









写在前面:本教程对计算机硬件要求较高,教程中使用了AWS提供的服务.
训练一个具有大量图像的神经网络会带来一些挑战。即使使用最新的GPU,也不可能在合理的时间内使用单个GPU来训练大型网络。在一台机器中使用多个gpu可以稍微减轻这个问题。但是,可以连接到一台机器上的gpu的数量是有限的(通常为8或16)。本教程解释了如何使用多个包含多个gpu的多台机器来训练大的网络,使用tb级的数据。
Note:This blog without all the resources that are outside the original,reproduced please indicate the source.
官网:mxnet.incubator.apache.org,文中如有任何错漏的地方请谅解并指出,不胜感激.
准备
想与之前几个教程相似:
- 安装MXNet
- OpenCV python库
$ pip install opencv-python
处理
磁盘空间
对大数据进行培训的第一步是下载数据并进行预处理。对于本教程,我们将使用完整的ImageNet数据集。请注意,至少需要2 TB的磁盘空间来下载和预处理这些数据。强烈建议使用SSD代替HDD。SSD更擅长处理大量的小图像文件。在预处理完成并将图像打包成recordIO文件后,HDD应该可以接受训练。
在本教程中,我们将使用AWS存储实例进行数据预处理。存储实例i3.4xlarge在两个NVMe SSD磁盘上有3.8 TB的磁盘空间。我们将使用软件RAID将它们组合成一个磁盘并在~/data上挂载它。
sudo mdadm --create --verbose /dev/md0 --level=stripe --raid-devices=2 \
/dev/nvme0n1 /dev/nvme1n1
sudo mkfs /dev/md0
sudo mkdir ~/data
sudo mount /dev/md0 ~/data
sudo chown ${whoami} ~/data我们现在有足够的磁盘空间来下载和预处理数据。
下载ImageNet
在本教程中,我们将使用完整的ImageNet数据集,可以从http://www.image-net.org/download-images下载。fall11_whole。tar包含所有的图像。该文件的大小为1.2 TB,需要很长时间才能下载。
下载后,解压文件。
export ROOT=full
mkdir $ROOT
tar -xvf fall11_whole.tar -C $ROOT这应该会给您一个tar文件的集合。每个tar文件表示一个类别,并包含属于该类别的所有图像。我们可以解压缩每个tar文件并将图像复制到一个以tar文件名称命名的文件夹中。
for i in $ROOT/*.tar; do j=${i%.*}; echo $j; mkdir -p $j; tar -xf $i -C $j; done
rm $ROOT/*.tar
ls $ROOT | head
n00004475
n00005787
n00006024
n00006484
n00007846
n00015388
n00017222
n00021265
n00021939
n00120010删除不常见的转移学习类(可选)
在ImageNet数据上训练网络的一个常见原因是用于传输学习(包括特征提取或对其他模型进行微调)。根据这项研究,没有图片的类在转移学习上没有帮助。因此,我们可以删除一些少于一定数量图像的类。下面的代码将删除少于500个图像的类。
BAK=${ROOT}_filtered
mkdir -p ${BAK}
for c in ${ROOT}/n*; do
count=`ls $c/*.JPEG | wc -l`
if [ "$count" -gt "500" ]; then
echo "keep $c, count = $count"
else
echo "remove $c, $count"
mv $c ${BAK}/
fi
done生成验证组
为了确保我们不超过数据,我们将创建一个独立于训练集的验证集。在培训期间,我们将频繁地监视验证集上的损失。我们通过从每个类中挑选50个随机图像并将它们移动到验证集来创建验证集。
VAL_ROOT=${ROOT}_val
mkdir -p ${VAL_ROOT}
for i in ${ROOT}/n*; do
c=`basename $i`
echo $c
mkdir -p ${VAL_ROOT}/$c
for j in `ls $i/*.JPEG | shuf | head -n 50`; do
mv $j ${VAL_ROOT}/$c/
done
done将图像压缩到记录文件中
虽然MXNet可以直接读取图像文件,但建议将图像文件打包到一个recordIO文件中以提高性能。MXNet提供了一个工具(工具/ im2rec.py)来完成这个任务。要使用这个工具,需要在系统中安装MXNet和OpenCV的python模块。
将环境变量MXNET设置为指向MXNET安装目录,并将其命名为数据集的名称。在这里,我们假设MXNet安装在~ / MXNet中
MXNET=~/mxnet
NAME=full_imagenet_500_filtered为了创建recordIO文件,我们首先在recordIO文件中创建我们想要的图像列表,然后使用im2rec将列表中的图像打包到recordIO文件中。我们在train_meta创建这个列表。培训数据在1TB左右。我们把它分成8个部分,每个部分大约有100 GB大小。
mkdir -p train_meta
python ${MXNET}/tools/im2rec.py --list True --chunks 8 --recursive True \
train_meta/${NAME} ${ROOT}然后我们调整图像大小,使短边是480像素,并将图像打包成recordIO文件。由于大部分工作是磁盘I / O,所以我们使用多个(16)线程来更快地完成工作。
python ${MXNET}/tools/im2rec.py --resize 480 --quality 90 \
--num-thread 16 train_meta/${NAME} ${ROOT}完成后,我们将rec文件移动到名为train的文件夹中。
mkdir -p train
mv train_meta/*.rec train/我们对验证集进行类似的预处理。
mkdir -p val_meta
python ${MXNET}/tools/im2rec.py --list True --recursive True \
val_meta/${NAME} ${VAL_ROOT}
python ${MXNET}/tools/im2rec.py --resize 480 --quality 90 \
--num-thread 16 val_meta/${NAME} ${VAL_ROOT}
mkdir -p val
mv val_meta/*.rec val/现在,我们已经在训练和val目录中分别使用了recordIO格式的训练和验证图像。我们现在可以用这些了。rec文件培训。
训练
ResNet已经展示了它在ImageNet竞争中的有效性。我们的实验也重现了报告中的结果。当我们将层数从18层增加到152层时,我们看到验证精度的稳步提高。鉴于这是一个巨大的数据集,我们将使用具有152层的Resnet。
由于计算复杂度很高,即使是最快的GPU也需要超过一天的时间来处理数据。在训练收敛到良好的验证精度之前,我们通常需要几十个epoch。虽然我们可以在机器中使用多个gpu,但机器中gpu的数量通常限制在8或16。为了加快训练,在本教程中,我们将使用多个包含多个gpu的机器来训练模型。
设置
我们将使用16台机器(p2.16 x实例),每个机器包含16个gpu(特斯拉K80)。这些机器通过20 Gbps以太网相互连接。
AWS云的形成使得创建深度学习集群非常容易。我们遵循这个页面的指示,并创建一个具有16个p2.16 x实例的深度学习集群。
我们在第一个机器中加载数据和代码(我们将此机器称为master)。我们将数据和代码共享给其他使用EFS的机器。
如果您正在手动设置集群,而不使用AWS cloud编组,请记住以下步骤:
使用USE_DIST_KVSTORE = 1编译MXNet,以支持分布式培训。
在master中创建一个包含所有集群机器主机名的主机文件。例如,
$ head -3 hosts
deeplearning-worker1
deeplearning-worker2
deeplearning-worker3通过从文件中调用ssh,可以通过调用ssh来从主ssh到这些机器中的任何一个。例如,
$ ssh deeplearning-worker2
===================================
Deep Learning AMI for Ubuntu
===================================
...
ubuntu@ip-10-0-1-199:~$其中一种方法是使用`ssh`代理转发。请查看本页,了解如何设置。简而言之,您将使用本地机器上的特定证书(`mycert.pem`)配置所有计算机登录。然后使用证书和`- a`开关登录到主服务器,以启用代理转发。现在,您应该能够通过提供主机名(例如`ssh`深度学习`- worker2`)登录到集群中的任何其他机器。
运行训练
在集群设置之后,从$ {MXNET}/example/ image分类中登录到master并运行以下命令
../../tools/launch.py -n 16 -H $DEEPLEARNING_WORKERS_PATH python train_imagenet.py --network resnet \
--num-layers 152 --data-train ~/data/train --data-val ~/data/val/ --gpus 0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15 \
--batch-size 8192 --model ~/data/model/resnet152 --num-epochs 1 --kv-store dist_sync运行.py启动集群中所有机器中提供的命令。必须提供集群中机器的列表。py使用- h开关。这里是用于launch. py的选项的描述。
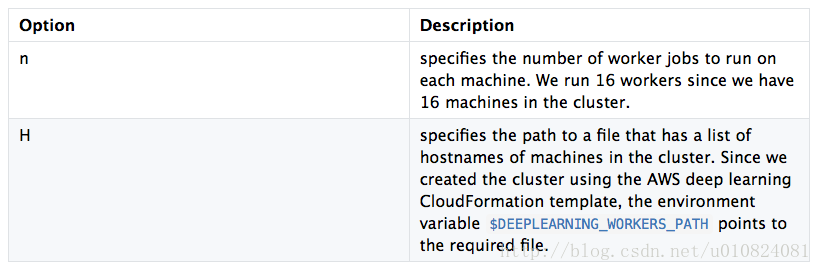
train_imagenet.py使用--data-train 和 --data-val 选项提供的数据来训练--network选项提供的网络。这里是train_imagenet.py中使用的选项的描述。
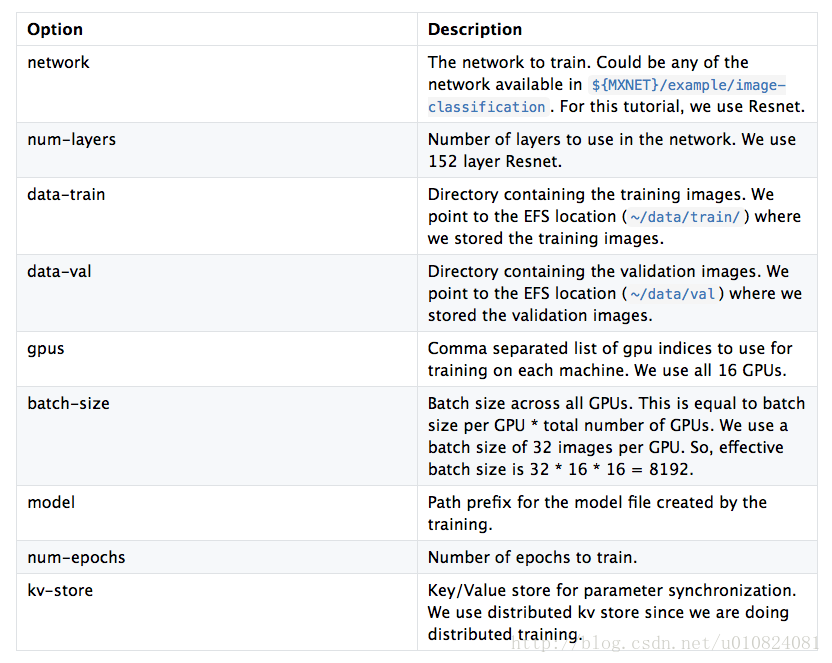
训练完成后,--model选项指定目录中可用的已经训练的模型。模型被保存在两个部分:定义网络的model-symbol.json和n次训练后保存参数的model-n.params。
可伸缩性
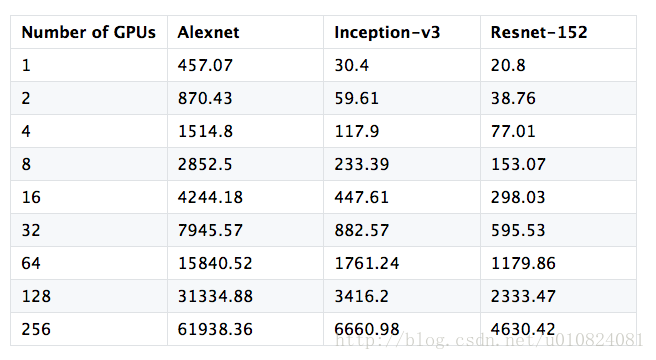
使用大量机器进行训练的一个常见问题是可伸缩性。我们在集群上运行几个流行的网络,有多达256个gpu,而且速度非常接近理想。
这个可伸缩性测试运行在16个p2.16 xl的实例上,总共有256个gpu。我们使用了AWS深度学习AMI和CUDA 7.5和CUDNN 5.1安装。
我们固定了每GPU的批量大小,并在以后的测试中增加GPU的数量。同步的SGD(- kv-store dist_device_sync)被使用。所使用的CNNs位于这里。

每秒处理的图像数如下表所示:
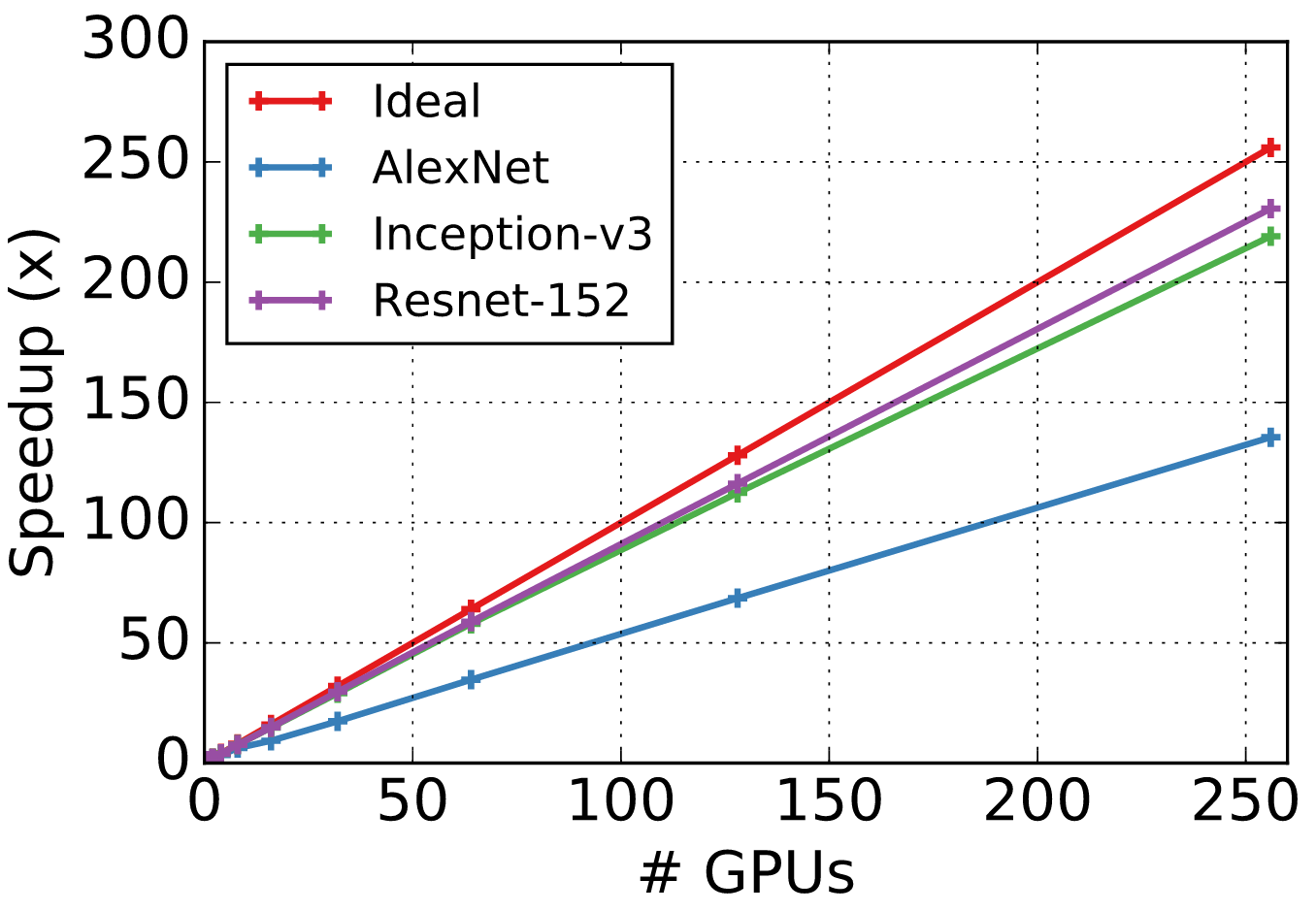
下图显示了对使用的gpu数量的加速,并将其与理想的加速进行比较。
故障排除指南
验证准确性
实现一个合理的验证精度通常很简单,但要达到报告中所报告的最先进的数字有时是非常困难的。这里有几件事你可以试着提高验证的准确性。
- 增加更多的数据增强通常会减少训练和确认准确度之间的差距。数据增加可以在更接近尾声的时期减少。
- 从一个大的学习速率开始,并保持长时间的学习。例如,在CIFAR10中,您可以将第一个200个epochs的学习速率保持在0.1,然后将其降低到0.01。
- 不要使用规模太大的批处理大小,特别是批大小> >的类。
速度
- 分布式培训提高了批量计算成本的速度。所以,要确保你的工作量不是太小(就像在MNIST上的LeNet一样)。确保批量大小相当大。
- 确保数据读取和预处理不是瓶颈。使用
——test-io 1标志检查每秒处理多少图像。 - 增加- data- nthreads(默认值是4)以使用更多的线程来进行数据预处理。
- 数据预处理是由opencv完成的。如果opencv是从源代码编译的,请检查它是否配置正确。
- 使用
--benchmark 1使用随机生成的数据,而不是实际数据,以缩小瓶颈所在的位置。 - 查看此页面了解更多细节。
内存
如果批大小太大,就会耗尽GPU内存。如果发生这种情况,您将看到错误消息“cudaMalloc failed:out of memory”或类似的东西。有几种方法可以解决这个问题:
- 减少批量大小。
- 将环境变量
MXNET_BACKWARD_DO_MIRROR设置为1。它通过降低速度来减少内存消耗。例如,在批处理大小为64的情况下,incepa- v3使用10G内存,在一个K80 GPU上训练30个图像/秒。当镜像启用时,使用10G GPU内存消耗,我们可以使用128的批大小运行incepa - v3。成本是这样的,速度降低到27张图片/秒。














 6097
6097











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









