









在Dlink0.7.4使用savepoint恢复flinksql作业
1. 运行环境
| 说明项 | 内容 |
|---|---|
| hadoop版本 | hadoop-3.1.4 |
| flink任务执行模式 | Yarn Session |
| flink版本 | flink-1.17.0 |
| dlink版本 | dlink-release-0.7.4 |
| kafka版本 | kafka_2.12-3.5.1 |
| kafka运行模式 | kraft |
| mysql版本 | 5.7.28 |
HDFS集群、YARN集群、Dilink环境的搭建和启动,这里略过,假设已经完成
1.1 本用例在Dlink0.7.4运行时所需的jar包
在本用例中,以Kafka作为source,以MySQL作为sink;
把Kafka的依赖包放到dlink-release-0.7.4/plugins/flink1.17下,另外还增加flink-connector-jdbc:
- flink-connector-jdbc-1.17.0.jar
- flink-sql-connector-kafka-1.17.0.jar
把MySQL的JDBC驱动包放到dlink-release-0.7.4/lib下:
- mysql-connector-java-8.0.28.jar
1.2 Flink配置中指定savepoint目录位置
修改Flink家目录下flink/conf/flink-conf.yaml文件,指定savepoint目录位置
# Default target directory for savepoints, optional.
#
# state.savepoints.dir: hdfs://namenode-host:port/flink-savepoints
state.savepoints.dir: hdfs://bd171:8020/sp
2. 在Dlink0.7.4中运行flinksql作业
2.1 申请Yarn Session来启动Flink集群
在Flink家目录下执行以下命令向YARN集群申请资源,开启一个YARN会话,启动Flink集群:
./bin/yarn-session.sh -d -nm ww
可以在Yarn Web UI中看到我们新启动的YARN会话:
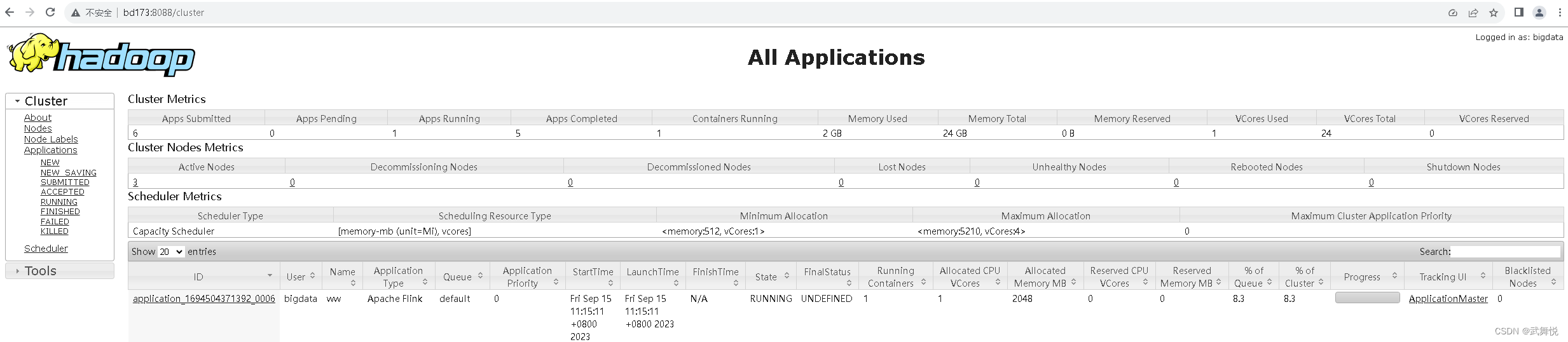
参数说明:
- -d:分离模式,如果你不想让Flink YARN客户端一直前台运行,可以使用这个参数,即使关掉当前对话窗口,YARN session也可以后台运行。
- -nm(–name):配置在YARN UI界面上显示的任务名。
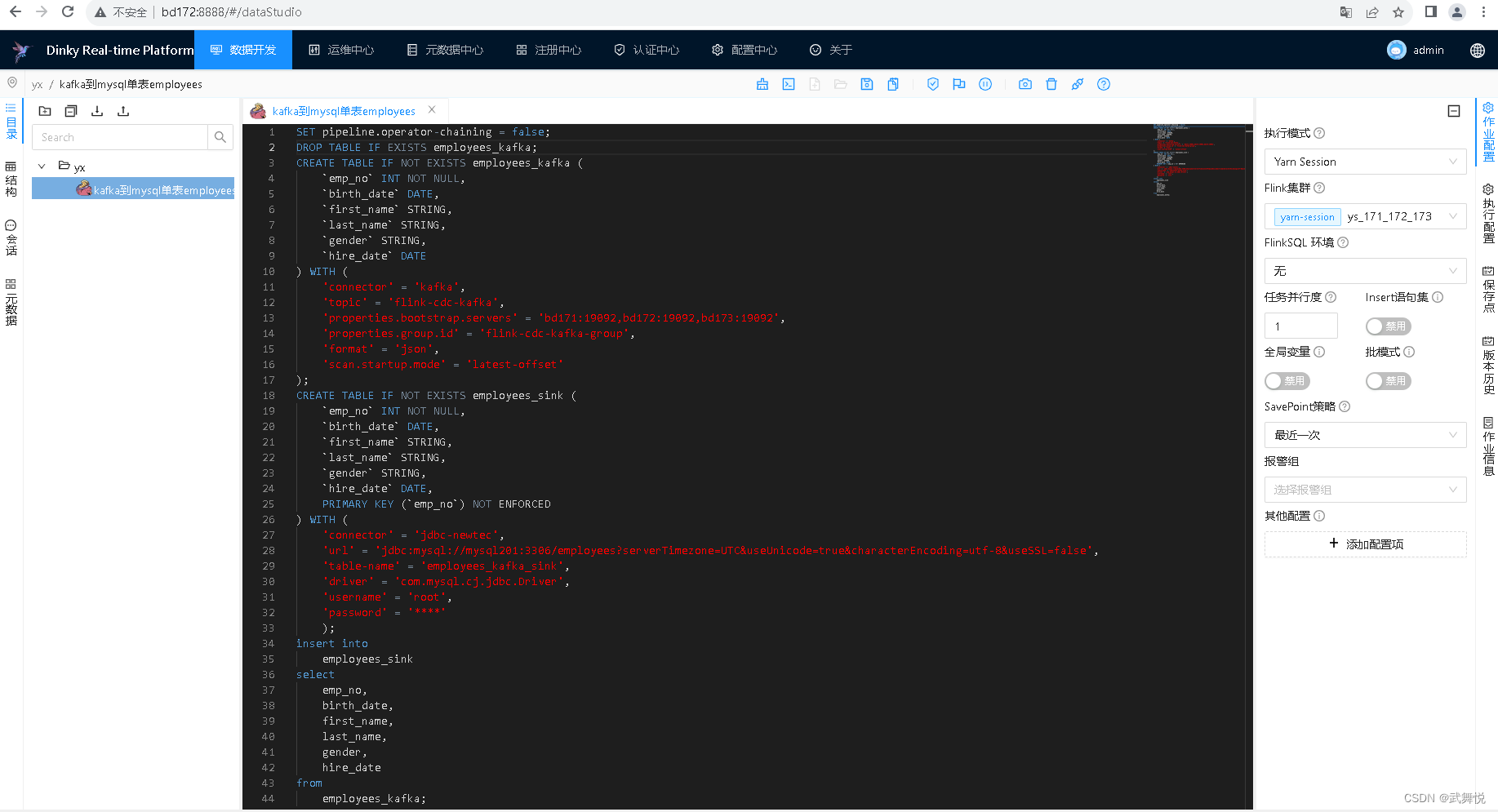
2.2 编写FlinkSQL作业
在编辑器中输入以下内容:
SET pipeline.operator-chaining = false;
DROP TABLE IF EXISTS employees_kafka;
CREATE TABLE IF NOT EXISTS employees_kafka (
`emp_no` INT NOT NULL,
`birth_date` DATE,
`first_name` STRING,
`last_name` STRING,
`gender` STRING,
`hire_date` DATE
) WITH (
'connector' = 'kafka',
'topic' = 'flink-cdc-kafka',
'properties.bootstrap.servers' = 'bd171:19092,bd172:19092,bd173:19092',
'properties.group.id' = 'flink-cdc-kafka-group',
'format' = 'json',
'scan.startup.mode' = 'latest-offset'
);
CREATE TABLE IF NOT EXISTS employees_sink (
`emp_no` INT NOT NULL,
`birth_date` DATE,
`first_name` STRING,
`last_name` STRING,
`gender` STRING,
`hire_date` DATE,
PRIMARY KEY (`emp_no`) NOT ENFORCED
) WITH (
'connector' = 'jdbc-newtec',
'url' = 'jdbc:mysql://mysql201:3306/employees?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=false',
'table-name' = 'employees_kafka_sink',
'driver' = 'com.mysql.cj.jdbc.Driver',
'username' = 'root',
'password' = '****'
);
insert into
employees_sink
select
emp_no,
birth_date,
first_name,
last_name,
gender,
hire_date
from
employees_kafka;
同时注意右边SavePoint策略,选择“最近一次”,然后运行这个作业:
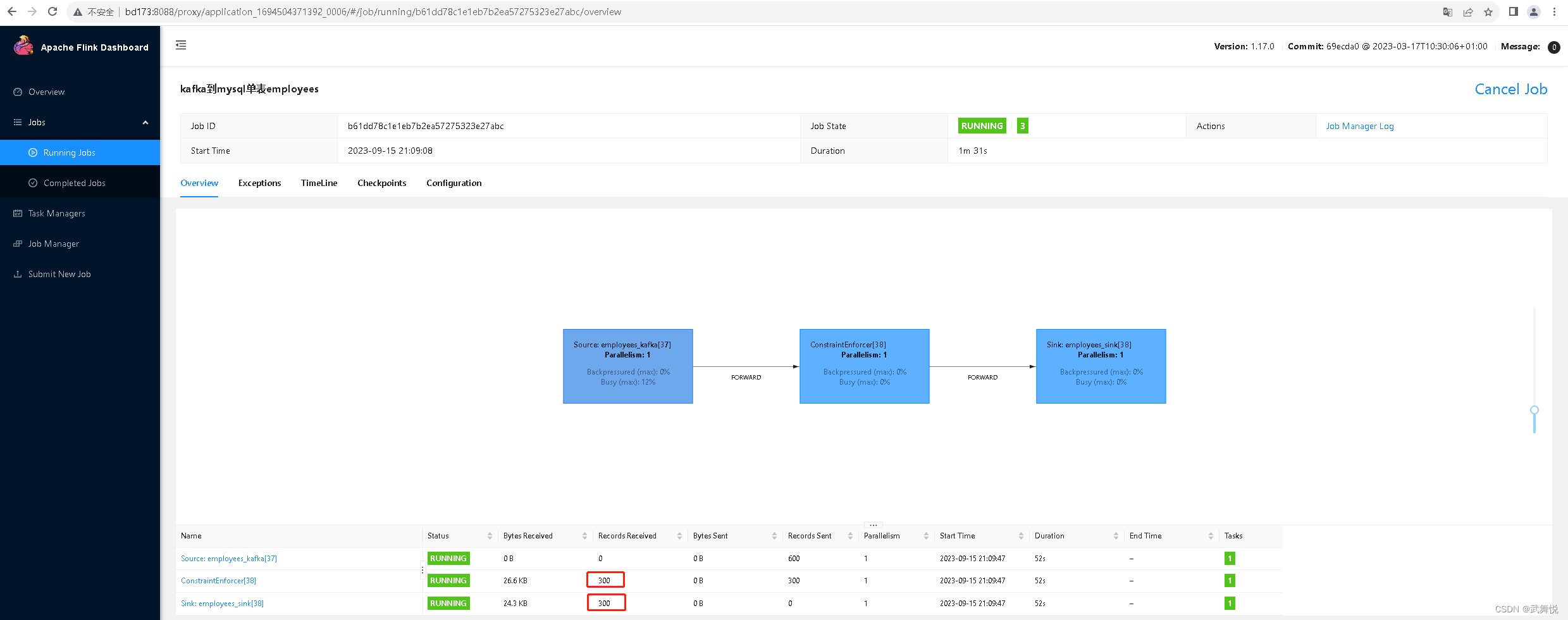
此时我们向kafka相关topic插入300条记录,随后这些数据写到了MySQL数据库的相关表里:
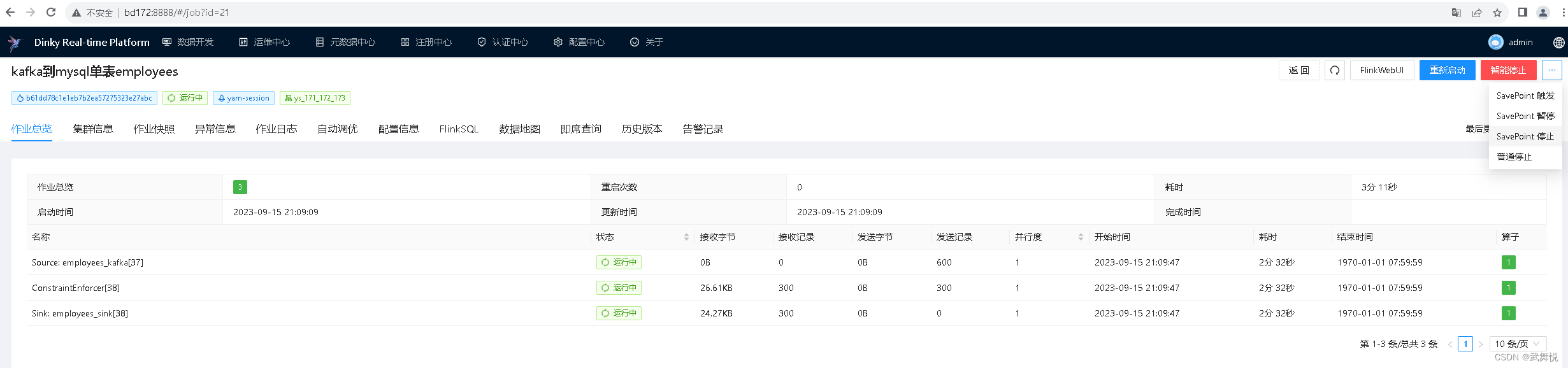
2.3 SavePoint停止FlinkSQL作业
点击dlink的运维中心菜单,在任务列表里点击上面运行的这个任务进入任务详情页面,在页面右上角点击三个点的省略号按钮,弹出框中点击“SavePoint停止”:
在HDFS中可以看到相关的SavePoint保存记录:
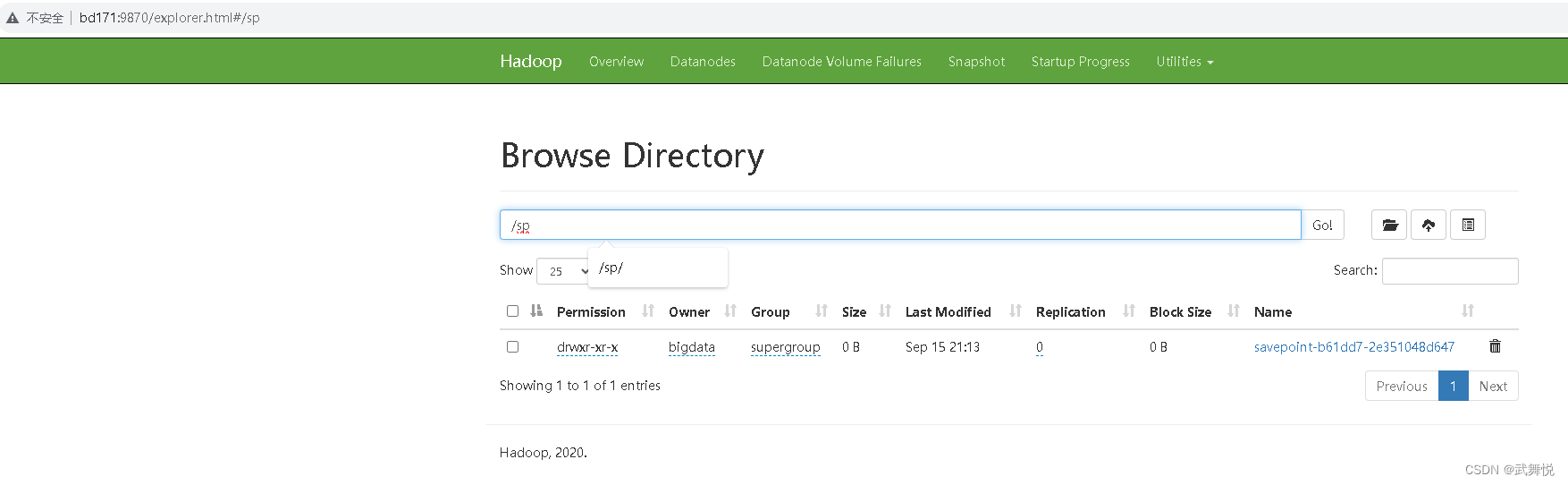
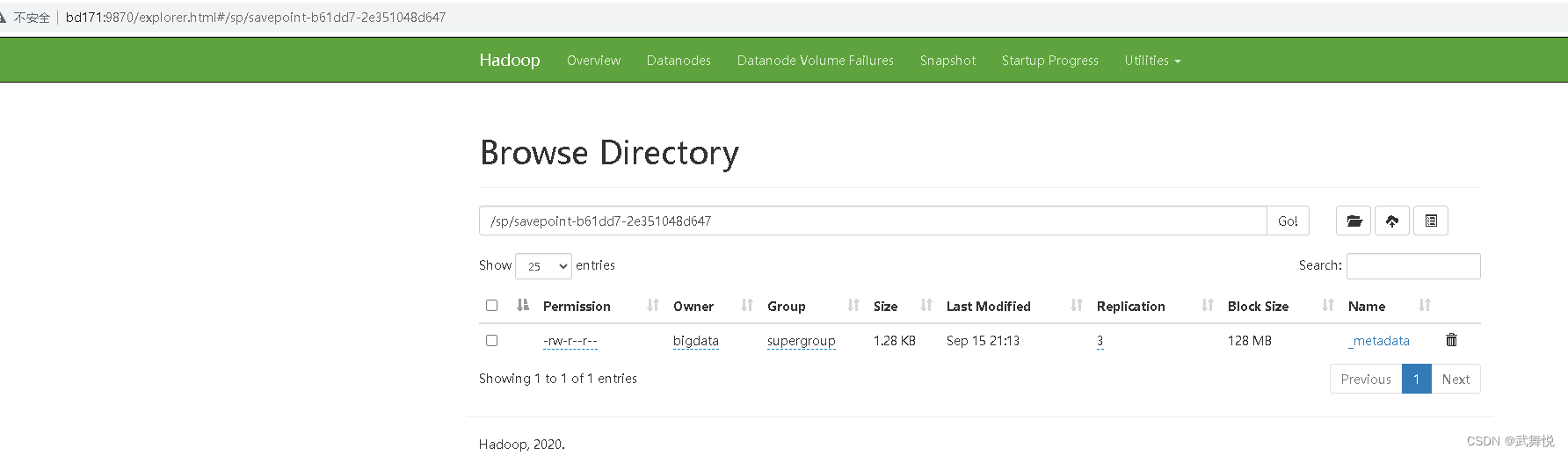
点击链接查看:
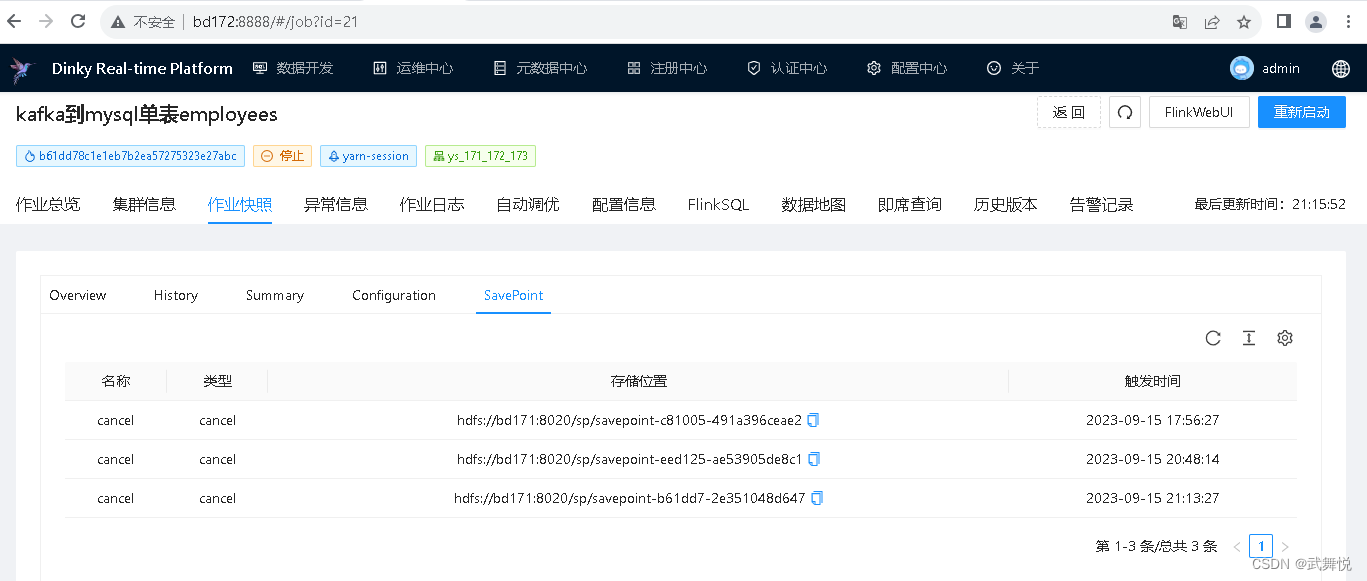
在dlink的运维中心,任务列表,任务详情页面,作业快照sheet下面的SavePoint这个Sheet下,也可以看到SavePoint保存的路径信息:
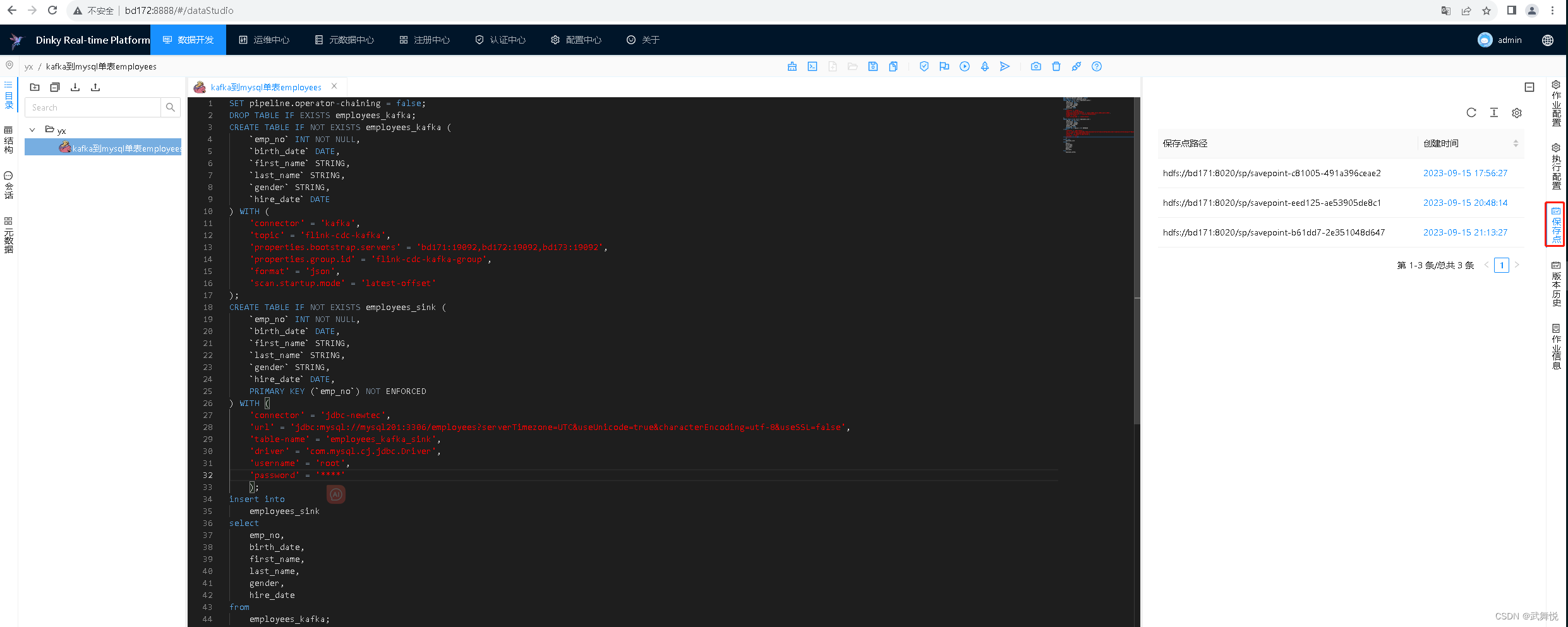
在dlink的数据开发的作业中, 右边“保存点”栏也可以查看到savepoint记录
2.4 向Kafka相关Topic接入300条记录
FlinlSQL作业当前是停止状态,此时,向Kafka相关Topic接入300条记录
2.5 重启作业
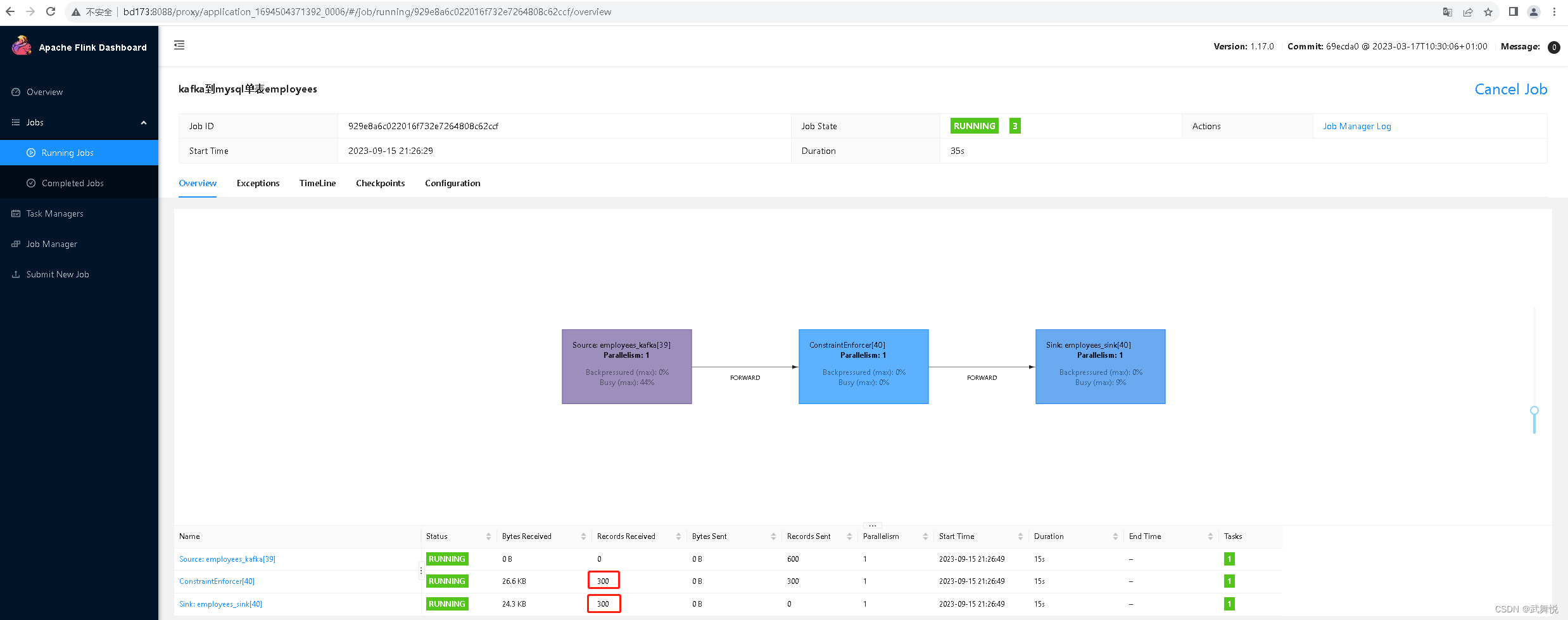
在dlink的运维中心,任务列表,任务详情页面,重启任务;任务重启完成后,可以看到,FlinlSQL作业实现了从SavePoint中的状态恢复,找到Kafka的正确偏移,在任务停止期间进行Kafka相关Topic中的数据,被FlinkSQL作业找到并读到到,最终写到了任务的Sink,MySQL数据库的相关表里:
3. 结论
dinky这个图形化的FlinkSQL开发工具,不仅简化了FlinkSQL的开发调试,还集成了对从SavePoint恢复作业运行的支持,非常方便。















 822
822











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









