







每一个 partition(文件夹)相当于一个巨型文件被平均分配到多个大小相等segment(段)数据文件里。
但每一个段segment file消息数量不一定相等,这样的特性方便old segment file高速被删除。(默认情况下每一个文件大小为1G)
每一个 partiton仅仅须要支持顺序读写即可了。segment文件生命周期由服务端配置參数决定。
partiton中segment文件存储结构:
segment file组成:由2大部分组成,此2个文件一一相应,成对出现。
- 索引文件index file:后缀
.index - 数据文件data file:后缀
.log
segment文件命名规则:partion全局的第一个segment从0开始,兴许每一个segment文件名称为上一个segment文件最后一条消息的offset值。
数值最大为64位long大小。19位数字字符长度,没有数字用0填充。
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ ll /tmp/kafka/log/heima-0/ # 0号分区
total 20480
-rw-r--r-- 1 itcast sudo 10485760 Aug 29 09:38 00000000000000000000.index
-rw-r--r-- 1 itcast sudo 0 Aug 29 09:38 00000000000000000000.log
-rw-r--r-- 1 itcast sudo 10485756 Aug 29 09:38 00000000000000000000.timeindex
-rw-r--r-- 1 itcast sudo 8 Aug 29 09:38 leader-epoch-checkpoint
2 日志索引
2.1 数据文件的分段
kafka姐姐查询效率的手段之一就是将数据文件分段,比如有100条消息,他们的offset是从0到99。面,数据文件以该段中最小的offset命名。这样在查找指定offset的Message的时候,用二分查找就可以定位到该Message在哪个段中
2.2 偏移量索引
数据文件分段使得可以在一个较小的数据文件中查找对应offset的Message了,但是这依然需要顺序扫描才能找到对应offset的Message。为了进一步提高查找的效率,Kafka为每个分段后的数据文件建立了索引文件,文件名与数据文件的名字是一样的,只是文件扩展名为.index。
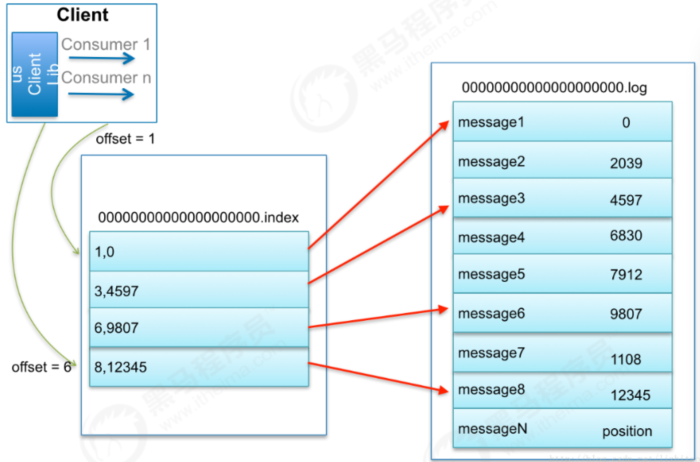
比如:要查找绝对 offset为7的Message:
首先是用二分查找确定它是在哪个LogSegment中,自然是在第一个Segment中。 打开这个Segment的index文件,也是用二分查找找到offset小于或者等于指定offset的索引条目中最大的那个offset。自然offset为6的那个索引是我们要找的,通过索引文件我们知道offset为6的Message在数据文件中的位置
为9807。
打开数据文件,从位置为9807的那个地方开始顺序扫描直到找到offset为7的那条Message。
这套机制是建立在offset是有序的。索引文件被映射到内存中,所以查找的速度还是很快的。
一句话,Kafka的Message存储采用了分区(partition),分段(LogSegment)和稀疏索引这几个手段来达到了高效性。
3 日志清理
3.1 日志删除
Kafka日志管理器允许定制删除策略。目前的策略是删除修改时间在N天之前的日志(按时间删除),也可以使用另外一个策略:保留最后的N GB数据的策略(按大小删除)。为了避免在删除时阻塞读操作,采用了copy-on-write形式的实现,删除操作进行时,读取操作的二分查找功能实际是在一个静态的快
照副本上进行的,这类似于Java的CopyOnWriteArrayList。 Kafka消费日志删除思想:Kafka把topic中一个parition大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用
conf/server.properties
log.cleanup.policy=delete # 启动删除策略
直接删除,删除后的消息不可恢复,可配置以下两个策略:
清理超过指定之间清理
log.retention.hours=16
超过指定大小后,删除旧的信息
log.retention.bytes=1073741824
3.2 日志压缩
将数据压缩,只保留每个key最后一个版本的数据。
首先在broker的配置中设置log.cleaner.enable=true启用cleaner,这个默认是关闭的。
在Topic的配置中设置log.cleanup.policy=compact启用压缩策略。
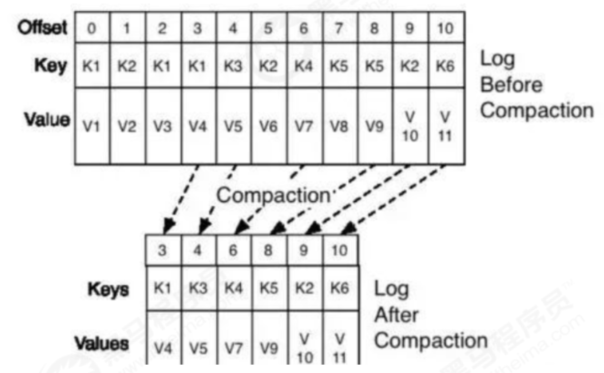
压缩后的offset可能是不连续的,比如上图中没有5和7,因为这些offset的消息被merge了,当从这些offset消费消息时,将会拿到比这个offset大的offset对应的消息,比如,当试图获取offset为5的消息时,实际上会拿到offset为6的消息,并从这个位置开始消费。
这种策略只适合特殊场景,比如消息的key是用户ID,消息体是用户的资料,通过这种压缩策略,整个消息集里就保存了所有用户最新的资料。
压缩策略支持删除,当某个Key的最新版本的消息没有内容时,这个Key将被删除,这也符合以上逻辑。
除了消息顺序追加,页缓存等技术, Kafka还使用了零拷贝技术来进一步提升性能。“零拷贝技术”只用将磁盘文件的数据复制到页面缓存中一次,然后将数据从页面缓存直接发送到网络中(发送给不同的订阅者时,都可以使用同一个页面缓存),避免了重复复制操作。如果有10个消费者,传统方式下,数据复制次数为4*10=40次,而使用“零拷贝技术”只需要1+10=11次,一次为从磁盘复制到页面缓存,10次表示10个消费者各自读取一次页面缓存。
4 磁盘存储优势
Kafka在设计的时候,采用了文件追加的方式来写入消息,即只能在日志文件的尾部追加新的消息,并且不允许修改已经写入的消息,这种方式属于典型的顺序写入此判断的操作,所以就算是Kafka使用磁盘作为存储介质,所能实现的额吞吐量也非常可观。
Kafka中大量使用页缓存,这页是Kafka实现高吞吐的重要因素之一。















 1863
1863











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









