







 本文介绍了自编码器的基本结构及多种类型,包括Vanilla、多层、卷积和正则化自编码器。通过施加不同约束,每种自编码器具有特定属性。
本文介绍了自编码器的基本结构及多种类型,包括Vanilla、多层、卷积和正则化自编码器。通过施加不同约束,每种自编码器具有特定属性。
自编码器(Autoencoder,AE),是一种利用反向传播算法使得输出值等于输入值的神经网络,它先将输入压缩成潜在空间表征,然后通过这种表征来重构输出。
自编码器由两部分组成:
编码器(encoder):这部分能将输入压缩成潜在空间表征,可以用编码函数h=f(x)表示。
解码器(decoder):这部分重构来自潜在空间表征的输入,可以用解码函数r=g(h)表示。
因此,整个自编码器可以用函数g(f(x)) = r 来描述,其中输出r与原始输入x相近。
一、为何要用输入来重构输出?
如果自编码器的唯一目的是让输出值等于输入值,那种人个算法将毫无用处。事实上,我们希望通过训练输出值等于输入值的自编码器,让潜在表征h将具有价值属性。
这可通过在重构任务中构建约束来实现。
从自编码器获得有用特征的一种方法是,限制h的维度使其小于输入x,这种情况下称作有损自编码器。通过训练有损表征,使得自编码器能学习到数据中最重要的特征。
如果潜在表征的维度与输入相同,或是在完备案例中潜在表征的维度大于输入,上述结果也会出现。
在这些情况下,即使只使用线性编码器和线性解码器,也能很好地利用输入重构输出,且无需了解有关数据分布的任何有用信息。
在理想情况下,根据要分配的数据复杂度,来准确选择编码器和解码器的编码维数和容量,就可以成功地训练出任何所需的自编码器结构。
二、自编码器用来干什么?
目前,自编码器的应用主要有两个方面:
1.第一是数据去噪
2.第二是为进行可视化而降维。
设置合适的维度和稀疏约束,自编码器可以学习到PCA等技术更有意思的数据投影。
自编码器能从数据样本中进行无监督学习,这意味着可以将这个算法应用到某个数据集中,来取得良好的性能,且不需要任何新的特征工程,只需要适当地训练数据。
但是,自编码器在图像压缩方面表现的不好。由于在某个给定数据集上训练自编码器,因此它在处理与训练集相类似的数据时可达到合理的压缩结果,但是在压缩差异较大的其他图像时效果不佳。这里,像JPEG这样的压缩技术在通用图像压缩方面会表现得更好。
训练自编码器,可以使输入通过编码器和解码器后,保留尽可能多的信息,但也可以训练自编码器来使新表征具有多种不同的属性。不同类型的自编码器旨在实现不同类型的属性。下面将重点介绍四中不同的自编码器。
三、四种不同的自编码器
本文将介绍以下四种不同的自编码器:
-
vanilla自编码器
-
多层自编码器
-
卷积自编码器
-
正则自编码器
vanilla自编码器
在这种自编码器的最简单结构中,只有三个网络层,即只有一个隐藏层的神经网络。它的输入和输出是相同的,可通过使用Adam优化器和均方误差损失函数,来学习如何重构输入。
在这里,如果隐含层维数(64)小于输入维数(784),则称这个编码器是有损的。通过这个约束,来迫使神经网络来学习数据的压缩表征。
input_size = 784
hidden_size = 64
output_size = 784
x = Input(shape=(input_size,))
# Encoder
h = Dense(hidden_size, activation='relu')(x)
# Decoder
r = Dense(output_size, activation='sigmoid')(h)
autoencoder = Model(input=x, output=r)
autoencoder.compile(optimizer='adam', loss='mse')
多层自编码器
如果一个隐含层还不够,显然可以将自动编码器的隐含层数目进一步提高。
在这里,实现中使用了3个隐含层,而不是只有一个。任意一个隐含层都可以作为特征表征,但是为了使网络对称,我们使用了最中间的网络层。
input_size = 784
hidden_size = 128
code_size = 64
x = Input(shape=(input_size,))
# Encoder
hidden_1 = Dense(hidden_size, activation='relu')(x)
h = Dense(code_size, activation='relu')(hidden_1)
# Decoder
hidden_2 = Dense(hidden_size, activation='relu')(h)
r = Dense(input_size, activation='sigmoid')(hidden_2)
autoencoder = Model(input=x, output=r)
autoencoder.compile(optimizer='adam', loss='mse')卷积自编码器
你可能有个疑问,除了全连接层,自编码器应用到卷积层吗?
答案是肯定的,原理是一样的,但是要使用3D矢量(如图像)而不是展平后的一维矢量。对输入图像进行下采样,以提供较小维度的潜在表征,来迫使自编码器从压缩后的数据进行学习。
x = Input(shape=(28, 28,1))
# Encoder
conv1_1 = Conv2D(16, (3, 3), activation='relu', padding='same')(x)
pool1 = MaxPooling2D((2, 2), padding='same')(conv1_1)
conv1_2 = Conv2D(8, (3, 3), activation='relu', padding='same')(pool1)
pool2 = MaxPooling2D((2, 2), padding='same')(conv1_2)
conv1_3 = Conv2D(8, (3, 3), activation='relu', padding='same')(pool2)
h = MaxPooling2D((2, 2), padding='same')(conv1_3)
# Decoder
conv2_1 = Conv2D(8, (3, 3), activation='relu', padding='same')(h)
up1 = UpSampling2D((2, 2))(conv2_1)
conv2_2 = Conv2D(8, (3, 3), activation='relu', padding='same')(up1)
up2 = UpSampling2D((2, 2))(conv2_2)
conv2_3 = Conv2D(16, (3, 3), activation='relu')(up2)
up3 = UpSampling2D((2, 2))(conv2_3)
r = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(up3)
autoencoder = Model(input=x, output=r)
autoencoder.compile(optimizer='adam', loss='mse')正则自编码器
除了施加一个比输入维度小的隐含层,一些其他方法也可用来约束自编码器重构,如正则自编码器。
正则自编码器不需要使用浅层的编码器和解码器以及小的编码维数来限制模型容量,而是使用损失函数来鼓励模型学习其他特性(除了将输入复制到输出)。这些特性包括稀疏表征、小导数表征、以及对噪声或输入缺失的鲁棒性。
即使模型容量大到足以学习一个无意义的恒等函数,非线性且过完备的正则自编码器仍然能够从数据中学到一些关于数据分布的有用信息。
在实际应用中,常用到两种正则自编码器,分别是稀疏自编码器和降噪自编码器。
稀疏自编码器:
一般用来学习特征,以便用于像分类这样的任务。稀疏正则化的自编码器必须反映训练数据集的独特统计特征,而不是简单地充当恒等函数。以这种方式训练,执行附带稀疏惩罚的复现任务可以得到能学习有用特征的模型。
还有一种用来约束自动编码器重构的方法,是对其损失函数施加约束。比如,可对损失函数添加一个正则化约束,这样能使自编码器学习到数据的稀疏表征。
要注意,在隐含层中,我们还加入了L1正则化,作为优化阶段中损失函数的惩罚项。与香草自编码器相比,这样操作后的数据表征更为稀疏。
input_size = 784
hidden_size = 64
output_size = 784
x = Input(shape=(input_size,))
# Encoder
h = Dense(hidden_size, activation='relu', activity_regularizer=regularizers.l1(10e-5))(x)#施加在输出上的L1正则项
# Decoder
r = Dense(output_size, activation='sigmoid')(h)
autoencoder = Model(input=x, output=r)
autoencoder.compile(optimizer='adam', loss='mse')降噪自编码器:
这里不是通过对损失函数施加惩罚项,而是通过改变损失函数的重构误差项来学习一些有用信息。
向训练数据加入噪声,并使自编码器学会去除这种噪声来获得没有被噪声污染过的真实输入。因此,这就迫使编码器学习提取最重要的特征并学习输入数据中更加鲁棒的表征,这也是它的泛化能力比一般编码器强的原因。
这种结构可以通过梯度下降算法来训练。
x = Input(shape=(28, 28, 1))
# Encoder
conv1_1 = Conv2D(32, (3, 3), activation='relu', padding='same')(x)
pool1 = MaxPooling2D((2, 2), padding='same')(conv1_1)
conv1_2 = Conv2D(32, (3, 3), activation='relu', padding='same')(pool1)
h = MaxPooling2D((2, 2), padding='same')(conv1_2)
# Decoder
conv2_1 = Conv2D(32, (3, 3), activation='relu', padding='same')(h)
up1 = UpSampling2D((2, 2))(conv2_1)
conv2_2 = Conv2D(32, (3, 3), activation='relu', padding='same')(up1)
up2 = UpSampling2D((2, 2))(conv2_2)
r = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(up2)
autoencoder = Model(input=x, output=r)
autoencoder.compile(optimizer='adam', loss='mse')使用tensorflow实现对手写字(MNIST)的AutoEncoder
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# Import MNIST data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=False)
# Visualize decoder setting
# Parameters
learning_rate = 0.01
batch_size = 256
display_step = 1
examples_to_show = 10
# Network Parameters
n_input = 784 # 28x28 pix,即 784 Features
# tf Graph input (only pictures)
X = tf.placeholder("float", [None, n_input])
# hidden layer settings
n_hidden_1 = 256 # 经过第一个隐藏层压缩至256个
n_hidden_2 = 128 # 经过第二个压缩至128个
#两个隐藏层的 weights 和 biases 的定义
weights = {
'encoder_h1': tf.Variable(tf.random_normal([n_input, n_hidden_1])),
'encoder_h2': tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2])),
'decoder_h1': tf.Variable(tf.random_normal([n_hidden_2, n_hidden_1])),
'decoder_h2': tf.Variable(tf.random_normal([n_hidden_1, n_input])),
}
biases = {
'encoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'encoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'decoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'decoder_b2': tf.Variable(tf.random_normal([n_input])),
}
# Building the encoder
def encoder(x):
# Encoder Hidden layer 使用的 Activation function 是 sigmoid #1
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['encoder_h1']),
biases['encoder_b1']))
# Decoder Hidden layer with sigmoid activation #2
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['encoder_h2']),
biases['encoder_b2']))
return layer_2
# Building the decoder
def decoder(x):
# Encoder Hidden layer with sigmoid activation #1
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['decoder_h1']),
biases['decoder_b1']))
# Decoder Hidden layer with sigmoid activation #2
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['decoder_h2']),
biases['decoder_b2']))
return layer_2
'''
# Visualize encoder setting
# 只显示解压后的数据
learning_rate = 0.01 # 0.01 this learning rate will be better! Tested
training_epochs = 10
batch_size = 256
display_step = 1
# Network Parameters
n_input = 784 # MNIST data input (img shape: 28*28)
# tf Graph input (only pictures)
X = tf.placeholder("float", [None, n_input])
# hidden layer settings
n_hidden_1 = 128
n_hidden_2 = 64
n_hidden_3 = 10
n_hidden_4 = 2 #将原有784Features 的数据压缩成2 Features数据
weights = {
'encoder_h1': tf.Variable(tf.truncated_normal([n_input, n_hidden_1],)),
'encoder_h2': tf.Variable(tf.truncated_normal([n_hidden_1, n_hidden_2],)),
'encoder_h3': tf.Variable(tf.truncated_normal([n_hidden_2, n_hidden_3],)),
'encoder_h4': tf.Variable(tf.truncated_normal([n_hidden_3, n_hidden_4],)),
'decoder_h1': tf.Variable(tf.truncated_normal([n_hidden_4, n_hidden_3],)),
'decoder_h2': tf.Variable(tf.truncated_normal([n_hidden_3, n_hidden_2],)),
'decoder_h3': tf.Variable(tf.truncated_normal([n_hidden_2, n_hidden_1],)),
'decoder_h4': tf.Variable(tf.truncated_normal([n_hidden_1, n_input],)),
}
biases = {
'encoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'encoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'encoder_b3': tf.Variable(tf.random_normal([n_hidden_3])),
'encoder_b4': tf.Variable(tf.random_normal([n_hidden_4])),
'decoder_b1': tf.Variable(tf.random_normal([n_hidden_3])),
'decoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'decoder_b3': tf.Variable(tf.random_normal([n_hidden_1])),
'decoder_b4': tf.Variable(tf.random_normal([n_input])),#注意:在第四层时,输出量不再是 [0,1] 范围内的数,
#而是将数据通过默认的 Linear activation function 调整为 (-∞,∞)
}
def encoder(x):
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['encoder_h1']),
biases['encoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['encoder_h2']),
biases['encoder_b2']))
layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['encoder_h3']),
biases['encoder_b3']))
layer_4 = tf.add(tf.matmul(layer_3, weights['encoder_h4']),
biases['encoder_b4'])
return layer_4
def decoder(x):
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['decoder_h1']),
biases['decoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['decoder_h2']),
biases['decoder_b2']))
layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['decoder_h3']),
biases['decoder_b3']))
layer_4 = tf.nn.sigmoid(tf.add(tf.matmul(layer_3, weights['decoder_h4']),
biases['decoder_b4']))
return layer_4
'''
# Construct model
encoder_op = encoder(X)
decoder_op = decoder(encoder_op)
# Prediction
y_pred = decoder_op
# Targets (Labels) are the input data.
y_true = X
# Define loss and optimizer, minimize the squared error
#比较原始数据与还原后的拥有 784 Features 的数据进行 cost 的对比,
#根据 cost 来提升我的 Autoencoder 的准确率
loss = tf.reduce_mean(tf.pow(y_true - y_pred, 2))#进行最小二乘法的计算(y_true - y_pred)^2
#loss = tf.reduce_mean(tf.square(y_true - y_pred))
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(loss)
# Launch the graph
with tf.Session() as sess:
init = tf.global_variables_initializer()
sess.run(init)
total_batch = int(mnist.train.num_examples/batch_size)
training_epochs = 20
# Training cycle
for epoch in range(training_epochs):#到好的的效果,我们应进行10 ~ 20个 Epoch 的训练
# Loop over all batches
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size) # max(x) = 1, min(x) = 0
# Run optimization op (backprop) and cost op (to get loss value)
_, c = sess.run([optimizer, loss], feed_dict={X: batch_xs})
# Display logs per epoch step
if epoch % display_step == 0:
print("Epoch:", '%04d' % (epoch+1),
"cost=", "{:.9f}".format(c))
print("Optimization Finished!")
# Applying encode and decode over test set
encode_decode = sess.run(
y_pred, feed_dict={X: mnist.test.images[:examples_to_show]})
# Compare original images with their reconstructions
f, a = plt.subplots(2, 10, figsize=(10, 2))
for i in range(examples_to_show):
a[0][i].imshow(np.reshape(mnist.test.images[i], (28, 28)))
a[1][i].imshow(np.reshape(encode_decode[i], (28, 28)))
plt.show()
# encoder_result = sess.run(encoder_op, feed_dict={X: mnist.test.images})
# sc = plt.scatter(encoder_result[:, 0], encoder_result[:, 1], c=mnist.test.labels) #散点图
# plt.colorbar(sc) #scatter设置颜色渐变条colorbar
# plt.show()上面一行图片为测试图片,第二行为经过自编码器后输出
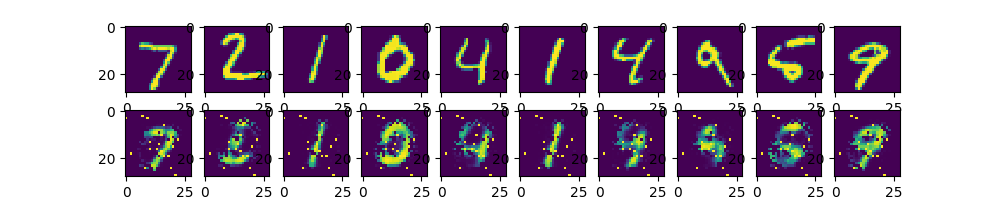
图1 手写数字照片经自编码器输出与原照片对比
应用--基于降噪自编码器的情感分析
一个简单的降噪自动编码器如图2( a) 所示,最底层的小圆代表原始数据而带淡蓝色的小圆则是噪声数据。将这些数据输入到编码器中会得到输入数据的一个表示,再将这个表示通过解码器输出一个信息,通过调整编码器和解码器的参数使得重构误差最小。
将上一层的输出作为下一层的输入,其逐层嵌入可如图2( b) 所示。为了实现情感分析的任务,必须在输出层的前一层添加一个分类器softmax 层,然后通过标准的多层神经网络监督训练梯度下降法,最后得到如图2( c) 中的堆叠多隐层的降噪自动编码器。
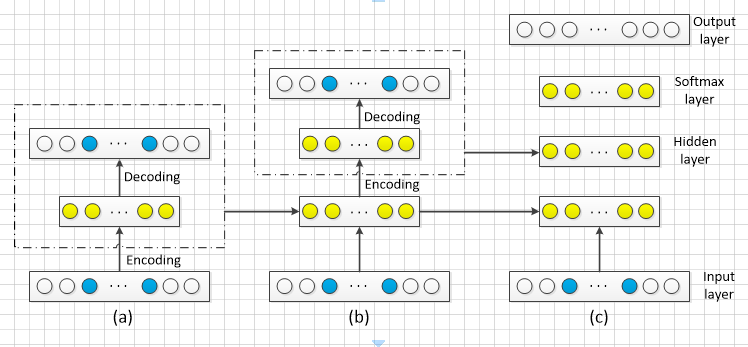
图2 降噪自动编码器的逐层嵌入与训练模型
总结
本文先介绍了自编码器的基本结构,还研究了许多不同类型的自编码器,如vanilla、多层、卷积和正则化,通过施加不同的约束,包括缩小隐含层的维度加入惩罚项,使得每种自编码器具有不同属性。
希望这篇文章能让深度学习初学者对自编码器有个很好的认识。

















 1794
1794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









