






声明:本文翻译自colah的博客,原文地址:Understanding LSTM NETWORK
递归神经网络
人类并不是从混沌状态开始他们的思考。就像你读这篇文章时,你是建立在你之前对文字的理解上。你并不是学习结束之后就丢弃掉你学到的东西,然后再从混沌状态开始。因为你的思想有持续性。
然而,传统的神经网络并不能做到持续记忆,这应该是传统神经网络的一个缺陷。假想一下,你想让神经网络对电影中每个时间点的事件进行分类,很明显,传统神经网络不能使用前一个事件去推理下一个事件。
递归神经网络可以解决这个问题。它们是带有循环的神经网络,允许信息保留一段时间。

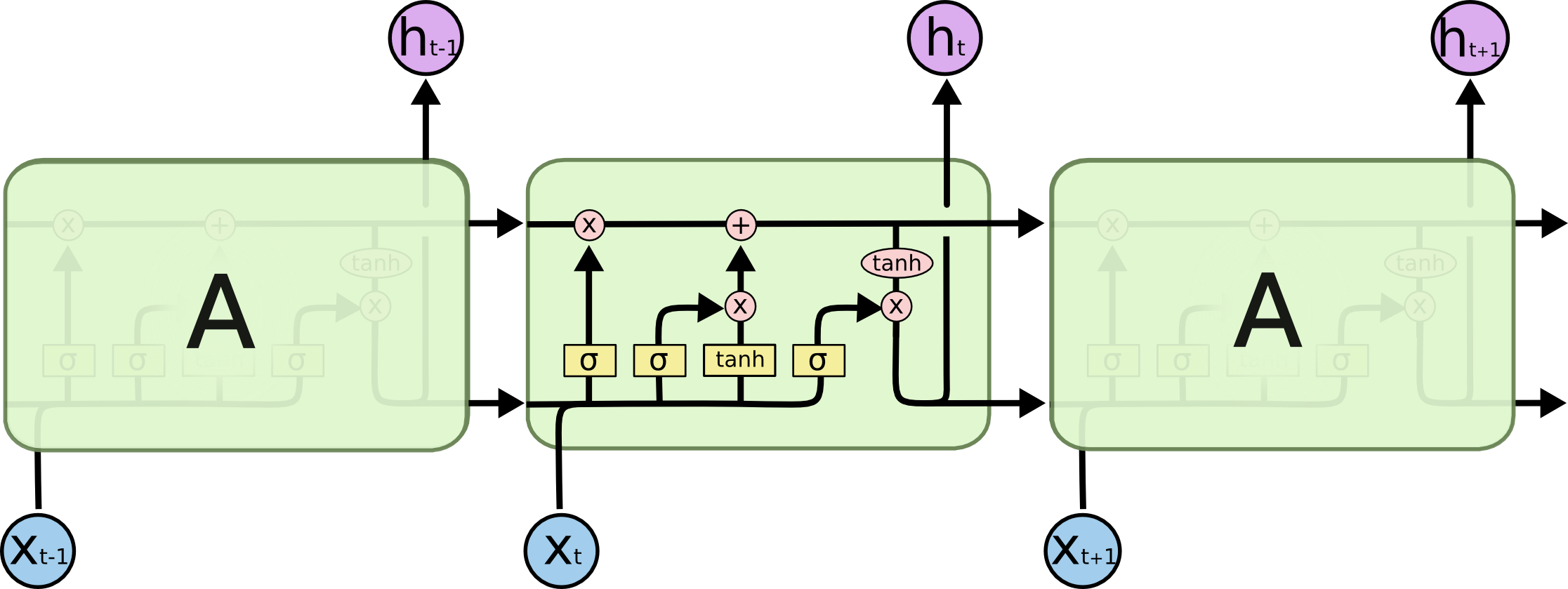
在上图中,A 代表神经网络主体,
xt
是网络输入,
ht
是网络输出,循环结构允许信息从当前输出传递到下一次的网络输入。
这些循环让递归神经网络看起来有点神秘,然而,如果你再进一步思考一下,它与传统神经网络并没有太多不同。一个递归神经网络可以看多是一个网络的多次拷贝,每次把信息传递给他的继任者。让我们把网络展开,你会看到发生了什么。
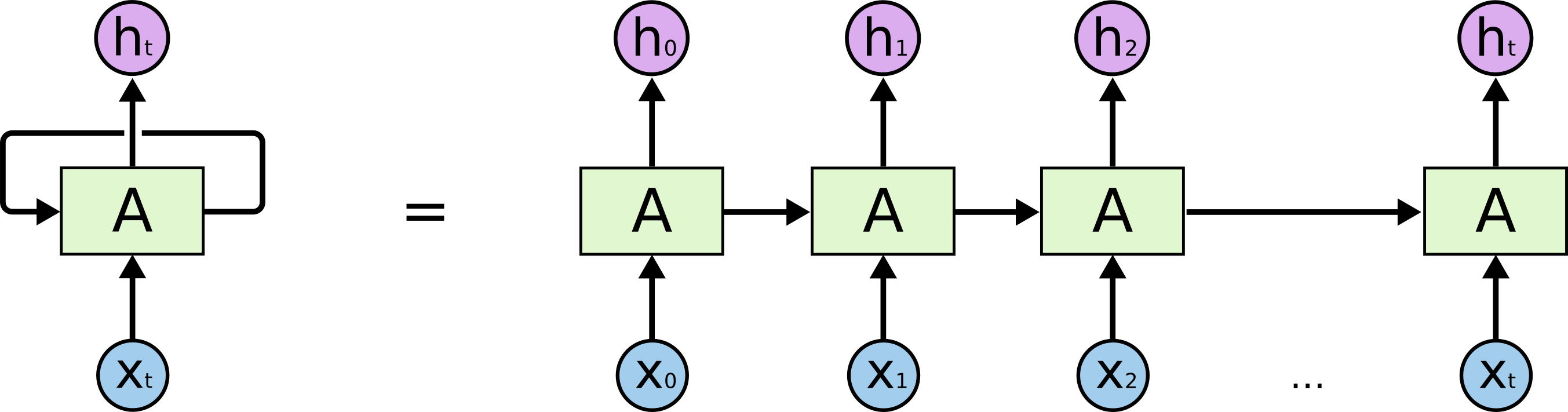
这种链型的自然结构表明递归神经网络与序列和列表有着天然的联系,他们是处理这些序列数据天然的神经网络架构。
当前,它们已经被应用了!最近的几年中,RNNs在很多问题上取得了惊人的成功:语音识别,语言模型,翻译,图像注释。。。这个名单还在继续延长。我将讨论一下Andrej Karpathy在他的博文The Unreasonable Effectiveness of Recurrent Neural Network中提到的RNNs令人惊奇的特性。 它们实在是太让人惊奇了!
这些成功必须要归功于它们使用了“LSTMs”, 递归神经网络的一种,它在许多任务中得到了比标准版本的RNN更好的结果。几乎所有建立的递归神经网络上的,令人惊喜的结果,都是使用LSTMs得到的。这篇文章将会探索这个神奇的神经网络。
长期依赖的问题
人门希望RNNs能够连接之前的信息到当前的任务中,例如,使用之前的图像帧信息去辅助理解当前的帧。如果RNNs可以做到这个,它们将会特别的有用,但是它们可以做到吗?这要视情况而定。
有时,我们仅仅需要使用当前的信息去执行当前的任务。例如, 一个语言模型试图根据之前的单词去预测下一个单词。如果我们试图去预测“the clouds are in the sky”,我们不需要更多的上下文信息–很明显下一个单词会是sky。在类似这种相关信息和需要它的场合并不太多的情景下,RNNs可以学习使用之前的信息。
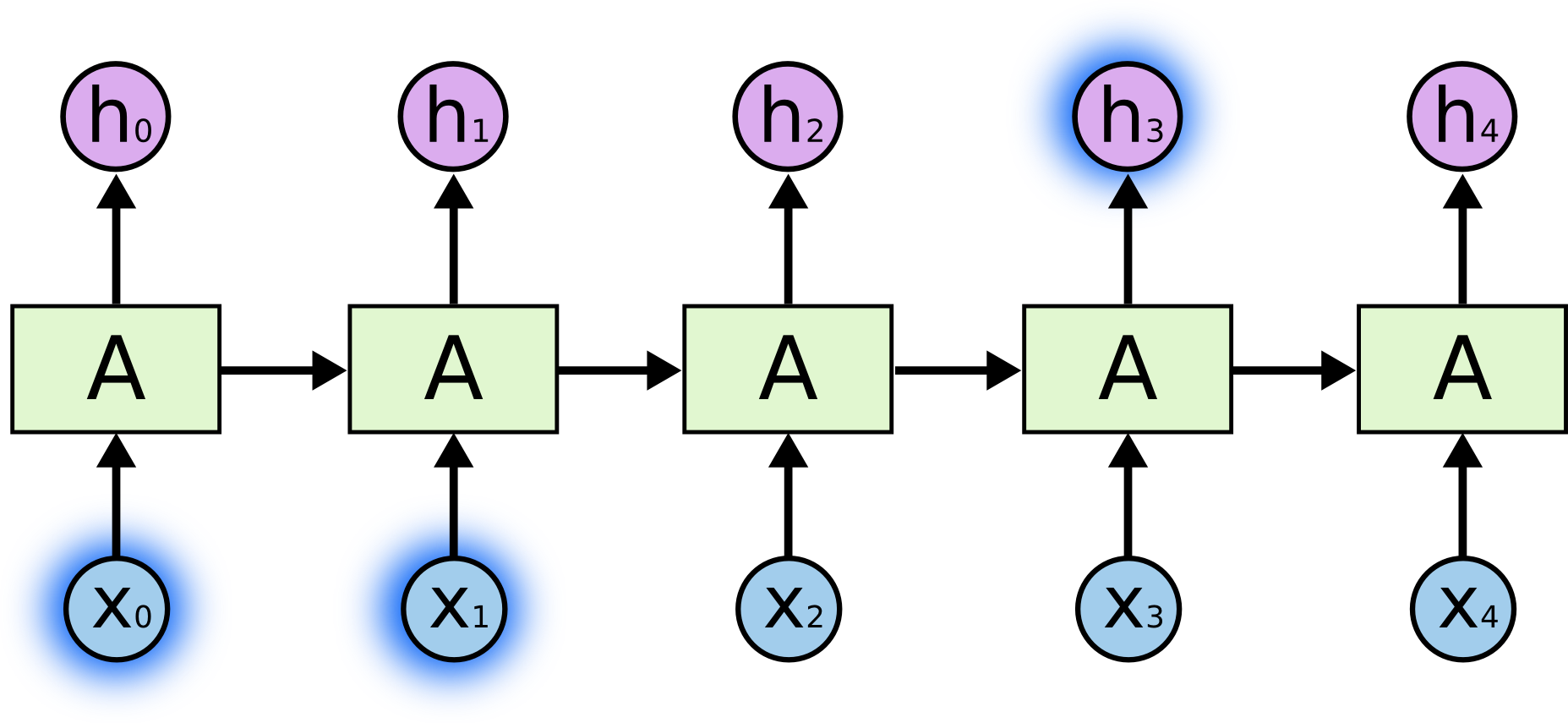
但是,也有很多场景需要使用更多的上下文。当我们去尝试预测“I grew up in France…I speak fluent French”的最后一个单词,最近的信息表明下一个单词应该是语言的名字,但是如果我们想缩小语言的范围,看到底是哪种语言,我们需要France这个在句子中比较靠前的上下文信息。相关信息和需要预测的点的间隔很大的情况是经常发生的。
不幸的事,随着间隔的增大,RNNs连接上下文信息开始力不从心了、.
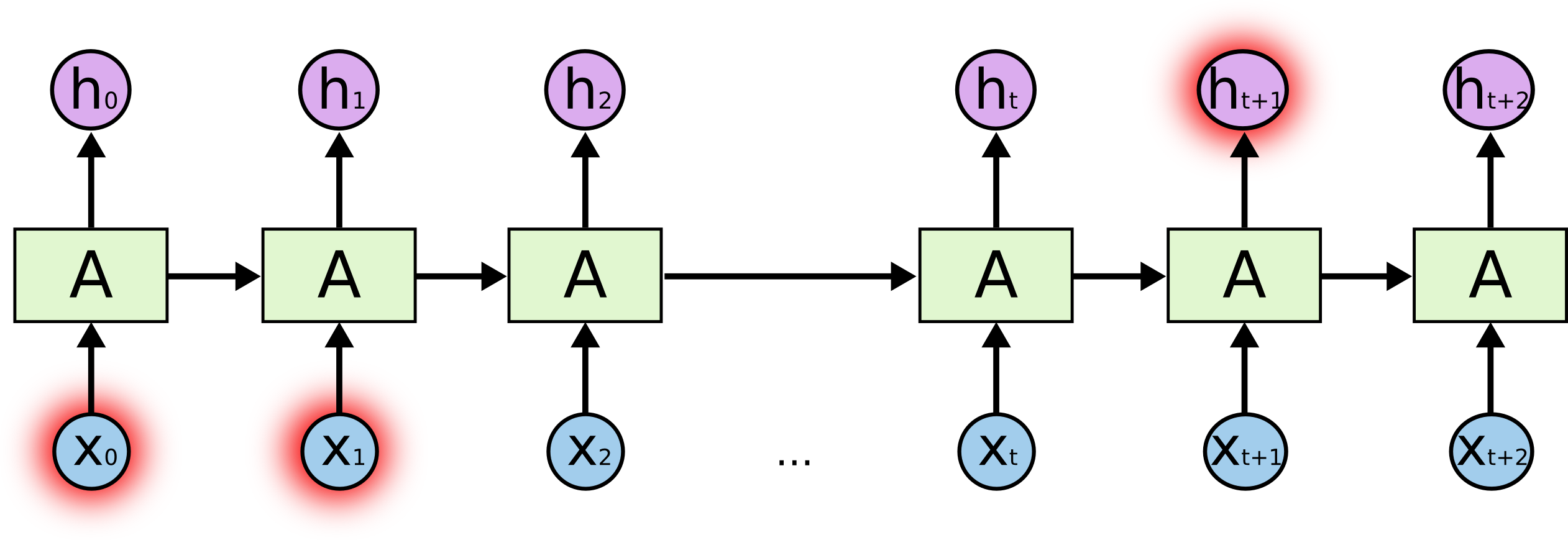
理论上RNNs完全有能力处理这种“长期依赖(Long-term dependencies)”问题。人们可以精心的选择参数去接着这类问题。令人沮丧的是,实践表明RNNs不能完美的学习“长期依赖(Long-term dependencies)”。Hochreiter(1991)和Bengio,et al,(1994)发现了一些为什么RNNs在这些问题上学习相当困难的根本原因。
谢天谢地,LSTMs没有这些问题。
LSTM 网络
长短期记忆网络–通畅叫做”LSTMs”–是一种特殊的RNNs, 它能够学习长期依赖。LSTM由Hochreiter&Schmidhuber(1997)引入,后来在很多人的努力下变得越来越精炼和流行。它们在大量的问题上有惊人的效果,现在被广泛的使用。
LSTMs被明确的设计用来解决长期依赖问题,记住长时间段的信息是他们的必备技能,不像RNNs那么费力去做还做不好。
所有的递归神经网络都有重复神经网络本身模型的链式形式。在标准的RNNs, 这个复制模块只有一个非常简单的结构,例如一个双极性(tanh)层。
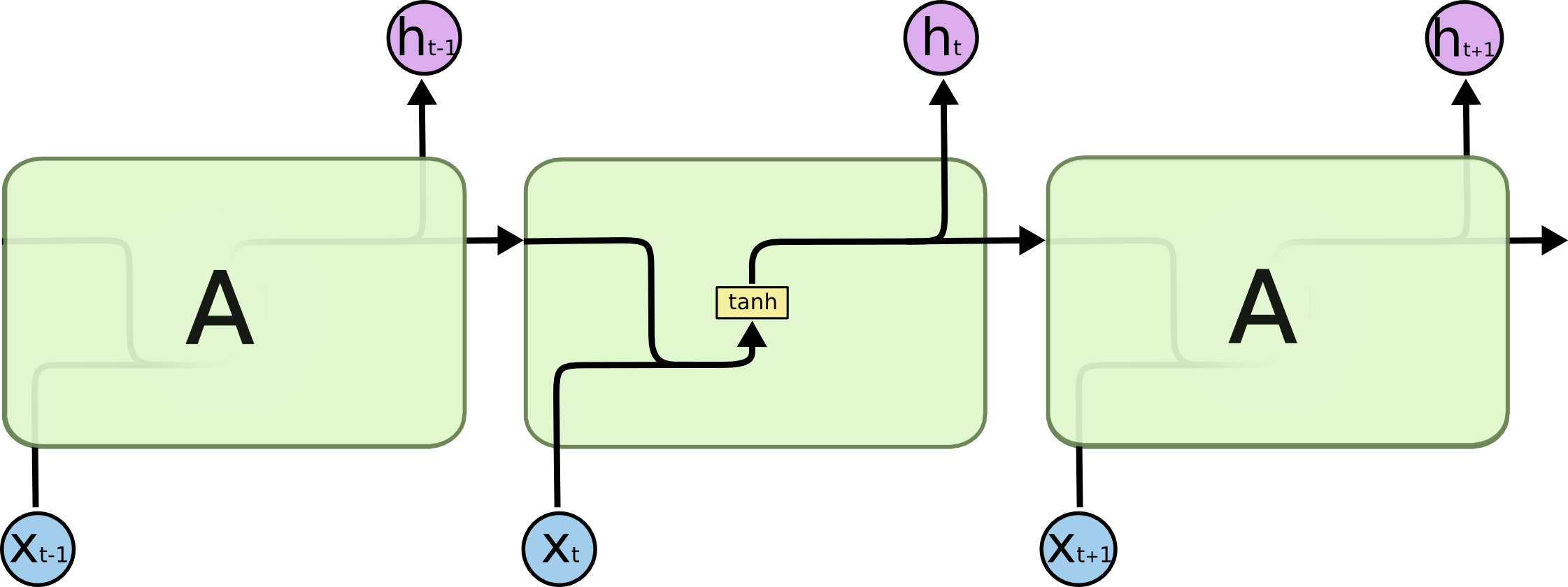
LSTMs 也有这种链式结构,但是这个重复模块与上面提到的RNNs结构不同:LSTMs并不是只增加一个简单的神经网络层,而是四个,它们以一种特殊的形式交互。
别担心中间到底发生了什么。我们接下来会一步一步的理解这个LSTM图。首先,我们要首先适应一下我们将会使用的符号表示方法。

在上图中,每条线表示一个向量,从一个输出节点到其他节点的输入节点。这个粉红色圆圈表示逐点式操作,就像向量加法。黄色的盒子是学习好的神经网络的层。线条合表示联结,相反,线条分叉表示内容被复制到不同位置。
LSTMs背后的核心思想
LSTMs的核心之处就是它的神经元状态,如下图中所示,上面那条贯穿整个结构的水平线。
神经元状态就像是一个传送带。它的线性作用很小,贯穿整个链式结构。信息很容易在传送带上传播,状态却并不会改变。
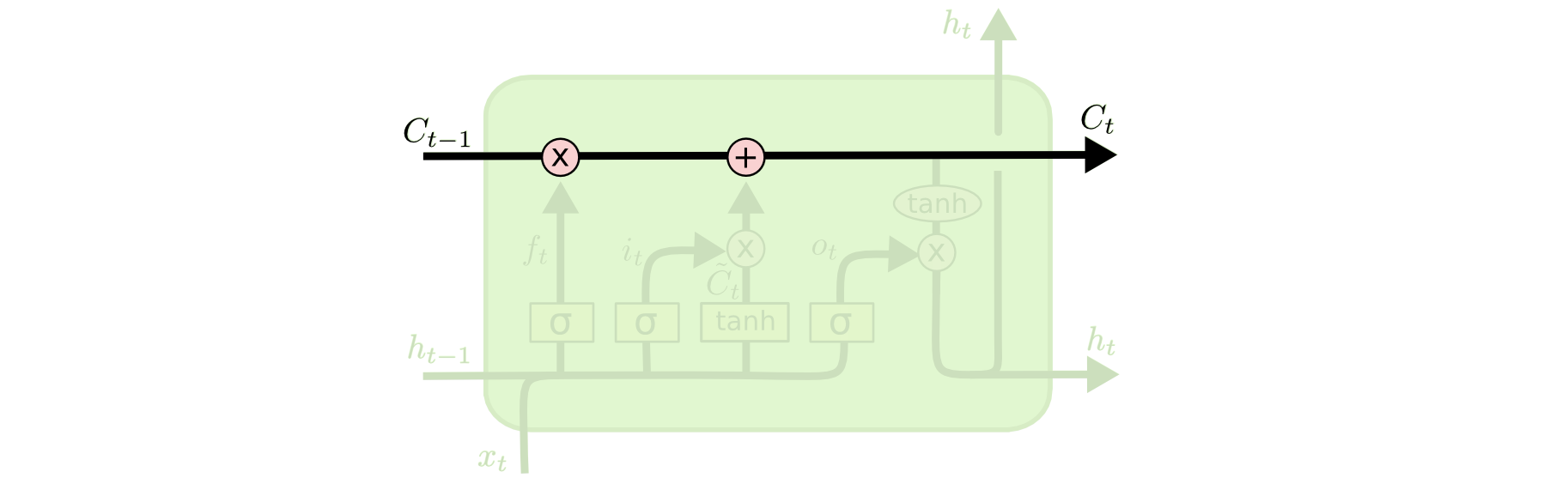
LSTM有能力删除或者增加神经元状态中的信息,这一机制是由被称为门限的结构精心管理的。
门限是一种让信息选择性通过的方式,它们是由Sigmoid神经网络层和逐点相乘器做成的。
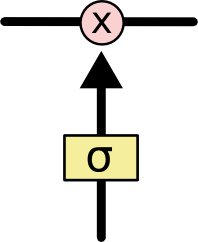
Sigmod层输出0~1之间的数字,描述了一个神经元有多少信息应该被通过。输出“0”意味着“全都不能通过”,输出“1”意味着“让所有都通过”。
一个LSTM有三个这样的门限,去保护和控制神经元状态。
一步一步的推导LSTM
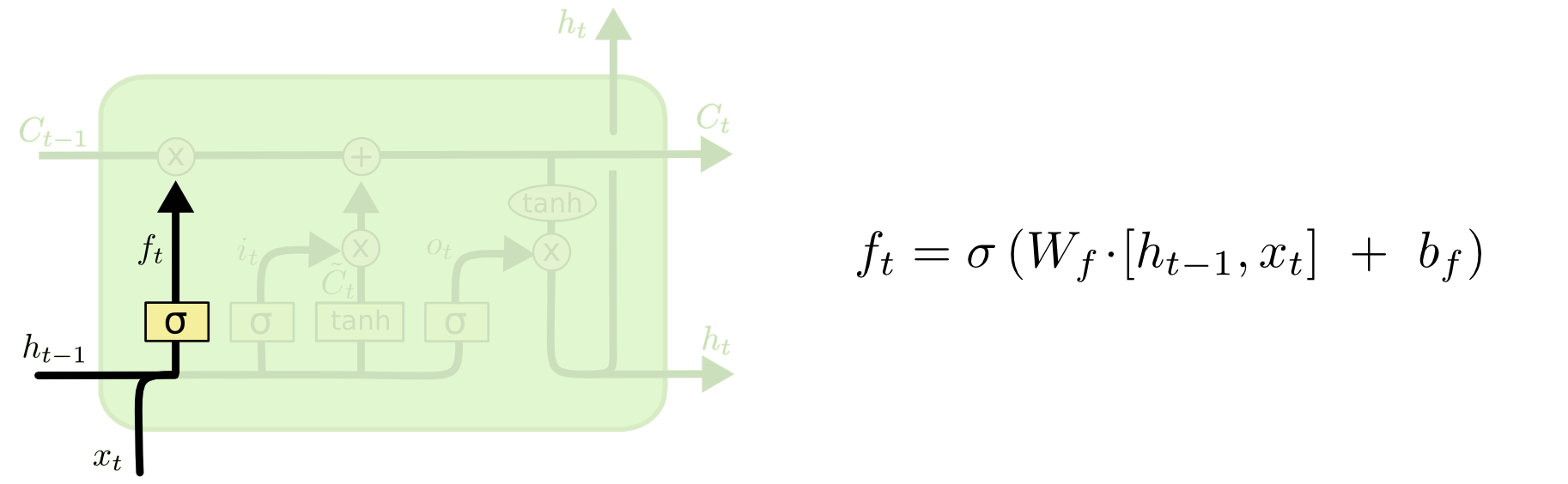
LSTM的第一步就是决定什么信息应该被神经元遗忘。这是一个被称为“遗忘门层”的Sigmod层组成的。它输入
ht−1
和
xt
,然后在
Ct−1
的每个神经元状态输出0~1之间的数字。“1”表示“完全保留这个”,“0”表示“完全遗忘这个”。
让我们再次回到那个尝试去根据之前的词语去预测下一个单词的语言模型。在这个问题中,神经元状态或许包括当前主语中的性别信息,所以可以使用正确的代词。当我们看到一个新的主语,我们会去遗忘之前的性别信息。
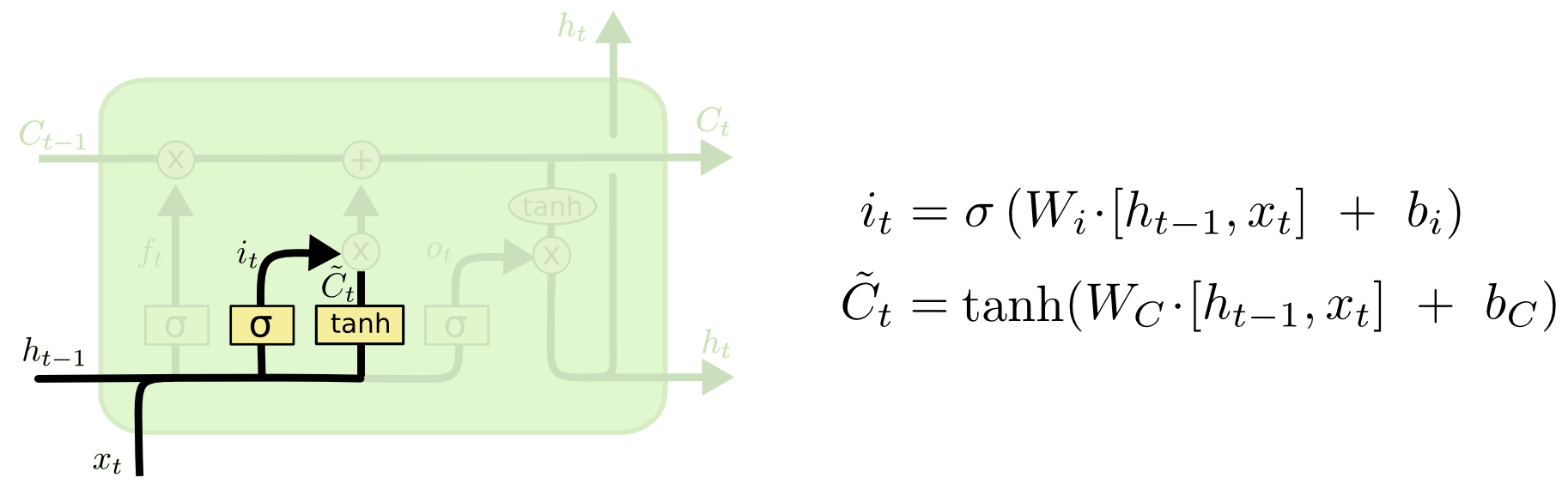
下一步就是决定我们要在神经元细胞中保存什么信息,这包括两个部分。首先,一个被称为“遗忘门层”的Sigmod层决定我们要更新的数值。然后,一个tanh层生成一个新的候选数值,
Ct˜
,它会被增加到神经元状态中。在下一步中中,我们会组合这两步去生成一个更新状态值。
在那个语言模型例子中,我们想给神经元状态增加新的主语的性别,替换我们将要遗忘的旧的主语。
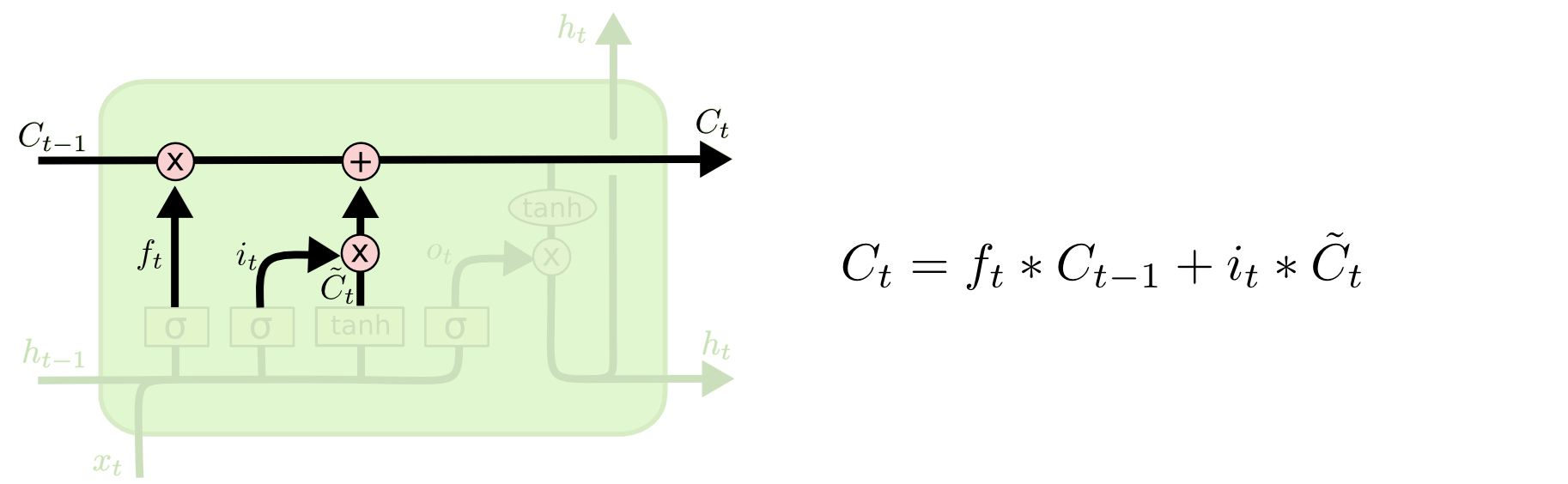
是时候去更新旧的神经元状态
Ct−1
到新的神经元状态
Ct
了。之前的步骤已经决定要做什么,下一步我们就去做。
我们给旧的状态乘以一个
ft
,遗忘掉我们之前决定要遗忘的信息,然后我们增加
it∗Ct˜
。这是新的候选值,是由我们想多大程度上更新每个状态的值来度量的。
在语言模型中,就像上面描述的,这是我们实际上要丢弃之前主语的性别信息,增加新的主语的性别信息的地方。
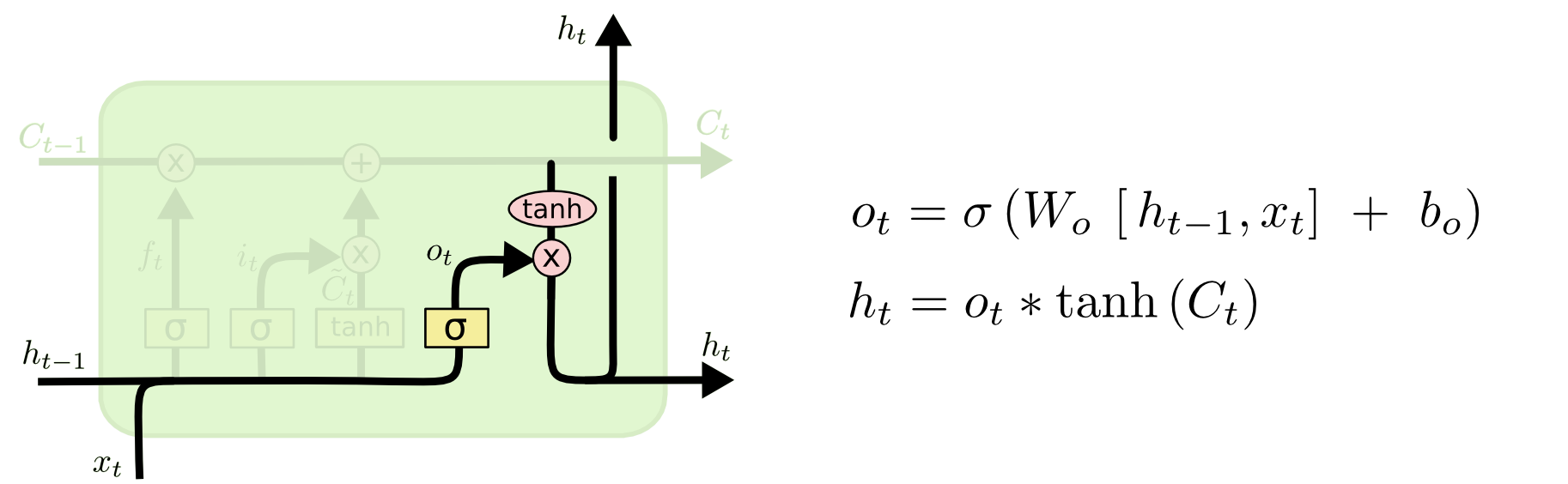
最后,我们要决定要输出什么。这个输出是建立在我们的神经元状态的基础上的,但是有一个滤波器。首先,我们使用Sigmod层决定哪一部分的神经元状态需要被输出;然后我们让神经元状态经过tanh(让输出值变为-1~1之间)层并且乘上Sigmod门限的输出,我们只输出我们想要输出的。
对于那个语言模型的例子,当我们看到一个主语的时候,或许我们想输出相关动词的信息,因为动词是紧跟在主语之后的。例如,它或许要输出主语是单数还是复数的,然后我们就知道主语联结的动词的语态了。
长短期记忆神经网络的变体
上面描述的都是常规的LSTM,但并不是所有的LSTMs都是上面这种模式。实际上,几乎每篇包含LSTMs模型的论文中,LSTMs都有一些差异,这些差异非常微小,但是它值得提及一下。
Gers & Schmidhuber(2000)引入了一个流行的LSTM变体,他增加了一个“窥视孔连接”。这意味着我们让门限层监视神经元状态。
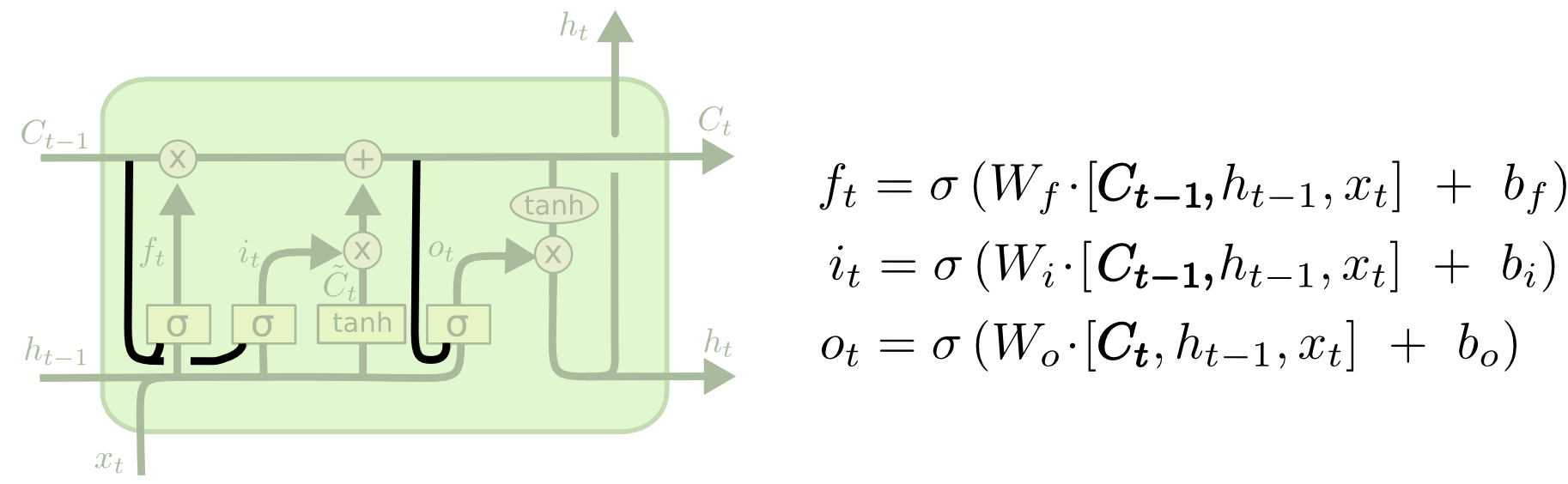
上图中给每个门限增加了窥视孔,但是有些论文,只给一部分门限增加窥视孔,并不是全部都加上。
另外一个变体是使用组合遗忘和输入门。而不是分开决定哪些神经元需要遗忘信息,哪些需要增加新的信息,我们组合起来决定。我们只遗忘那些需要被放入新信息的状态,同样,我们只在旧的信息被遗忘之后才输入新的信息。
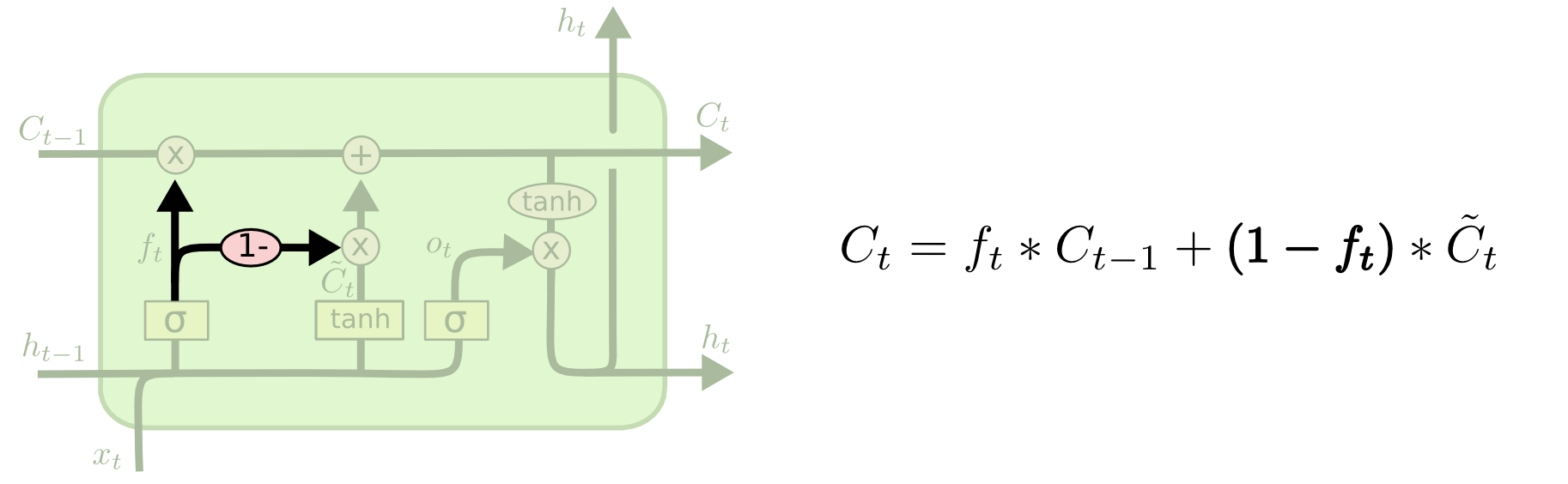
一个更神奇的LSTM变体是门递归单元(Gated Recurrent Unit, GRU),由Cho, et al(2014),它组合遗忘们和输入门为一个“更新门”,它合并了神经元状态和隐层状态,并且还做了一些其他改变。最终这个模型比标准的LSTM模型简单一些,并且变得越来越流行。

这里只介绍了几个最有名的LSTM的变体,还有更多变体没有介绍,就像Yao, et al.(2015)深度门递归神经网络(Depth Gated RNNs)。这里也有一些处理长期依赖问题问题的完全不同的方法,就像Koutnik, et al(2014)提出的时钟机递归神经网络(Clockwork RNNs)。
这些变体中哪个是最好的?这些差异重要吗?Greff, et al. (2015)做了一个流行LSTM变体的比较,他发现这都是一样的。Jozefowicz, et al. (2015)测试了一万多种RNN结构,发现一些RNN结构在某些特定任务中结果好于LSTMs。
结论
文章开头,我提到了人们使用RNNs取得了卓越的成果,本质上所有的这些结果都是使用LSTMs取得的。他们的确在多数任务上表现的更好。
写下来一系列等式以后,LSTM s看起来挺吓人的,然而,我们在文中一步一步的解释它以后它看起来可以理解了。LSTMs在我们能够用RNNs取得的结果中取得了更大的进步。我们不禁想问:是否有比LSTMs更好的模型?学者一致认为:“有的!这里有下一步,它就是“注意力”!”(Yes! There is a next step and it’s attention!,这里的”attention”翻译成“注意力”不知道是否合适”?)一个观点是让RNN的每一步都监视一个更大的信息集合,并从中挑选信息。例如:如果你使用 RNN去为一幅图像生成注释,它会从图像中挑选中挑选一部分去预测输出单词。实际上,Xu, et al. (2015) 确实是这样做的–如果你想去探索“注意力”,这或许是一个有趣的起点!这里还有一些使用“注意力”得到的有趣的结果,并且还有更多人在使用这个。
“注意力”并不是唯一的RNN研究热点。例如, 格点LSTMs(Grid LSTMs),Kalchbrenner, et al. (2015)看起来非常有前途。在生产环境中使用RNNs模型,就像Gregor, et al. (2015), Chung, et al. (2015)或者 Bayer & Osendorfer (2015)–也看起来很有趣。最近几年递归神经网络很流行,从趋势来看,未来还会更流行。
致谢
我衷心感谢很多帮助我更好理解LSTMs,为文章提供插图和提供反馈的人。
我很感谢我在Google的很多同事给我的反馈,特别是Oriol Vinyals,Greg CorradoJon Shlens,Luke Vilnis和Ilya Sutskever。我也很感谢其他朋友和同事花费时间帮助我,包括Dario Amodei和Jacob Steinhardt,我特别感谢Kyunghyun Cho对我的插图进行的超乎寻常的思考。
在这篇文章写之前,我试着在两个我教授的神经网络课程研讨会中解释LSTMs。谢谢每个耐心参加我课程并且给我反馈的人。
- 除了原始作者外,很多人给LSTM模型做了贡献。一个不完全的列表是:Felix Gers,Fred Cummins,Santiago Fernandez,Justin Bayer, Daan Wierstra, Julian Togelius, Faustian Gomez, Matteo Gagliolo, and Alex Graves
更多博文
Conv Nets: A Modular Perspective
Neural Networks, Manifolds, and Topology















 1265
1265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









