







1.物理外部存储,最典型的是磁盘或者disk,根据柱面,磁道,扇区来定位。柱面指定半径,磁道指定哪一块盘(通常是若干磁盘为一组),扇区指定在磁盘的哪一块。
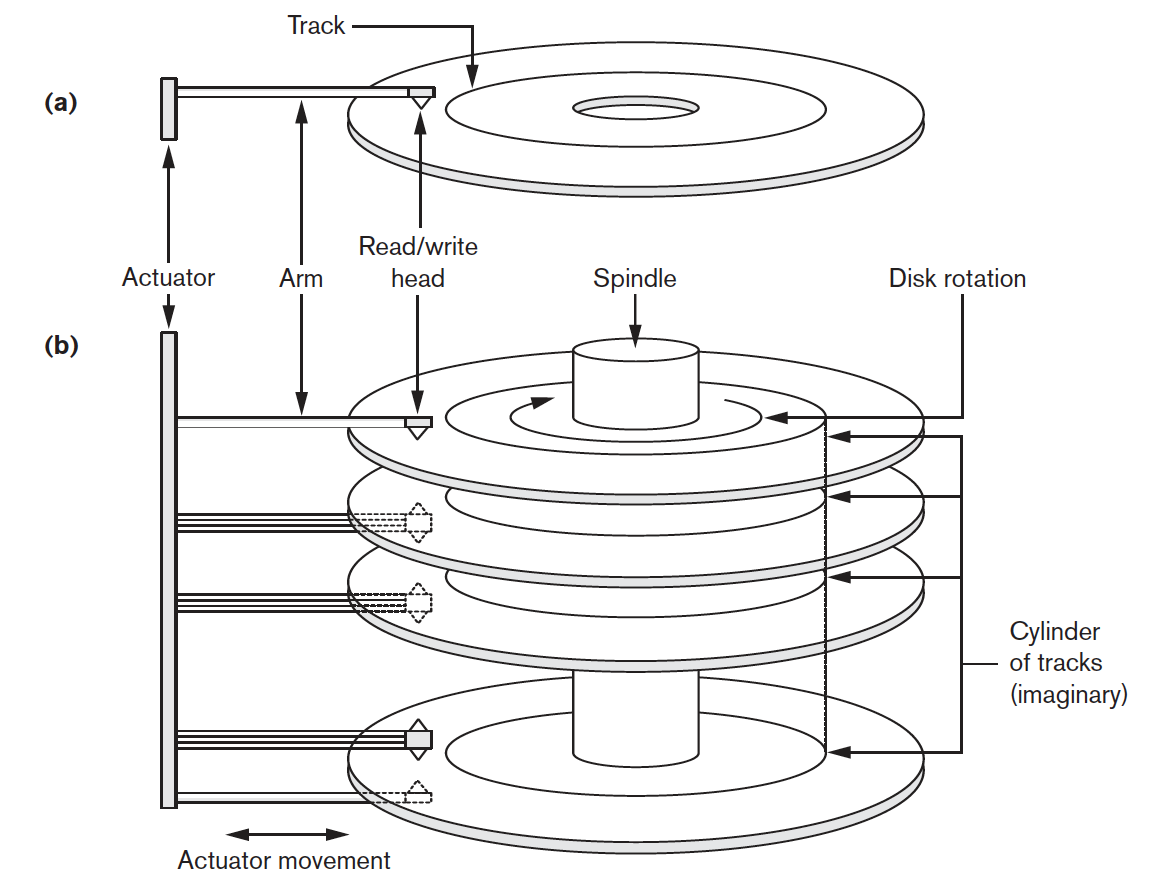
2.Block,Block是缓冲区,操作系统IO操作总是读取一块数据进入内存,这样相邻的数据可能再一次读取中就可以得到。block大小是对应计算机IO的,这个大小和磁盘的扇区大小其实是两个概念。磁盘大小是磁盘生产时就决定的。但是IO的缓冲区大小与计算机有关,这是两个不同的区域,操作系统可能会根据磁盘驱动或者控制器来划分磁盘block。
3.记录存储,数据库文件的记录是逐条存入block的。可是有序也可以无序。但是如果有序,只能是根据一个或者一组关键字做排序,不可能根据两个不同的标准排序。排序数据叫做sequential data,无序是heap。
4.索引可以分为两类,有序索引和无序索引。这里要说明,有序和无序是针对索引建立的属性在物理排列上是否有序,即sequential data或者heap,而不是索引本身是否有序。也就是说有序索引是对有序数据做的索引,无序索引是对无序数据做的索引。
(1)有序索引,又分为两类,即primary key索引和cluster索引。
primary key索引指关键字是一个key,即没有相同元素出现。那么索引有两个属性,<key,anchor pointer>每一个索引项只对应每一个数据块的第一个元素。相应查找时不能找等于k的,而是找到两个key,k1<k<k2,那么就在k1所指的块里面找数据。这样的索引也叫作undense索引,即只对数据块的第一个数据做一个索引项,可以节省空间。主要利用了数据本身是有序排放在磁盘的特性。
cluster索引,数据也是有序排放,但是该属性并不是一个key,即可能有重复元素出现。这时就为每一个不同的key建立一个索引项,指针指向第一数据所在的块。这个同样也是undense索引。
(2)无序索引,因为数据是无序排放的,因此这里的索引必须是dense的,即必须为每一条数据做一个索引项而不是每一个数据块。只有在有序数据时才可以用undense索引。
也可以分两类,如果属性是key,那么为每一个不同的key做一个索引项,指向该数据的位置(不是块内第一个数据)。如果是非key得属性,那么每一个索引项指向一个记录地址的list,list包含了所有关键字为该值得记录位置。
因为有序属性只可能存在一个,因此有序索引只能至多存在一个,或者primay或者cluster。通常用于主键。那么建立主键索引以后如果想让其他属性也有索引,可以使用secondary 索引。
下面是一些例子:
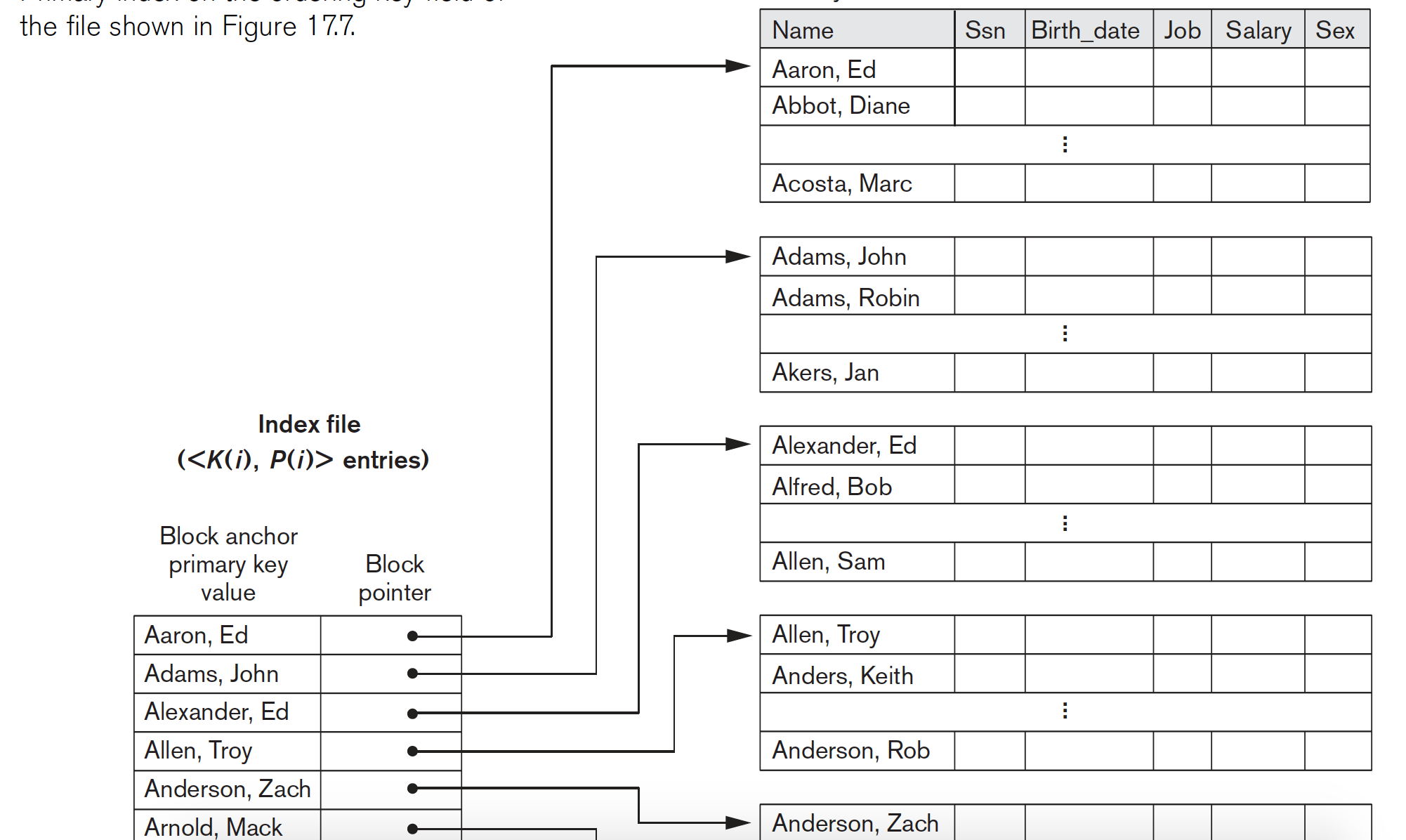
primary索引
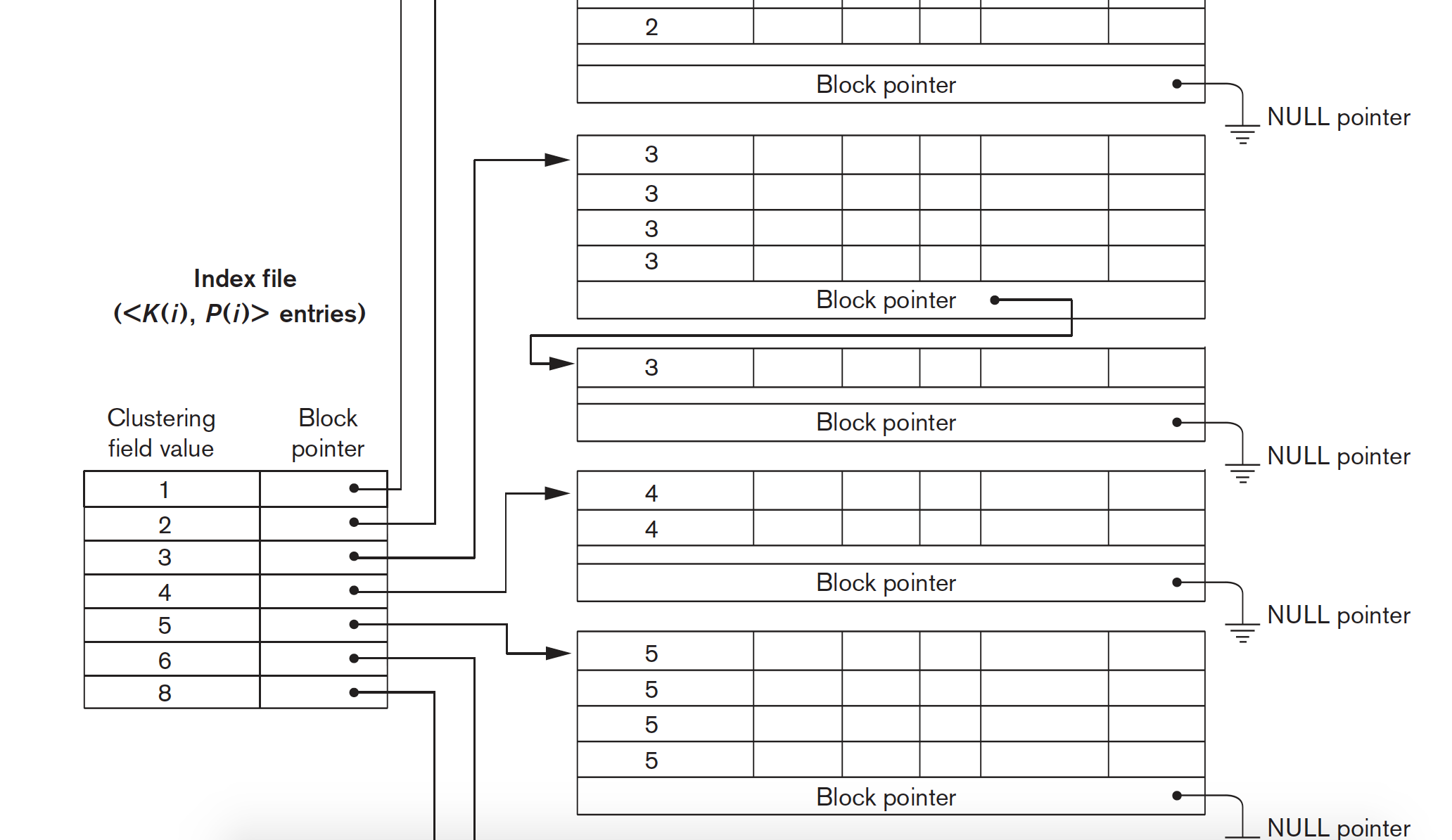
cluster索引

secondary 索引(key)
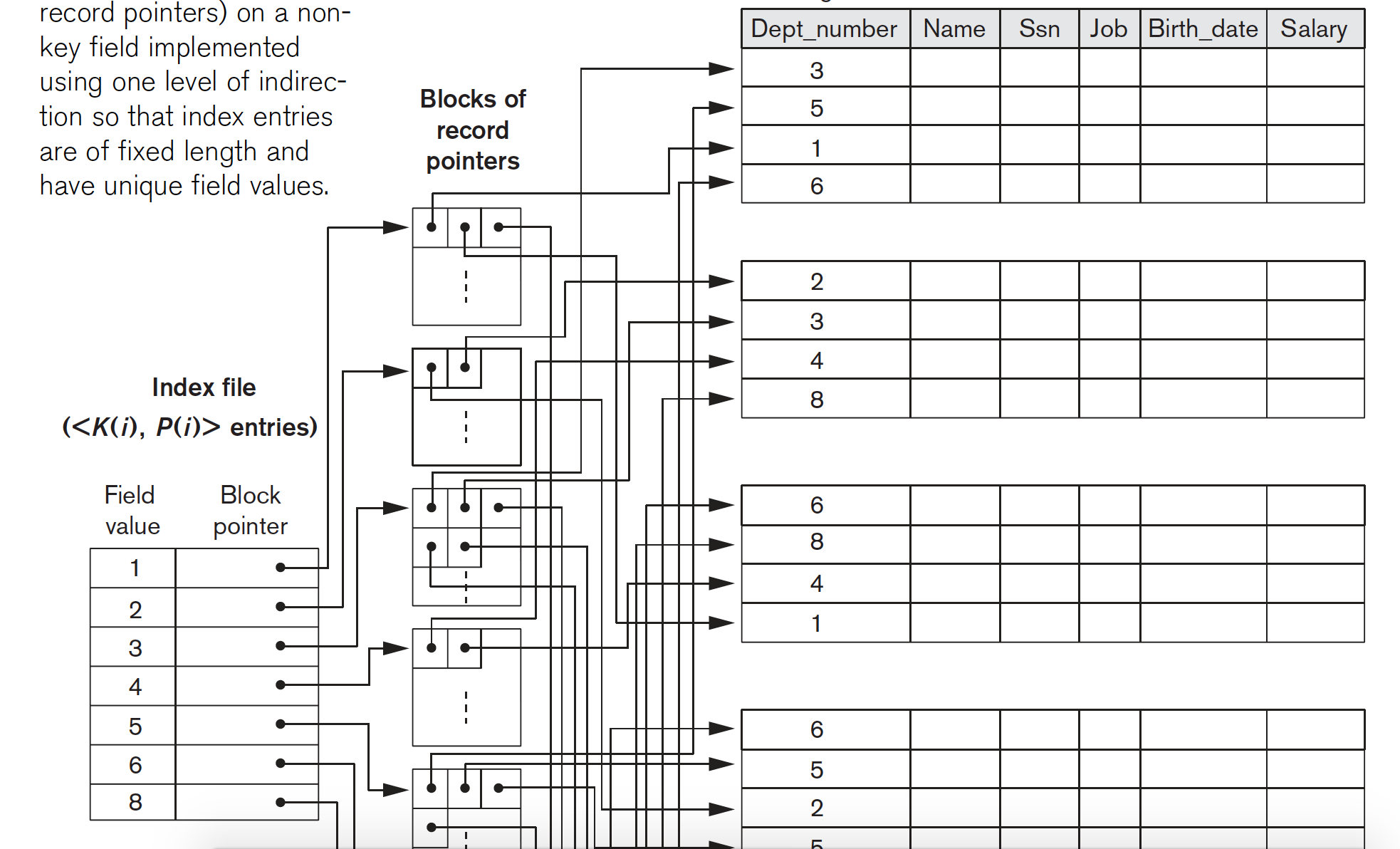
secondary索引(非key)














 883
883











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









