







一、如何去构建Tensorflow model
Phase 1: 定义Tensorflow图
1. 给输入和输出定义placeholders
2. 定义weights
3. 定义推断模型
4. 定义损失函数
5. 定义优化器
Phase 2: 执行计算
1. 初始化所有的模型变量
2. 给placeholders传递数值
3. 模型在训练数据上开始运行
4. 计算损失
5. 调整模型参数去最大化或者最小化损失函数
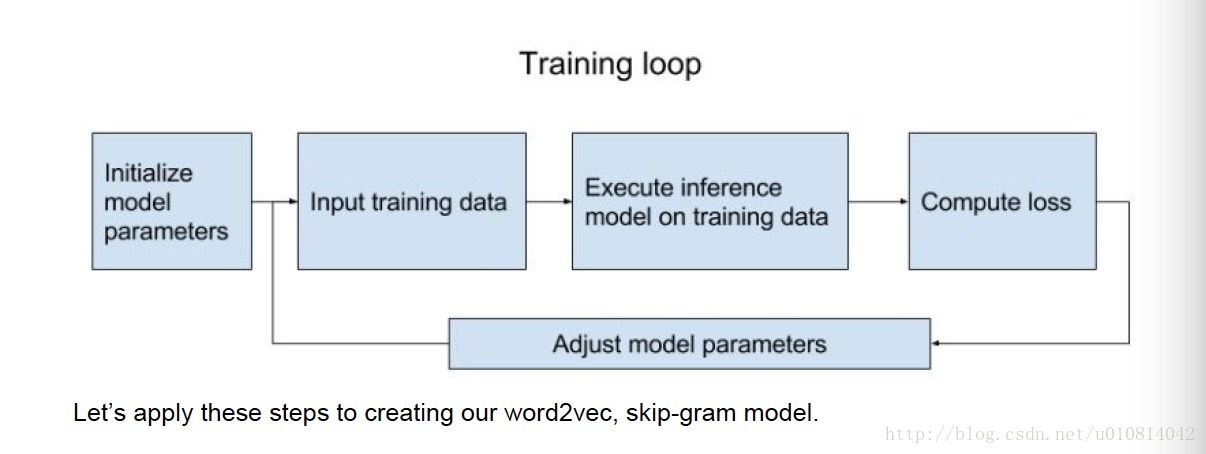
二、在Tensorflow中搭建word2vec模型
Phase 1: 定义Tensorflow图
1. 给输入和输出定义placeholders
首先确定BATCH_SIZE,也就是每次训练的样本数
center_words = tf.placeholder(shape=[BATCH_SIZE], dtype=tf.int32)
target_words = tf.placeholder(shape=[BATCH_SIZE], dtype=tf.int32)2. 定义weights
VOCAB_SIZE为特征的维数,初始范围为-1.0 到 1.0
embed_matrix = tf.Variable(tf.random_normal(shape=[VOCAB_SIZE, BATCH_SIZE]),\ -1.0, 1.0
)3. 定义前向传播图
params是embed_matrix, ids是词向量,用来选择embed_matrix中的其中一行,
tf.nn.embedding_lookup(params, ids, partition_strategy = 'mod' , name = None , validate_indices = True , max_norm = None)embed = tf.nn.embedding_lookup(embed_matrix, center_words)
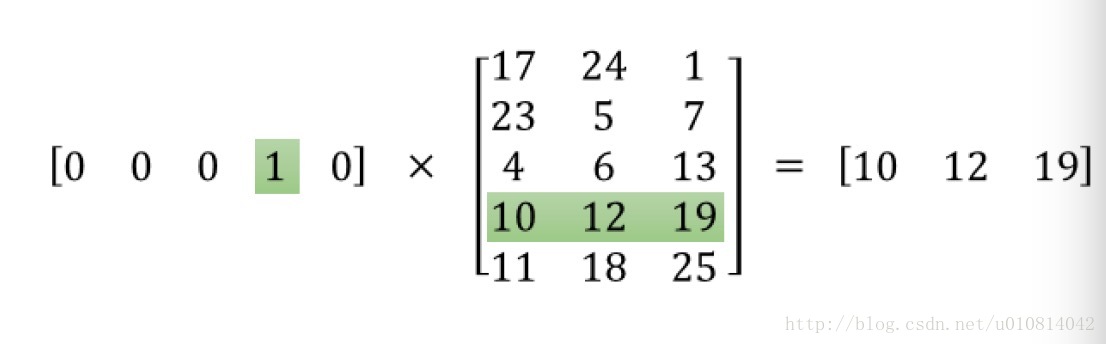
4. 定义损失函数
虽然NCE算法在python中实现比较困难,但Tensorflow已经帮我们封装好了
要注意的是labels参数对应的是真实的y值,inputs对应的是转化后的词向量。
tf.nn.nec_loss( weights, biases, labels, inputs, num_sampled, num_classes , num_true = 1, sampled_values = None , remove_accidental_hits = False , partition_strategy = 'mod', name = 'nce_loss')- weight.shape = (N, K) : 每一行对应着每一个词,叫做辅助向量
- bias.shape = (N)
- inputs.shape = (batch_size, K)
- labels.shape = (batch_size, num_true)
- num_true : 实际的正样本个数
- num_sampled: 采样出多少个负样本
- num_classes = N 有多少个不同的词
- sampled_values: 采样出的负样本,如果是None,就会用不同的sampler去采样。
- remove_accidental_hits: 如果采样时不小心采样到的负样本刚好是正样本,要不要去掉
- partition_strategy:对weights进行embedding_lookup时并行查表时的策略。TF的embeding_lookup是在CPU里实现的,这里需要考虑多线程查表时的锁的问题。
如果我们没有直接传递采样值给sampled_values, 则Tensorflow会帮我们使用一个sampler区采样。采样的函数如下所示
if sampled_values is None:
sampled_values = candidate_sampling_ops.log_uniform_candidate_sampler(
true_classes=labels,
num_true=num_true,
num_sampled=num_sampled,
unique=True,
range_max=num_classes)
- This operation randomly samples a tensor of sampled classes
- (sampled_candidates) from the range of integers [0, range_max).
P(k) = (log(k + 2) - log(k + 1)) / log(range_max + 1)
从上面这两句话中可以看出k越大,被抽样到的概率越小,那么k是怎么来的呢,看下面的源代码
def build_dataset(words):
count = [['UNK', -1]]
# 统计各个单词出现的次数
count.extend(collections.Counter(words).most_common(vocabulary_size - 1))
dictionary = dict() # 创建字典,用于保存各个单词出现的次数
for word, _ in count:
dictionary[word] = len(dictionary) # 词频高的,编号值小
data = list() # 将文章保存成编号的形式
unk_count = 0 # 没被计数的单词数
for word in words:
if word in dictionary:
index = dictionary[word] # 获取编号
else:
index = 0 # dictionary['UNK'] # 获取编号
unk_count += 1 # 没被计数的单词数+1
data.append(index)
count[0][1] = unk_count
reverse_dictionary = dict(zip(dictionary.values(), dictionary.keys()))
return data, count, dictionary, reverse_dictionary
通过分析上面的代码我们可知道词频越大的词,编号越小,就意味着被抽到的概率越大。
接下来需要定义一下nce_weight 和 nce_bias
# 每一行对应着每一个词,叫做辅助向量
nce_weight = tf.Variable(tf.truncated_normal([VOCAB_SIZE, EMBED_SIZE],
stddev=1.0/ EMBED_SIZE**0.5
))
nce_bias = tf.Variable(tf.zeros([VOCAB_SIZE]))
然后正式定义损失函数
loss = tf.reduce_mean ( tf.nn.nce_loss(weights = nce_weight,
biases = nce_bias,
labels = target_words,
inputs = embed,
num_sampled = NUM_SAMPLED,
num_classes = VOCAB_SIZE ))
5.定义优化器
我们使用最基本的梯度下降优化器
optimizer = tf.train.GradientDescentOptimizer(LEARNING_RATE).minimize (loss)
Phase 2: Execute the computation
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
average_loss = 0.0
for index in xrange(NUM_TRAIN_STEPS):
batch = batch_gen.next()
loss_batch, _ = sess.run([loss, optimizer],
feed_dict={center_words:batch[0], target_words:batch[1]})
if(index+1)%2000 == 0:
print('Average loss at step {}: {:5.1f}'.format(index=1,
average_loss/(index+1)))为了更好的可视化,我们需要添加上with tf . name_scope ( name_of_that_scope ), 这样能帮我们对Node进行分组:
完整代码如下所示
""" word2vec with NCE loss
and code to visualize the embeddings on TensorBoard
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import os
import numpy as np
from tensorflow.contrib.tensorboard.plugins import projector
import tensorflow as tf
from process_data import process_data
VOCAB_SIZE = 50000
BATCH_SIZE = 128
EMBED_SIZE = 128 # dimension of the word embedding vectors
SKIP_WINDOW = 1 # the context window
NUM_SAMPLED = 64 # Number of negative examples to sample.
LEARNING_RATE = 1.0
NUM_TRAIN_STEPS = 100000
WEIGHTS_FLD = 'processed/'
SKIP_STEP = 2000
class SkipGramModel:
""" Build the graph for word2vec model """
def __init__(self, vocab_size, embed_size, batch_size, num_sampled, learning_rate):
self.vocab_size = vocab_size
self.embed_size = embed_size
self.batch_size = batch_size
self.num_sampled = num_sampled
self.lr = learning_rate
self.global_step = tf.Variable(0, dtype=tf.int32, trainable=False, name='global_step')
def _create_placeholders(self):
""" Step 1: define the placeholders for input and output """
with tf.name_scope("data"):
self.center_words = tf.placeholder(tf.int32, shape=[self.batch_size], name='center_words')
self.target_words = tf.placeholder(tf.int32, shape=[self.batch_size, 1], name='target_words')
def _create_embedding(self):
""" Step 2: define weights. In word2vec, it's actually the weights that we care about """
# Assemble this part of the graph on the CPU. You can change it to GPU if you have GPU
with tf.device('/cpu:0'):
with tf.name_scope("embed"):
self.embed_matrix = tf.Variable(tf.random_uniform([self.vocab_size,
self.embed_size], -1.0, 1.0),
name='embed_matrix')
def _create_loss(self):
""" Step 3 + 4: define the model + the loss function """
with tf.device('/cpu:0'):
with tf.name_scope("loss"):
# Step 3: define the inference
embed = tf.nn.embedding_lookup(self.embed_matrix, self.center_words, name='embed')
# Step 4: define loss function
# construct variables for NCE loss
nce_weight = tf.Variable(tf.truncated_normal([self.vocab_size, self.embed_size],
stddev=1.0 / (self.embed_size ** 0.5)),
name='nce_weight')
nce_bias = tf.Variable(tf.zeros([VOCAB_SIZE]), name='nce_bias')
# define loss function to be NCE loss function
self.loss = tf.reduce_mean(tf.nn.nce_loss(weights=nce_weight,
biases=nce_bias,
labels=self.target_words,
inputs=embed,
num_sampled=self.num_sampled,
num_classes=self.vocab_size), name='loss')
def _create_optimizer(self):
""" Step 5: define optimizer """
with tf.device('/cpu:0'):
self.optimizer = tf.train.GradientDescentOptimizer(self.lr).minimize(self.loss,
global_step=self.global_step)
def _create_summaries(self):
with tf.name_scope("summaries"):
tf.summary.scalar("loss", self.loss)
tf.summary.histogram("histogram_loss", self.loss)
# because you have several summaries, we should merge them all
# into one op to make it easier to manage
self.summary_op = tf.summary.merge_all()
def build_graph(self):
""" Build the graph for our model """
self._create_placeholders()
self._create_embedding()
self._create_loss()
self._create_optimizer()
self._create_summaries()
def train_model(model, batch_gen, num_train_steps, weights_fld):
saver = tf.train.Saver() # defaults to saving all variables - in this case embed_matrix, nce_weight, nce_bias
initial_step = 0
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
ckpt = tf.train.get_checkpoint_state(os.path.dirname('checkpoints/checkpoint'))
# if that checkpoint exists, restore from checkpoint
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
total_loss = 0.0 # we use this to calculate late average loss in the last SKIP_STEP steps
writer = tf.summary.FileWriter('improved_graph/lr' + str(LEARNING_RATE), sess.graph)
initial_step = model.global_step.eval()
for index in xrange(initial_step, initial_step + num_train_steps):
centers, targets = batch_gen.next()
feed_dict={model.center_words: centers, model.target_words: targets}
loss_batch, _, summary = sess.run([model.loss, model.optimizer, model.summary_op],
feed_dict=feed_dict)
writer.add_summary(summary, global_step=index)
total_loss += loss_batch
if (index + 1) % SKIP_STEP == 0:
print('Average loss at step {}: {:5.1f}'.format(index, total_loss / SKIP_STEP))
total_loss = 0.0
saver.save(sess, 'checkpoints/skip-gram', index)
####################
# code to visualize the embeddings. uncomment the below to visualize embeddings
final_embed_matrix = sess.run(model.embed_matrix)
# # it has to variable. constants don't work here. you can't reuse model.embed_matrix
embedding_var = tf.Variable(final_embed_matrix[:1000], name='embedding')
sess.run(embedding_var.initializer)
config = projector.ProjectorConfig()
summary_writer = tf.summary.FileWriter('processed')
# # add embedding to the config file
embedding = config.embeddings.add()
embedding.tensor_name = embedding_var.name
# # link this tensor to its metadata file, in this case the first 500 words of vocab
embedding.metadata_path = 'processed/vocab_1000.tsv'
# # saves a configuration file that TensorBoard will read during startup.
projector.visualize_embeddings(summary_writer, config)
saver_embed = tf.train.Saver([embedding_var])
saver_embed.save(sess, 'processed/model3.ckpt', 1)
def main():
model = SkipGramModel(VOCAB_SIZE, EMBED_SIZE, BATCH_SIZE, NUM_SAMPLED, LEARNING_RATE)
model.build_graph()
batch_gen = process_data(VOCAB_SIZE, BATCH_SIZE, SKIP_WINDOW)
train_model(model, batch_gen, NUM_TRAIN_STEPS, WEIGHTS_FLD)
if __name__ == '__main__':
main()














 1669
1669

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









