










正文
今天来分享EM算法,几个月前,通过阅读各种文献终于对EM算法有了较为清晰的认识,一直就想写篇博客总结一些,可惜拖延症拖延至今(QAQ)。
期望最大算法(EM算法)是一种从不完全数据或有数据丢失的数据集(存在隐含变量)中求解概率模型参数的最大似然估计方法。先大体知道这么回事,理解了整篇文章再回来品读这句话。
必备知识
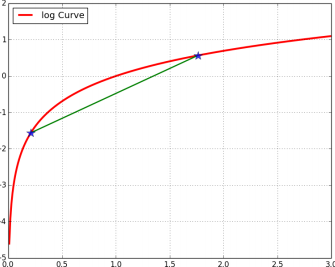
jenson不等式
jenson不等式以丹麦数学家(Johan Jensen)命名。它给出积分的凸函数值和凸函数的积分值间的关系。jenson不等式的具体内容是啥呢?
若f(x)在(a,b)之间是凸函数,那么:
其中\(\theta_1,\theta_2,…,\theta_k\geq0,\sum_{i=1}^k\theta_i=1\)
对于连续函数:
若 \(p(x)>0 \quad on \quad S\subseteq dom f, \int_Sp(x)dx=1\)
则:
Jensen不等式是关于凸性(convexity)的不等式。凸性是一个很好的性质,在最优化问题里面,线性和非线性不是本质的区别,只有凸性才是。如果最优化的函数是凸的,那么局部最优就意味着全局最优,否则无法推得全局最优。有很多不等式都可以用Jensen不等式证得,从而可以把他们的本质归结为凸性。例如,均值不等式:
本质上可以归结为对数函数log(x)的凸性。
聚类
首先让我们回忆一下k-means算法。
k-means算法,也叫k-平均或者k-均值算法,是一种广泛使用的聚类算法,其经常作为很多聚类算法的基础。
假设输入样本为 \(S=x_1,x_2,…,x_m\)
那么算法步骤为:
* 选择初始的k个簇中心: \(\mu_1,\mu_2,…\mu_k\)
* 将每个样本x标记为距离簇中心最近的簇:
* 更新簇中心:
* 重复最后两个步骤,指导满足终止条件。
终止条件有很多,可以使用
迭代次数,
簇中心变化率,
最小平方误差MSE。
现在来思考一下,经典的
k-means算法可以很方便的将未标记的样本分成多个集合,但并不能给出一个样本属于某一个集合的后验概率,当然咱们可以使用一些类似SVM中的方式得到类似于概率的数值。
最大似然估计
最大似然估计属于统计学的内容,其常常用来估计样本的分布,找出与样本分布最接近的概率分布模型,它是一种非参数估计。其简单有效的估计方式使得其在应用中占据重要地位。
假如小红有一枚硬币,她抛了十次,结果分别是,正反反正反反反反正反
假设p为每次抛硬币结果为正的概率,则出现上面结果的概率为:
重点来了,最大似然概率的思想就是最大化似然概率,什么是似然概率,似然概率就是出现当前样本的概率,也就是上面的概率P,那么怎么最大化上面的概率P呢?小时候学的微积分派上用场了:一阶导为0求极点…。可以求得上式的最优解为:
p=0.3
上面的整个思路历程就是最大似然估计的全过程。
将上面的例子更泛化一点,投N次硬币,得到结果,其中n次朝上,N-n次朝下。
假定朝上概率为p,则似然函数为:
因为对数函数是严格单增,为了方便计算,通常将似然函数变为对数似然函数计算:
求最大:
更进一步的,给定一组样本\(x_1,x_2,…,x_n\),已知他们来自于高斯分布\(N(\mu,\sigma)\),试估计\(\mu,\sigma\)
写出似然函数:
已知高斯分布的概率密度函数为:
则似然函数为:
对数似然:
最大化似然函数,分别对\(\mu和\sigma\)求偏导求极值得:
可以发现咱们使用最大似然估计得到\(\mu和\sigma\)的值很符合直观想象:样本的均值就是高斯分布的均值,样本的方差就是高斯分布的方差。
提出问题
然而我们遇到的问题的随机变量有的时候是无法直接观察到的。比如:有N个人,其中有男性有女性,他们的身高分别服从\(N(\mu_1,\sigma_1)\)和\(N(\mu_2,\sigma_2)\)分布,要估计\(\mu_1,\sigma_1,\mu_2,\sigma_2\)。
我们如果知道哪些是男性哪些是女性就好了,只需要分别对他们使用上面的最大似然估计。但是遗憾的是我们并不知道,因此我们需要使用EM算法。想一想这个问题,我们也可以先对数据进行聚类,得到男性和女性两类,再分别建模。待我们学完EM算法,我们会发现其实两种方法的思想是相似的。最后我们会分析一下k-means和EM算法的关系。
上面的问题包含两个高斯模型,因此这类问题又称为高斯混合模型(GMM),高斯混合模型是EM算法解决问题的一个基本问题。
GMM的直观解法
随机变量X是由K个高斯分布混合而成,取各个高斯分布的概率为\(\pi_1,\pi_2,…,\pi_K\),第i个高斯分布的均值为\(\mu_i\),方差为\(\sum_i\)。随机变量X的一组样本为\(x_1,x_2,…,x_n\),估计参数\(\pi,\mu,\sum\)。
按上面的步骤计算,先写出似然函数:
取对数:
显然上面的式子无法直接用求导的方式找最大值,为了解决这个问题,我们将问题分为两步:
* 估计数据来自哪一部分
对于每个样本\(x_i\),它由第k个高斯分布生成的概率为:
注意上面的式子中的\(\mu和\sigma\)也是待估计的值,因此采用采样迭代法:首先先验的给出\(\mu和\sigma\),然后计算\(\gamma\),再通过计算出的\(\gamma\)计算\(\mu和\sigma\),重复达到收敛即可。
这里的\(\gamma(i,k)\)也可以看做第k个高斯分布在生成数据\(x_i\)时所做的贡献。
上面已经粗略的说了计算的步骤,那么\(\mu和\sigma\)怎么由\(\gamma\)计算呢?
* 估计每个高斯分布的参数
对于每个高斯分布\(N_k\)而言,可以看做由它生成了\({\gamma(i,k)x_i|i=1,2,…,n}\)这些点。由于是高斯分布,所以直接使用前面讨论过的结果即可:
得到:
重复上面的两步,达到收敛条件(各参数无明显变化等)即可。这就是EM算法的直观过程。
EM算法
假设有数据集\({x_1,x_2,…,x_n}\)包含m个独立样本,希望从中找到该组数据的模型\(p(x,z)\)的参数。
写出对数似然:
z是隐随机变量,不方便直接找到参数估计。因此使用一个求最大值时常用的一个策略:计算\(l(\theta)\)的下界,求这个下界的最大值;重复这个过程,直到收敛到局部最大值。先求到的下界有可能比较宽松,不断重复,使得精度提升,使得求到的下界更紧,从而最终接近真实结果。
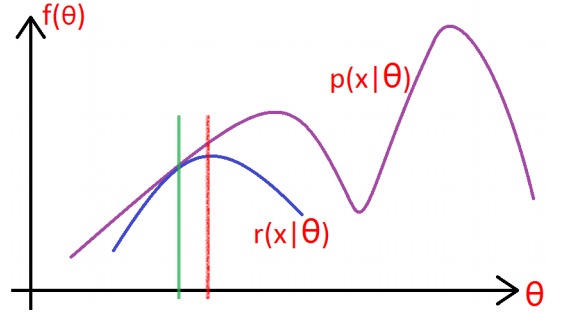
令\(Q_i\)是z的某一个分布,\(Q_i\geq0\),使用jenson不等式:
为了取等号,使得:
由此:
如此我们就得到EM算法的整体框架:
* E-step 对于每个i,令\(Q_i(z_i)=p(z_i;x_i,\theta)\)
* M-step 求\(\theta=argmax_{\theta}\sum_i\sum_{z_i}Q_i(z_i)log\frac{p(x_i,z_i;\theta)}{Q_i(z_i)}\)
重复进行上述两个步骤直至收敛。
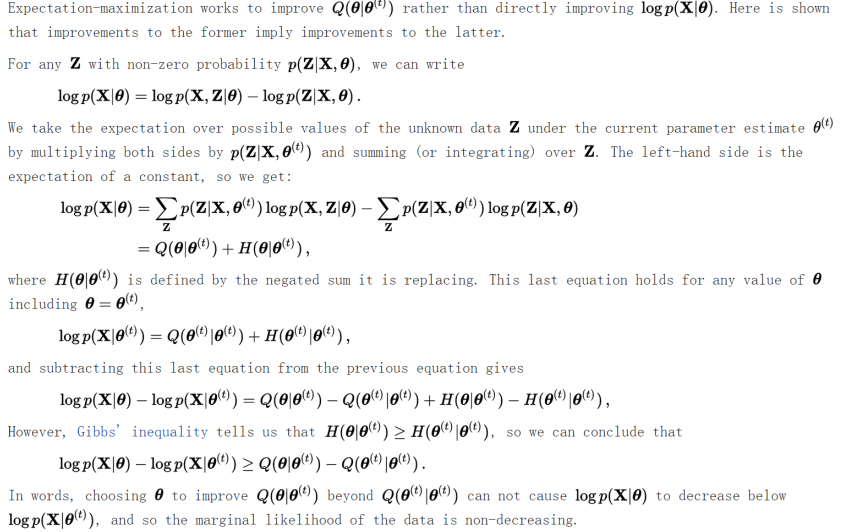
至于EM算法的收敛性证明,我就不说了,直接上从网上找的一段证明:
使用EM算法解决GMM问题
还记得咱们刚开始推到的GMM问题的解决方法吗?咱们当时是通过计算每一个高斯分布在每一个数据中占的比例估计每一个高斯分布的样本数据,然后再估计高斯分布的参数。现在咱们使用上面推导的EM算法解决一些这个问题。
随机变量X是由K个高斯分布混合而成,取各个高斯分布的概率为\(\varphi_1,\varphi_2,…,\varphi_K\),第i个高斯分布的均值为\(,u_i\),方差为\(\sum_i\)。若观测到随机变量X的一系列样本\(x_1,x_2,…,x_n\),试估计参数\(\phi,\mu,\sum\)。
* E-step \(Q_i(z_i=j)=P(z_i=j|x_i;\phi,\mu,\sum)\)
* M-step 将多项式分布和高斯分布的参数带入:
对均值求导:
令等式为0,得到均值为:
同理可以求得方差:
现在来估计多项式分布\(\phi\)的分布:
因为咱们是要估计\(\phi\),因此先删除无关的常数项,化简为:
概率的归一性,建立拉格朗日方程:
有log函数在,求解到的\(\varphi_i\)一定是正的,因此不用考虑\(\varphi_i\)这个条件。
求偏导,赋为0,得:
由此:
这样就得到了结果:
直观的看我们用EM算法求到的结果和前面的直观解法得到的结果不太一样,但是他们其实是一样的。(仔细想想!!!)
EM算法的另一种理解
其实EM算法可以看做坐标上升。所谓坐标上升就是每次通过更新函数中的一维,通过多次的迭代以达到优化函数的目的。
上面的J就是前面咱们推到出的EM算法的目标函数。E-step就是在Q维上最大化J,M-step就是在\(\theta\)上最大化J。
k-means和EM算法的关系
可以发现EM算法的过程跟k-means算法的过程非常相似,都是先确定一个,更新另一个,再重新更新第一个,反复进行到收敛。实际上,k-means就是EM算法的一个实现。在k-means中先是假定隐含变量类别并将某一类别赋给每一个样例,这个过程就是E-step,M-step通过确定好的类别对其每个类的参数进行优化(这里就是更新类中心并重新分配类别)。
总的来说,EM算法就是使用极大似然估计的方法,通过坐标上升的优化方法对隐变量和显变量的联合分布就行求最值的过程。
好了,EM学完了,不得不说,EM算法中包含的东西真多啊!下一个准备学习的是—->LDA。















 2681
2681











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









