







word2vec
当我们处理自然语言问题的时候,通常会做分词,然后给每一个词一个编号,比如猫的编号是120,编号是没有规律,没有联系的,从编号中不能得到词与词的相关性。
- CBOW: 连续词袋模型
根据此的上下文词汇来预测目标词汇。 - skip-gram模型
- 通过目标词汇来预测上下文词汇。
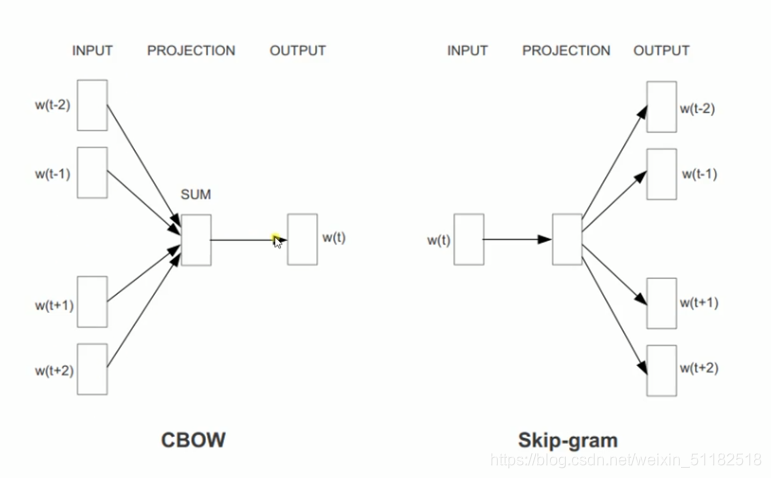
每个词都会有一个固定维度的向量,代表这个词蕴涵的信息,输入这个vector就可以到的output。
1、使用噪声对比估计训练word2vec
使用softmax作为输出层是可行的,但数据量会很大,假如一直上下文,需要预测目标词汇,假设有50000个词汇,那么每次计算输出层都要计算50000个概率值。
所以训练word2vec模型我们通常可以选择使用噪声对比估计,NCE使用的方法是把上下文h对应地正确的目标词汇标记为正样本(D=1), 然后再抽取一些错误的词汇作为负样本(D=0)。然后最大化目标函数的值。
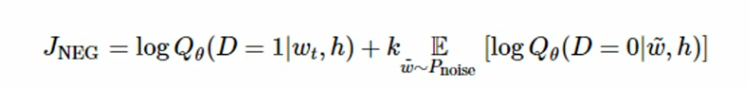
当真实的目标单词被分配到较高的概率,同时噪声单词的概率很低时,目标函数也达到了最大值。计算这个函数时,只需要计算挑选出来的k个噪声单词,而不是整个语料库,所以训练速度会很快。
2、word2vec图形化

在word vector的高维空间中,词性相近的词会被映射到很近的区间,从而,context information可以被有效地表达。
3、在tensorflow中使用word2vec
import tensorflow as tf
# encoding=utf8
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import collections
import math
import os
import random
import zipfile
import numpy as np
from six.moves import urllib
from six.moves import xrange # pylint: disable=redefined-builtin
import tensorflow as tf
# Step 1: Download the data.
url = 'http://mattmahoney.net/dc/'
# 下载数据集
def maybe_download(filename, expected_bytes):
"""Download a file if not present, and make sure it's the right size."""
if not os.path.exists(filename):
filename, _ = urllib.request.urlretrieve(url + filename, filename)
# 获取文件相关属性
statinfo = os.stat(filename)
# 比对文件的大小是否正确
if statinfo.st_size == expected_bytes:
print('Found and verified', filename)
else:
print(statinfo.st_size)
raise Exception(
'Failed to verify ' + filename + '. Can you get to it with a browser?')
return filename
filename = maybe_download('text8.zip', 31344016)
# Read the data into a list of strings.
def read_data(filename):
"""Extract the first file enclosed in a zip file as a list of words"""
with zipfile.ZipFile(filename) as f:
data = tf.compat.as_str(f.read(f.namelist()[0])).split()
return data
# 单词表
words = read_data(filename)
# Data size
print('Data size', len(words))
# Step 2: Build the dictionary and replace rare words with UNK token.
# 只留50000个单词,其他的词都归为UNK
vocabulary_size = 50000
def build_dataset(words, vocabulary_size):
count = [['UNK', -1]]
# extend追加一个列表
# Counter用来统计每个词出现的次数
# most_common返回一个TopN列表,只留50000个单词包括UNK
# c = Counter('abracadabra')
# c.most_common()
# [('a', 5), ('r', 2), ('b', 2), ('c', 1), ('d', 1)]
# c.most_common(3)
# [('a', 5), ('r', 2), ('b', 2)]
# 前50000个出现次数最多的词
count.extend(collections.Counter(words).most_common(vocabulary_size - 1))
# 生成 dictionary,词对应编号, word:id(0-49999)
# 词频越高编号越小
dictionary = dict()
for word, _ in count:
dictionary[word] = len(dictionary)
# data把数据集的词都编号
data = list()
unk_count = 0
for word in words:
if word in dictionary:
index = dictionary[word]
else:
index = 0 # dictionary['UNK']
unk_count += 1
data.append(index)
# 记录UNK词的数量
count[0][1] = unk_count
# 编号对应词的字典
reverse_dictionary = dict(zip(dictionary.values(), dictionary.keys()))
return data, count, dictionary, reverse_dictionary
# data 数据集,编号形式
# count 前50000个出现次数最多的词
# dictionary 词对应编号
# reverse_dictionary 编号对应词
data, count, dictionary, reverse_dictionary = build_dataset(words, vocabulary_size)
del words # Hint to reduce memory.
print('Most common words (+UNK)', count[:5])
print('Sample data', data[:10], [reverse_dictionary[i] for i in data[:10]])
data_index = 0
# Step 3: Function to generate a training batch for the skip-gram model.
def generate_batch(batch_size, num_skips, skip_window):
global data_index
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3287
3287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









