







Replica(副本)
1 什么是Replica
1)当某个Topic的replication-factor为N且N大于1时,每个Partition都会有N个副本(Replica )
2)Replica的个数小于等于Broker数,即对每个Partition而言每个Broker上只会有一个Replica ,因此可用Broker ID表示Replica
为何这么设置?下图中,假如Partiton0的两个副本都在Broker 1上,那么如果Broker 1挂掉就达不到提高数据可用性。
3)所有Partition的所有Replica默认情况会均匀分布到所有Broker上
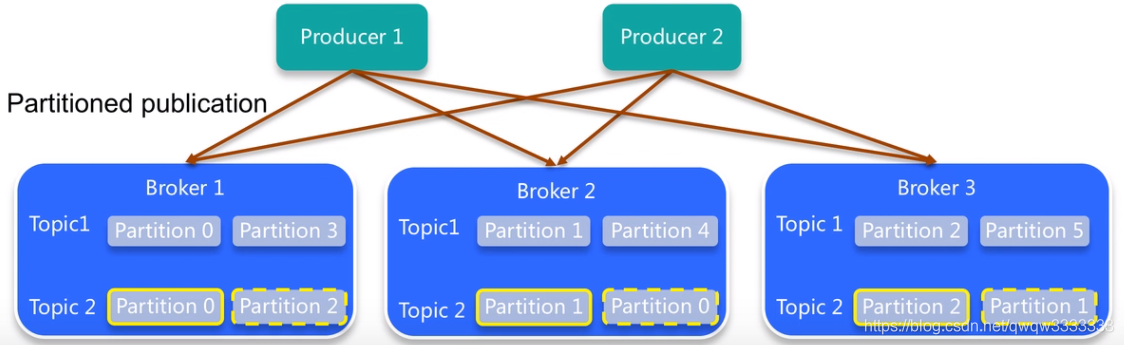
这里说到的Replica一定是某个Partition的Replica,对某个Topic来讲,Partition副本数是一样的,说到底Replica是Topic级别的定义,复制是以Partition为单位实际上Topic也是被复制
2 Data Replication要解决的问题
2.1 如何Propagate(传播)消息
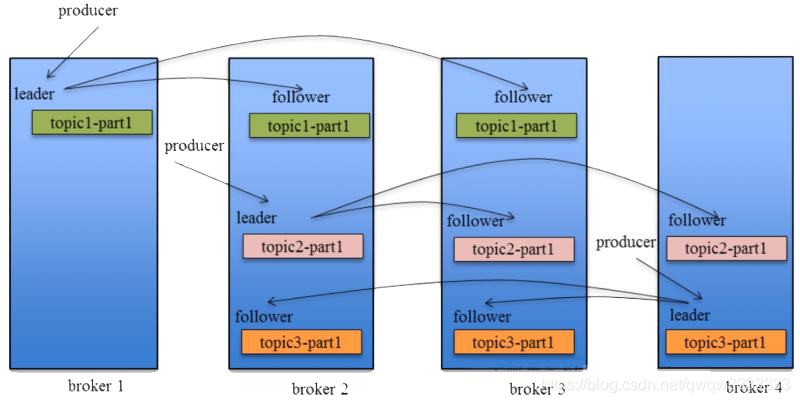
kafka集群类似于master-slave,但是并不是说一个集群只有一个中心节点,而是对于每个Partition而言有一个leader而其他的副本叫做follower,可以认为这个learder是这个Partition中心节点。可以认为每个Partition是一个小的集群,都有属于自己的leader/marster,有好几个副本/slave。上图可以知晓,topic1-part1的leader在broker1上,两个副本在broker2、broker3上,写入数据只会写入broker1然后复制到broker2和broker3上;topic2-part1的leader在broker2上,两个副本在broker3、broker4上;…
注意
数据的复制是由follower周期性的从leader拉取(pull)数据
上面说到写数据是向leader上写,读数据是否像数据库读写分离那样从slave上读呢?答案是否定的,读依然是从leader上读。follower只是保证leader挂掉的时候顶上去,并不能保证自己一边复制数据一边向外提供服务。
2.2 何时Commit
同步复制一致性高,可用性差;异步复制一致性差可用性高。kafka默认既不是同步复制也不是异步复制,而是使用IRS机制。
2.2.1 ISR(in-sync Replica )
- Leader爸维护一个与其基本保持同步的Replica列表,该列表称为ISR
- 如果一个Follower比Leader落后太多,或者超过一定时间未发起gg请求时,则Leader将其从ISR中移除
- 当ISR中所有Replica都向Leader发送ACK时,Leader即Commit
2.2.2 Commit策略
1、Server
follower从ISR删除策略
replica.lag.time.max.ms=10000
follower在10000/配置时间内没有向leader发送确认请求
replica.lag.max.nnessages=4000
follower和leader之间数据相差4000/配置条
follower宕机
当follower和leader之间的差距变小后,leader又会重新将follower重新加入到ISR中。这就在可用性和一致性之间做了动态的平衡。这是kafka和其他好多系统区别所在
2、Topic配罝,指定ISR最小值
- min.insync.replicas=1
3、Producer配置
request.required.acks=0,是异步的不需要leader给它任何的ack,立马返回。
request.required.acks=1,必须等待leader发送ack才认为发送成功
request.required.acks=-1,不需要自己决策,交给broker进行决策
如果要使用ISR就需要将 request.required.acks的值设置为-1
2.3 如何处理Replica恢复
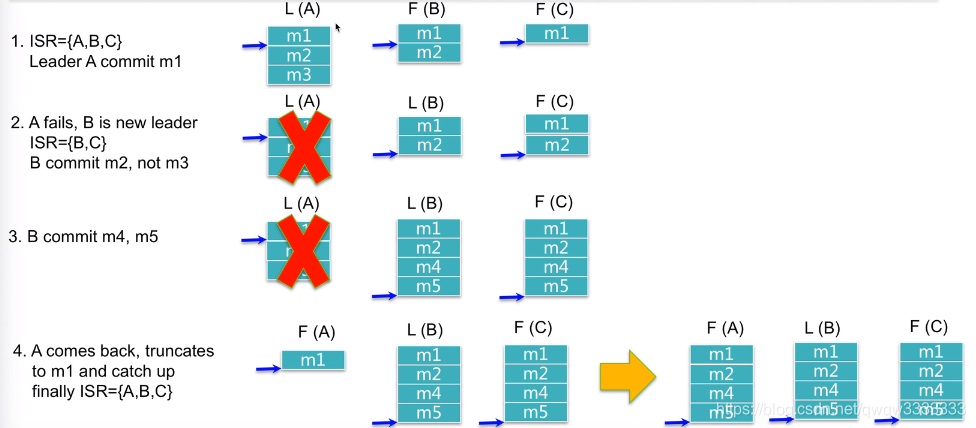
第一步:只有A、B、C同时拥有m1所以m1才会被commit
第二步:A宕机,B变成新的leader,新到达的数据m2会被commit
第三步:A依然宕机,新来的数据m4、m5被提交
第四步:A恢复,由于知道自己之前commit到m1,所以需要删除m1之后的数据,然后进行追赶B、C,直到将B、C节点commit的数据拿过去之后才被B重新添加到ISR中。
2.4 如何处理Replica全部宕机
kafka提供以下两种方式供配置选择:
1.等待ISR中任一Replica恢复,并选它为Leader
- 等待时间较长,降低可用性
- 或ISR中的所有Replica都无法恢复或者数据丟失,则该Partition将永不可用
2.选择第一个恢复的Replica为新的Leader,无论它是否在ISR中
- 并未包含所有已被之前Leader Commit过的消息,因此会造成数据丟失
- 可用性较高
原文:https://blog.csdn.net/qwqw3333333/article/details/106133662















 2214
2214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









