







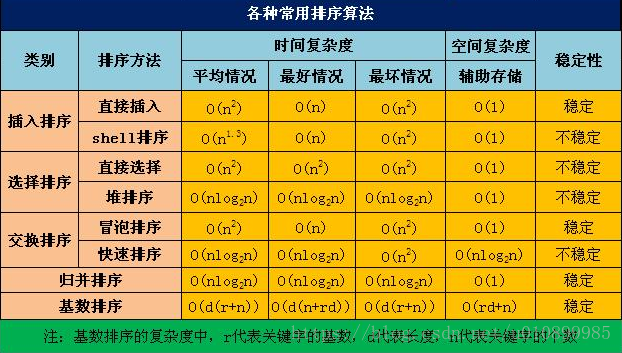
常见的七种排序算法:
- 外排序:需要在内外存之间多次交换数据才能进行
- 内排序:
插入类排序
直接插入排序
希尔排序
选择类排序
简单选择排序
堆排序
交换类排序
冒泡排序
快速排序
归并类排序
归并排序
直接插入排序
插入排序是将一个数据插入到已经排好序的有序数据中,从而得到一个新的、个数加一的有序数据,算法适用于少量数据的排序。插入算法把要排序的数组分成两部分:
- 第一部分包含了这个数组的所有元素,但将最后一个元素除外(让数组多一个空间才有插入的位置),
- 而第二部分就只包含这一个元素(即待插入元素)。在第一部分排序完成后,再将这个最后元素插入到已排好序的第一部分中。
def insert_sort(lists):
for i in range(1, len(lists)):# 假设第一个数是已排序好的
key = lists[i] # key变量指向尚未排好序元素(从第二个开始)
j = i - 1 # j指向前一个元素的下标(已排好序)
while j >= 0 and key < lists[j]: # key与前一个元素比较,若key小则前一元素向后移
lists[j + 1] = lists[j]
j -= 1 # 取排序好的数的前一个数继续对比
lists[j + 1] = key # 将当前需排序的数插入
return lists
lists = [5,4,20,9,7,1]
insert_sort(lists)
print(lists)
插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率O(n),但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位, O(n^2)。
Shell 排序(希尔排序)
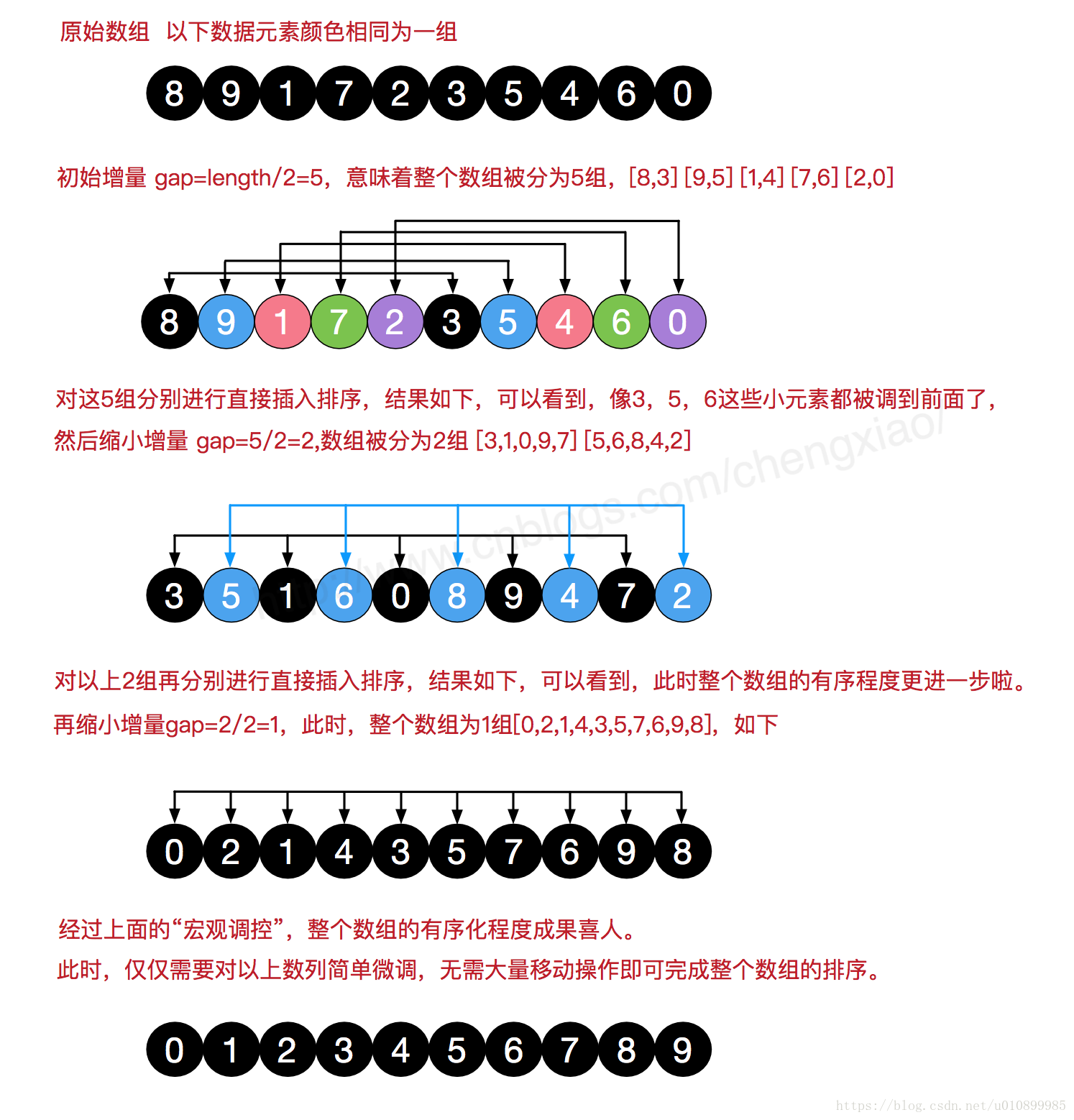
Shell 排序又称缩小增量排序, 是对直接插入排序的改进,效率提高。
算法原理:
对相邻指定距离(称为增量)的元素进行比较,并不断将增量缩小至1,完成排序。增量因子序列可以有各种取法,有取奇数的,也有取质数(在大于1的自然数中,除了1和它本身以外不再有其他因数),增量的取法:
- 第一次增量的取法为: d=len(lists) / 2;
- 第二次增量的取法为: d=(len(lists))/2;
- 最后一直到: d=1;
当增量减小到1时,此时序列已基本有序,希尔排序的最后一趟就是接近最好情况的直接插入排序。
def shell_Sort(lists):
step = len(lists) // 2 # 设定步长
while step > 0:
for i in range(step, len(lists)):
# 类似插入排序, 当前值与指定步长之前的值比较, 符合条件则交换位置
while i >= step and lists[i] < lists[i - step]:
lists[i], lists[i - step] = lists[i - step], lists[i]
i -= step
step = step // 2
return lists
lists = [5,4,20,9,7,1]
shell_Sort(lists)
print(lists)
冒泡排序
基本思想就是两两比较相邻的元素,如果逆序,则交换位置,最后最小的元素就像气泡一样浮到最上面。为了避免对已然有序的数据集一直执行比较操作,可以设置标志位flag控制循环,如果某次循环存在元素交换,设flag = 1,表明下次仍然需要继续循环比较;如果false = 0,表明剩余元素已然有序,此时排序工作结束。
改进后的冒泡排序最好情况下,只需要n-1次比较,时间复杂度为O(n);在数据集为逆序时,情况最糟糕,为O(n2)。
算法实现:
def bubbleSort(nums):
for i in range(len(nums)-1): # 这个循环负责设置冒泡排序进行的次数
for j in range(len(nums)-i-1): # j为列表下标
if nums[j] > nums[j+1]: #如果前面的数大就交换位置
nums[j], nums[j+1] = nums[j+1], nums[j]
return nums
nums = [5,4,20,9,7,1]
print bubbleSort(nums)冒泡排序解决了桶排序浪费空间的问题, 但是冒泡排序的效率特别低
快速排序
快速排序是C.R.A.Hoare于1962年提出的一种划分交换排序。它采用了一种分治的策略,通常称其为分治法(Divide-and-ConquerMethod)。 快排的思想:首先任意选取一个数据(通常选用数组的第一个数)作为基准数,然后将所有比它小的数都放到它前面,所有比它大的数都放到它后面,这个过程称为一趟快速排序。
该方法的基本思想是:
1.首先从数列中任意选取一个数据(通常选用数组的第一个数)作为基准数。
2.分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边。
3.再对左右区间重复第二步,直到各区间只有一个数。
举例说明:现有十组数据需要重新排序,a[10]={23,43,2,5,1,87,53,90,76,68}.
首先取最开始的一个数为基准数,即令i=1,j=10,k=23.
def quick_sort(array, l, r):
if l >= r:
return
low , high= l, r
key = array[low] #选取第一个数作为基准数
while l < r:
while l < r and array[r] > key: #当列表后边的数大于比基准数,则前移一位直到有比基准数小的数出现
r -= 1
array[l] = array[r] #若找到,则交换位置
while l < r and array[l] <= key: #同样的方式比较前半区, 则后移一位直到有比基准数大的数出现
l += 1
array[r] = array[l]
#做完第一轮比较之后,列表被分成了两个半区,并且l=r,需要将这个数设置回基准数key
array[r] = key
#继续递归前后半区
quick_sort(array, low, l - 1)
quick_sort(array, l + 1, high)
array = [5,4,20,9,7,1]
quick_sort(array, 0, len(array)-1)
print(array) 直接选择排序
基本思想:第1趟,从所有待排序记录r1 ~ r[n]中出最小的一个数据元素与第一个位置r1交换;第2趟,在待排序记录r2 ~ r[n]中选出最小的记录,将它与r2交换;以此类推,第i趟在待排序记录r[i] ~ r[n]中选出最小的记录,将它与r[i]交换,使有序序列不断增长直到全部排序完毕。因此,时间复杂度:O(n^2)。需要进行的比较次数为第一轮 n-1,n-2....1, 总的比较次数为 n*(n-1)/2
算法实现
def select_sort(lists):
for i in range(0, len(lists)): #从待排序数组中选择最小值的index为基准数
min = i
for j in range(i + 1, len(lists)): #将基准数和余下的数进行一一比较
if lists[j] < lists[min] : #如果找到比当前基准数小的index, 则进行两值交换
min = j
lists[min], lists[i] = lists[i], lists[min]
return lists
lists = [5,4,20,9,7,1]
select_sort(lists)
print(lists)
堆排序
- 算法描述
作为选择排序的改进版,堆排序可以把每一趟元素的比较结果保存下来,以便我们在选择最小/大元素时对已经比较过的元素做出相应的调整。堆排序是一种树形选择排序,在排序过程中可以把元素看成是一颗完全二叉树,每个节点都大(小)于它的两个子节点,当每个节点都大于等于它的两个子节点时,就称为大顶堆,也叫堆有序;当每个节点都小于或等于它的两个子节点时,就称为小顶堆.
- 算法思想(以大顶堆为例):
- 将长度为n的待排序的数组进行堆有序化构造成一个大顶堆, 此堆为初始的无序区
- 将 根节点 与 尾节点 交换并输出此时的尾节点
- 将剩余的n -1个节点重新进行堆有序化
- 重复步骤2和3直至构造成一个有序序列
构造堆(大顶堆为例)
在构造有序堆时,我们开始只需要扫描一半的元素(n/2-1 ~ 0)即可,为什么?
因为(n/2-1)~0个节点才有子节点
假设待排序数组为[20,50,10,60,30,70,20,80]
n=8, (n/2-1) = 3 即,3 2 1 0这个四个节点才有子节点;
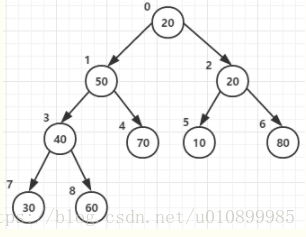
(初始状态为例)
所以代码4~6行for循环的作用就是将3 2 1 0这四个节点从下到上,从右到左的与它自己的子节点比较并调整最终形成大顶堆,过程如下:
第一次for循环将节点3和它的子节点7 8的元素进行比较,最大者作为父节点(即元素60作为父节点)【红色表示交换后的状态】
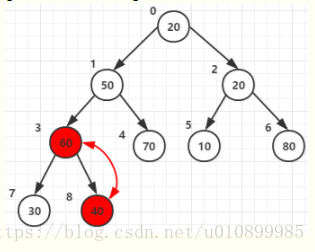
第二次for循环将节点2和它的子节点5 和6的元素进行比较,最大者为父节点(元素80作为父节点)

第三次for循环将节点1和它的子节点3 与4的元素进行比较,最大者为父节点(元素70作为父节点)
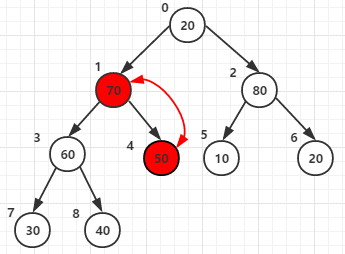
第四次for循环将节点0和它的子节点1 和 2的元素进行比较,最大者为父节点(元素80作为父节点)
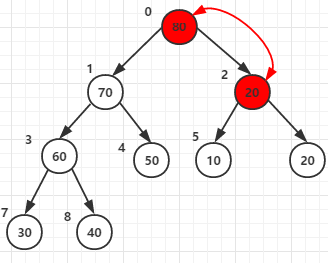
注意这里,元素20和元素80交换后,20所在的节点还有子节点,所以还要再和它的子节点5和6的元素进行比较(这就是代码
max != i 的原因)
至此大顶堆(有序堆)已经构造好了!如下图:
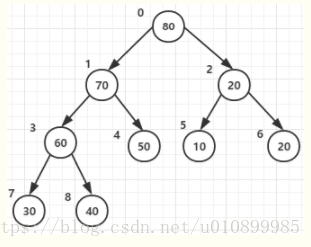
调整堆
下面进行while循环
(1)堆顶元素80和尾40交换后-->调整堆
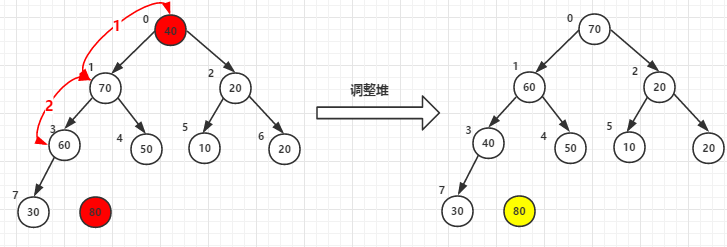
(2)堆顶元素70和尾30交换后-->调整堆
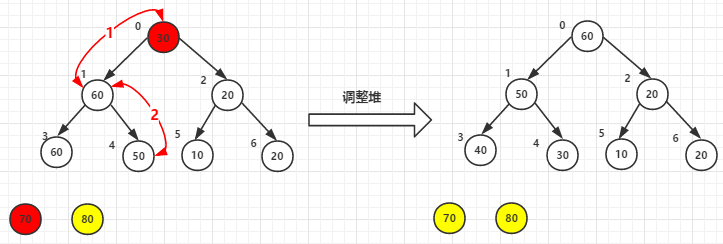
(3)堆顶元素60尾元素20交换后-->调整堆
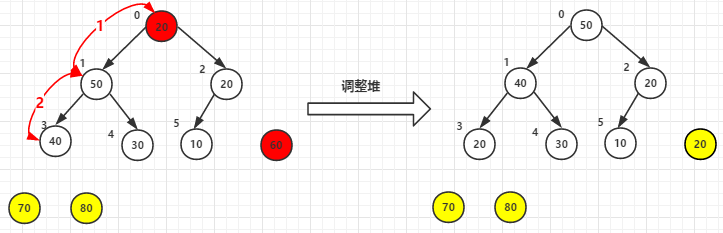
(4)其他依次类推,最终已排好序的元素如下:
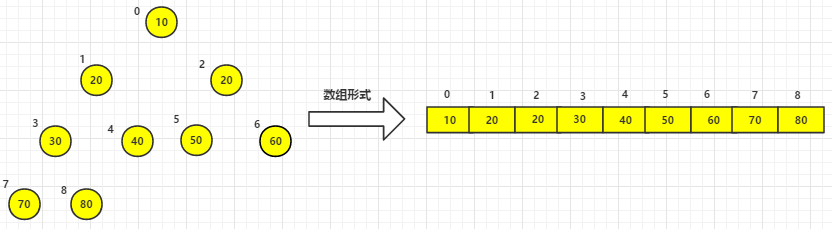
- 算法实现
# 调整成大顶堆,初始堆时,从下往上;
# 当列表第一个是以下标0开始,结点下标为i,左孩子则为2*i+1,右孩子下标则为2*i+2;
# 若下标以1开始,左孩子则为2*i, 右孩子则为2*i+1
def adjust_heap(lists, i, size):
lchild = 2 * i + 1
rchild = 2 * i + 2
max = i #设定父节点
# 因为(n/2-1)~0个节点才有子节点,因此只需扫面一般元素即可
if i < size // 2 -1: # 父节点与子节点(左右子节点)比较,最大者作为父节点
if lchild < size and lists[lchild] > lists[max]:
max = lchild
if rchild < size and lists[rchild] > lists[max]:
max = rchild
if max != i:
lists[max], lists[i] = lists[i], lists[max]
adjust_heap(lists, max, size)
def build_heap(lists, size):
for i in range(0, (size // 2 -1))[::-1]: # 从最后一个有孩子的节点开始往上调整
adjust_heap(lists, i, size)
#堆排序
def heap_sort(lists):
size = len(lists)
build_heap(lists, size)
for i in range(0, size-1)[::-1]:
lists[0], lists[i] = lists[i], lists[0]
adjust_heap(lists, 0, i)
if __name__ == "__main__":
lists = [98, 86, 68, 58, 42, 41]
heap_sort(lists)
print(lists)
归并排序
- 算法描述:
归并排序是另一种利用分治法排序的算法,其首先将数据集二等分为左右两个区间,分别在左右区间上递归地使用归并排序算法,然后将两个有序表合并成一个有序表,称为二路归并。与快速排序一样,它依赖于元素之间的比较。归并排序的归并过程就是合并两个已经排好序的数据集合,此时对需要合并的元素遍历一次即可,非常高效。因此,归并排序在所有的情况下都能达到快速排序的平均性能O(nlogn)。但是,其主要的缺点是排序过程需要额外的存储空间来支持,因为合并过程不能在无序数据集本身中进行,因此需要两倍于无序数据集的空间O(n)来运行算法,这也就极大地降低了实际中使用归并排序的频率,反而由快速排序取代它的工作。
- 归并算法的时间复杂度为O(nlogn)。
比较抽象,我们一起来看归并排序的处理元素的图例:
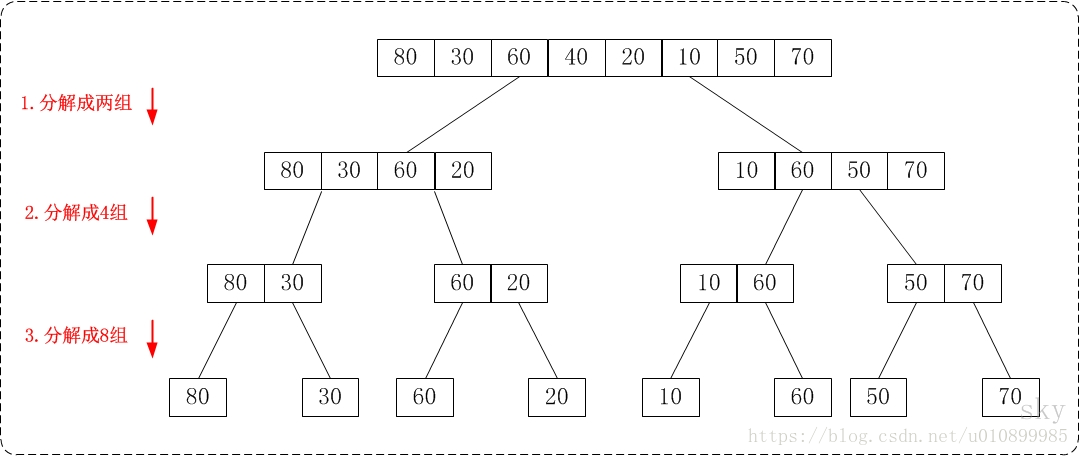
算法实现(归并过程:)
- 比较a[i]和a[j]的大小,若a[i]≤a[j],则将第一个有序表中的元素a[i]复制到r[k]中,并令i和k分别加上1;
- 否则将第二个有序表中的元素 a[j] 复制到r[k]中,并令j和k分别加上1,如此循环下去,直到其中一个有序表取完,然后再将另一个有序表中剩余的元素复制到 r 中, 从下标 k 到下标 t 的单元。
- 归并排序的算法我们通常用递归实现,先把待排序区间[s,t]以中点二分,接着把左边子区间排序,再把右边子区间排序,最后把左区间和右区间用一次归并操作合并成有序的区间[s,t]。
def merge(left, right):
i, j = 0, 0
result = []
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result += left[i:]
result += right[j:]
return result
def merge_sort(lists):
# 归并排序
if len(lists) <= 1:
return lists
num = len(lists) / 2
left = merge_sort(lists[:num])
right = merge_sort(lists[num:])
return merge(left, right)
基数排序
- 算法描述:
基数排序是另外一种高效的线性排序方法。其将数据按位分离,并从数据的最低有效位到最高有效位依次进行排序,从而得到有序数据集合。但是,对某个位进行排序时必须选择稳定的排序算法。基数排序并不局限于对整型数据进行排序,凡是将元素分割为整型的,就可以使用它。基数的选择依赖于数据本身,例如以28为基对字符串进行排序,以10为基对整型进行排序...。bits表示每个待排元素包含的位数,radix表示基数。
- 算法分析:
基数排序实质上就是对元素的每一位进行计数排序,因此其时间复杂度为O(b(n + r)),其中n为数据集中元素个数,r为基数radix,b为每个元素的位数bits;空间复杂度与计数排序一样,需要额外的temp和counts,大致可以记为O(n)。
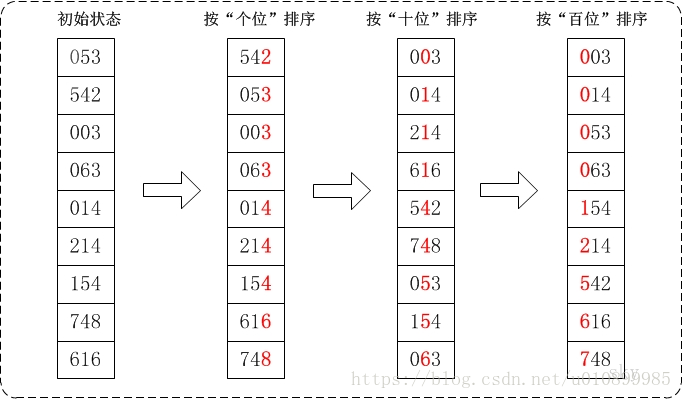
首先将所有待比较树统一为统一 位数长度,接着从最低位开始,依次进行排序:
1. 按照个位数进行排序。
2. 按照十位数进行排序。
3. 按照百位数进行排序。
排序后,数列就变成了一个有序序列。
算法实现
import math
def radix_sort(lists, radix=10): #lists为整数列表, radix为基数
k = int(math.ceil(math.log(max(lists), radix))) # 返回x的大于等于x的最小整数 用K位数可表示任意整数
bucket = [[] for i in range(radix)] #将所有待比较树统一为统一位数长度k
for i in range(1, k+1): # K次循环
for j in lists:
bucket[int(j % (radix ** i) // (radix ** (i - 1)))].append(j)
# 解析取整数第K位数字 (从低到高)
del lists[:]
for each in bucket:
lists.extend(each) #lists += each 桶合并
del each[:]
return lists
lists = [39,472,655,92, 38 ,2, 352]
radix_sort(lists)
print(lists)归并排序为什么比冒泡快?相比归并,冒泡多了哪些不必要的比较?
看完了上面的排序,心已是累累滴,给大家推荐一个比较容易理解:通过动画可视化数据结构和算法














 143
143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









