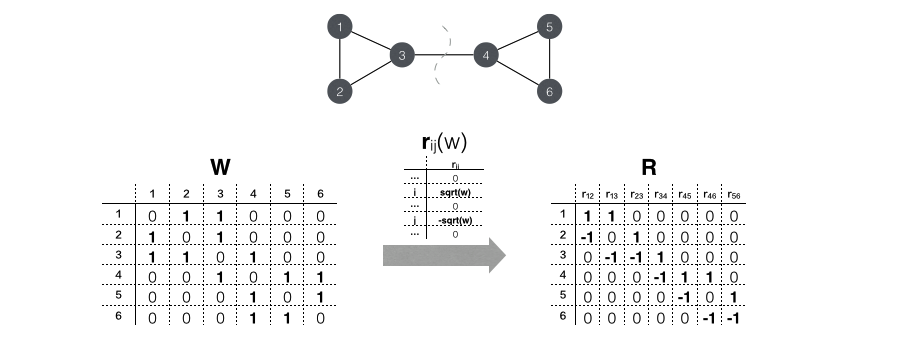
那么接下来我们可以得到这样的结论:
L=RRT ,其中 R=rij(wij):1≤i<j≤n(此处证明略去,读者可自行证明。)
那么对于上述6节点的网络示例,我可以做出以下推断:
RRT===⎡⎣⎢⎢⎢⎢⎢⎢⎢1−1000010−100001−1000001−1000001−100001−1−100001−1⎤⎦⎥⎥⎥⎥⎥⎥⎥∗⎡⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢1100000−10100000−1−11000000−11100000−10100000−1−1⎤⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎡⎣⎢⎢⎢⎢⎢⎢⎢2−1−1000−12−1000−1−13−10000−13−1−1000−12−1000−1−12⎤⎦⎥⎥⎥⎥⎥⎥⎥L接下去,如果样本点 i 和
j 有了一次相似度的改变 Δwij ,那么对应的incident vector可以表达为 rij(Δwij) 。新的Laplacian矩阵可以表达为 L̃ =R̃ R̃ T ,其中 R̃ =[R,rij(Δwij)] 。这样我们可以引出:
ΔL=L̃ −L=ΔwijuijuTijΔD=Δwijdiag{vij}
uij 是列向量且第i位置上的值为1,第j位置上未-1,其余为0。
vij 是列向量且第i,j位置上的值为1,其余为0。这样当我们尝试去修改这个图的时候,“边的增删改”操作可以分解为一系列相似度的改变 Δwij 。
4、从Ncut来看谱聚类
根据拉普拉斯矩阵的定义: L=D−W ,我们可以求解 L 的特征值。
fTLf===fTDf−fTWf∑i=1ndif2i−∑i,jnfifjwij12∑i,jnwij(fi−fj)2 接下去,我们用二分类问题来证明Ncut和求解 L 的特征向量等价:
首先将特征向量的选择条件放宽,假定
fi 为非正即负:
fi=⎧⎩⎨⎪⎪⎪⎪vol(A¯)vol(A)‾‾‾‾‾√−vol(A)vol(A¯)‾‾‾‾‾√ifvi∈Aifvi∈A¯那么我们可以证明Ncut等价与normalized谱聚类:
fTLf======12∑i,jnwij(fi−fj)212∑i∈A,j∈A¯wij⎛⎝⎜⎜∣∣A¯∣∣|A|‾‾‾‾√+|A|∣∣A¯∣∣‾‾‾‾√⎞⎠⎟⎟2+12∑i∈A¯,j∈Awij⎛⎝⎜⎜−|A|∣∣A¯∣∣−∣∣A¯∣∣|A|‾‾‾‾√‾‾‾‾‾‾‾‾‾‾‾‾⎷⎞⎠⎟⎟2⎛⎝⎜⎜12∑i∈A,j∈A¯wij+12∑i∈A¯,j∈Awij⎞⎠⎟⎟∗(|A|∣∣A¯∣∣+∣∣A¯∣∣|A|+2)⎛⎝⎜⎜∑i∈A,j∈A¯wij⎞⎠⎟⎟∗(vol(V)∣∣vol(A)∣∣+vol(V)∣∣vol(A¯)∣∣)vol(V)∗12∑i=12W(Ai,A¯i)vol(Ai)vol(V)∗Ncut(A,A¯)由 k=2 我们可以衍生至 k 为任意值时的场景,在此不再继续推导。
5、特征向量
Δλ 和特征值 Δf 的计算从第4节中,我们推导出:
ΔL=L̃ −L=ΔwijuijuTijΔD=Δwijdiag{vij}
uij 是列向量且第i位置上的值为1,第j位置上未-1,其余为0。
vij 是列向量且第i,j位置上的值为1,其余为0。又由于广义特征系统 Ax=λBx ,可以做出以下推导:
AxΔAx+AΔxxTΔAx+xTAΔxxTΔAx=λBx=ΔλBx+λΔBx+λBΔx=xTΔλBx+xTλΔBx+xTλBΔx=ΔλxTBx+λxTΔBx之后将 A 替换为
L , B 替换成D , x 替换成 f ,则可以得到:
Δλ=ΔwijfT(uijuTij−λdiag{vij})ffTDf=ΔwijfTuijuTij−ΔwijλfTdiag{vij}f=Δwij((fi−fj)2−λ(f2i+f2j))
Δf=(KTK)−1KTNijh;其中K=L−λD,h=(ΔλD+λΔD−ΔL)f注意, Δλ 可以很快计算出来,但是 Δf 的时间复杂度仍然非常高。这时,我们可以做出以下近似:
对于 Δf 中 K 的计算,由于一次
Δwij 只会对局部的聚类结果产生影响;那么对于远离 i,j 的任意点 k ,Δfik或Δfjk 均为0。我们定义 i,j 的所有邻居 Nij={k|wik>τorwik>τ} ,其中 τ 可以进行大小调整以体现 i,j 的邻居信息。这样我们就可以得到:
Δfij=(KTNijKNij)−1KTNijh6、算法主体
Algorithm 迭代更新 Δλ 和 Δf :
1. 首先根据一次相似度的变化计算 Δwij ;
2. 设 Δf=0 ;
3. 计算 Δλ=Δwij((fi−fj)2−λ(f2i+f2j)) ;
4. 计算 Δfij=(KTNijKNij)−1KTNijh ;
5. 重复 步骤2 和 3直到 Δλ 和 Δf 没有明显变化或达到 n 次迭代上限。由于算法在经过多次对单个图的计算后,误差会不断累积,我们在每隔一段时间重新全局进行谱聚类的计算即可。
7、时间复杂度
根据公式我们能够看到
Δλ 的时间复杂度为常数,而 Δf 的计算时间复杂度为:
O(N¯2n)+O(N¯3)+O(N¯n)+O(N¯2)
其中从左到右,分别对应着 KTNijKNij 的计算、求逆计算、 KTNijh 的计算和最终乘积计算, N¯ 即由 τ 决定的邻居的数量。该算法的时间复杂度比谱聚类的常规解 O(n3) ,甚至很多近似解(如Labczos解法的 O(n3/2) )都要要小很多。
三、文献
[1] Von Luxburg U. A tutorial on spectral clustering[J]. Statistics and computing, 2007, 17(4): 395-416.
[2] Ning H, Xu W, Chi Y, et al. Incremental spectral clustering by efficiently updating the eigen-system[J]. Pattern Recognition, 2010, 43(1): 113-127.

















 1154
1154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









