









1. create table执行过程详解
待执行SQL:
CREATE TABLE source
(
emp_no INT,
birth_date DATE,
first_name STRING,
last_name STRING,
gender STRING,
hire_date DATE,
aa STRING,
PRIMARY KEY (emp_no) NOT ENFORCED
) WITH (
'connector' = 'binlog-x'
,'username' = 'dlink'
,'password' = 'Dlink20221125'
,'cat' = 'insert,delete,update'
,'url' = 'jdbc:mysql://mysql-dlink:3306/dlink?useUnicode=true&characterEncoding=UTF-8&useSSL=false'
,'host' = 'mysql-dlink'
,'port' = '3306'
,'table' = 'ztt_employees'
,'timestamp-format.standard' = 'SQL'
);
sql是交给了flink环境去执行了,就是所配置的flink执行环境,这里是本地执行,用的是flink-1.12.7,所以到了相关flink版本的TableEnvironmentImpl的实现中,如下图:
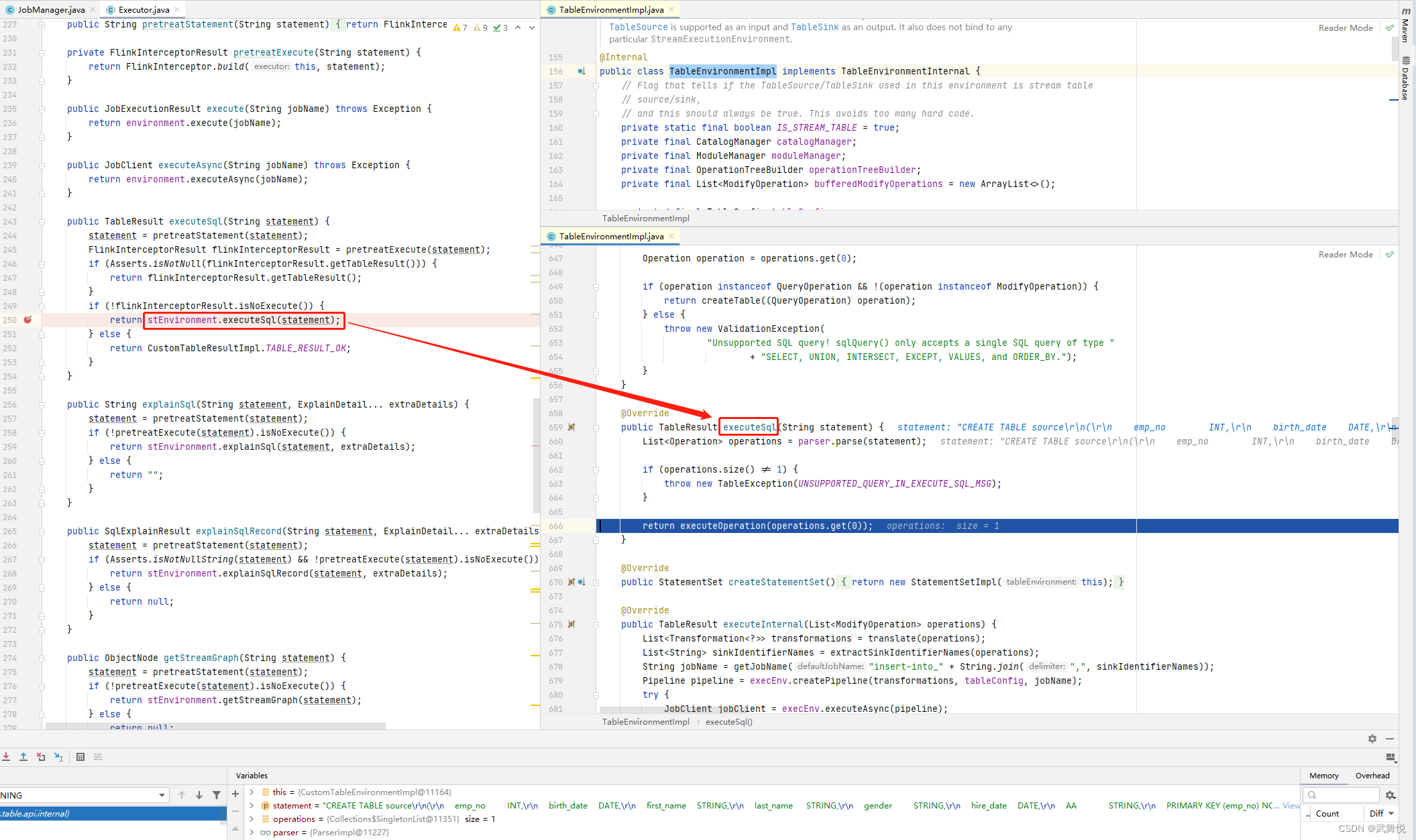
代码不复杂,第一句就是对sql的分析(parser.parse(statement)),这个是调用flink-table-blink_2.12-1.12.7.jar包里的相关代码,不复杂,贴出来看看:
package org.apache.flink.table.planner.delegation;
import org.apache.flink.table.api.TableException;
import org.apache.flink.table.api.TableSchema;
import org.apache.flink.table.catalog.CatalogManager;
import org.apache.flink.table.catalog.UnresolvedIdentifier;
import org.apache.flink.table.delegation.Parser;
import org.apache.flink.table.expressions.ResolvedExpression;
import org.apache.flink.table.operations.Operation;
import org.apache.flink.table.planner.calcite.CalciteParser;
import org.apache.flink.table.planner.calcite.FlinkPlannerImpl;
import org.apache.flink.table.planner.calcite.FlinkTypeFactory;
import org.apache.flink.table.planner.calcite.SqlExprToRexConverter;
import org.apache.flink.table.planner.expressions.RexNodeExpression;
import org.apache.flink.table.planner.operations.SqlToOperationConverter;
import org.apache.flink.table.types.logical.LogicalType;
import org.apache.flink.table.types.utils.TypeConversions;
import org.apache.calcite.rex.RexNode;
import org.apache.calcite.sql.SqlIdentifier;
import org.apache.calcite.sql.SqlNode;
import java.util.Collections;
import java.util.List;
import java.util.function.Function;
import java.util.function.Supplier;
/** Implementation of {@link Parser} that uses Calcite. */
public class ParserImpl implements Parser {
private final CatalogManager catalogManager;
// we use supplier pattern here in order to use the most up to
// date configuration. Users might change the parser configuration in a TableConfig in between
// multiple statements parsing
private final Supplier<FlinkPlannerImpl> validatorSupplier;
private final Supplier<CalciteParser> calciteParserSupplier;
private final Function<TableSchema, SqlExprToRexConverter> sqlExprToRexConverterCreator;
public ParserImpl(
CatalogManager catalogManager,
Supplier<FlinkPlannerImpl> validatorSupplier,
Supplier<CalciteParser> calciteParserSupplier,
Function<TableSchema, SqlExprToRexConverter> sqlExprToRexConverterCreator) {
this.catalogManager = catalogManager;
this.validatorSupplier = validatorSupplier;
this.calciteParserSupplier = calciteParserSupplier;
this.sqlExprToRexConverterCreator = sqlExprToRexConverterCreator;
}
@Override
public List<Operation> parse(String statement) {
CalciteParser parser = calciteParserSupplier.get();
FlinkPlannerImpl planner = validatorSupplier.get();
// parse the sql query
SqlNode parsed = parser.parse(statement);
Operation operation =
SqlToOperationConverter.convert(planner, catalogManager, parsed)
.orElseThrow(() -> new TableException("Unsupported query: " + statement));
return Collections.singletonList(operation);
}
@Override
public UnresolvedIdentifier parseIdentifier(String identifier) {
CalciteParser parser = calciteParserSupplier.get();
SqlIdentifier sqlIdentifier = parser.parseIdentifier(identifier);
return UnresolvedIdentifier.of(sqlIdentifier.names);
}
@Override
public ResolvedExpression parseSqlExpression(String sqlExpression, TableSchema inputSchema) {
SqlExprToRexConverter sqlExprToRexConverter =
sqlExprToRexConverterCreator.apply(inputSchema);
RexNode rexNode = sqlExprToRexConverter.convertToRexNode(sqlExpression);
LogicalType logicalType = FlinkTypeFactory.toLogicalType(rexNode.getType());
return new RexNodeExpression(rexNode, TypeConversions.fromLogicalToDataType(logicalType));
}
}
看得出来,这里调用的是calcite相关接口进行sql解析,也是被flink二次封装的;最终转成Operationc对象;跟踪一下parse过程:

解析出来,得到SqlNode对象,关键属性如下:

前面讲过,Executor的executeSql方法调用TableEnvironmentImpl的executeSql方法,来看一下它的执行过程:

这里看到有一个核心对象,就是catalogManager,整体看一下从Executor到TableEnvironmentImpl,再到CatalogManager的过程:

CatalogManager的execute根据command的内容执行相应指令,这里会执行到GenericInMemoryCatalog的createTable方法:
public class GenericInMemoryCatalog extends AbstractCatalog {
// ......
@Override
public void createTable(ObjectPath tablePath, CatalogBaseTable table, boolean ignoreIfExists)
throws TableAlreadyExistException, DatabaseNotExistException {
checkNotNull(tablePath);
checkNotNull(table);
if (!databaseExists(tablePath.getDatabaseName())) {
throw new DatabaseNotExistException(getName(), tablePath.getDatabaseName());
}
if (tableExists(tablePath)) {
if (!ignoreIfExists) {
throw new TableAlreadyExistException(getName(), tablePath);
}
} else {
tables.put(tablePath, table.copy());
if (isPartitionedTable(tablePath)) {
partitions.put(tablePath, new LinkedHashMap<>());
partitionStats.put(tablePath, new LinkedHashMap<>());
partitionColumnStats.put(tablePath, new LinkedHashMap<>());
}
}
}
// ......
}
2. Flink Catalog
简单来说,Catalog就是元数据管理中心,其中元数据包括数据库、表、表结构等信息;Catalog提供了一个统一的API,用于管理元数据,并使其可以从Table API和SQL查询语句中来访问。
Catalog相关代码定义在flink-table-common模块里的Catalog.java文件中,是一个interface,如下(这里是Flink-1.12.7):

将这些接口做一个简单的分类。
- Database 相关操作
- getDefaultDataBase:获取默认的 database
- getDatabase:获取特定的 database
- listDatabases:列出所有的 database
- databaseExists:判断 database 是否存在
- createDatabases:创建 database
- dropDatabases:删除 database
- alterDatabases:修改 database
- Table 相关操作,一般都会有个参数是database
- listTables:列出所有的 table 和 view
- getTable:获取指定的 table 或者 view
- tableExist:判断 table 或者 view 是否存在
- dropTable:删除 table 或者 view
- createTable:创建 table 或者 view
- renameTable:重命名 table 或者 view
- alterTable:修改 table 或者 view
- View 相关操作,除了和 table 共用方法外,还有一个独有的方法。
- listViews:列出所有的 view
- Partition 相关操作,partition 是 table 的一个属性,所以参数一般都会带有 table 信息。
- listPartition:列出 table 的所有 partition
- getPartition:获取指定的 partition
- partitionExist:判断 parition 是否存在
- createPartition:创建 partition
- dropPartition:删除 partition
- alterPartition:修改 parition
- Function 相关操作,这里的 function 知道的是用户自定义的 function,也就是 Udf。
- listFunctions:列出所有的 function
- getFunction:获取指定的 func
- functionExist:判断 function 是否存在
- dropFunction:删除 function
- alterFunction:修改 function
下面展示一下Catalog(flink-1.12.7)及相关继承类的类图:

3. Flink TableEnvironment
TableEnvironment是用来创建Table & SQL程序的上下文执行环境,也是Table & SQL程序的入口,Table & SQL 程序的所有功能都是围绕TableEnvironment这个核心类展开的。
主要作用:
- 对接外部系统,表及元数据的注册和检索,
- 执行SQL语句,提供更详细的配置选项。
下面展示一下TableEnvironment(flink-1.12.7)及相关继承类的类图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dbTjgN5h-1677461078491)(pic\code-flink1-12-7-TableEnvironment-class-diagram.png)]















 1746
1746











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









