







| 💻 [code] | 🕹️ [demo] | Paper
缩写词广泛存在于各种场景,比如网络媒体,医疗文本,科技文献等等。比如下面这个例子,“AI”这个缩写可以指人工质智能(Artificial Intelligence),也可以指合理摄入(Adequate Intake)。
但是缩写的存在会影响我们对文本的理解,尤其对于机器,它们不能很好理解这些缩写的含义后就不能执行分配的任务。因此我们需要对缩写进行消歧或者改写成原有的形式。

缩写消歧有着广泛应用,比如搜索和信息抽取,下面给出了一个信息抽取的例子:

这篇文章中我们介绍一个目前最大的缩写词消歧的资源GLADIS. 它主要有4个组件构成:
- 缩写词典。这个是目前为止开源的最大缩写词典,包含160万缩写词和640万扩充词
- 评估数据集。基于缩写词典,GLADIS构建了包含通用,医疗,科技领域的三个评估数据集。我们可以使用它们评估已有消歧系统的性能。这是目前最大最具挑战的数据集
- 预训练语料。目前还没有使用预训练技术解决缩写消歧的方法。这个语料包含1亿6千万带有缩写的句子。
- AcroBERT。这是第一个用于缩写消歧的语言模型。跟现有的消歧系统相比,它能带来巨大的性能提升。

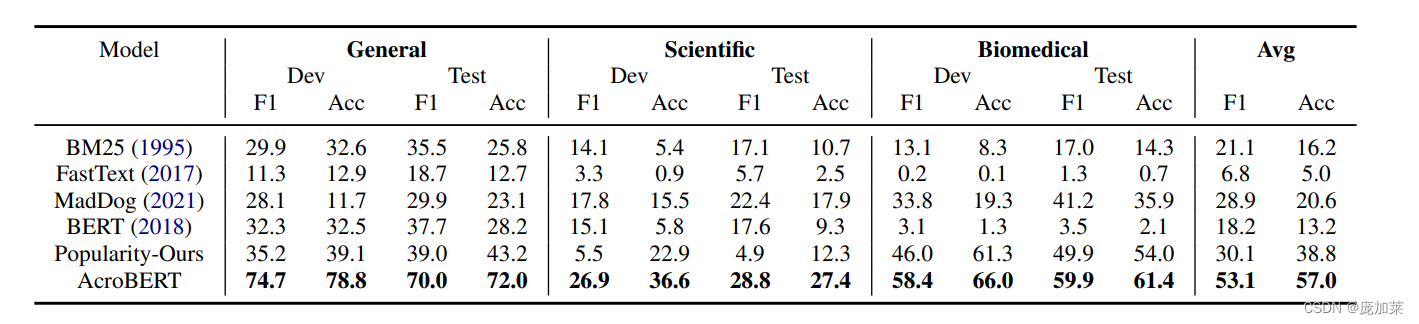
性能评估
AcroBERT是目前最先进的缩写消歧模型,它在不同领域的数据集上都取得了领先的结果:
端到端的缩写消歧系统
用户可以在Huggingface上使用AcroBERT,给一个输入,它可以首先识别句子中的缩写,然后从GLADIS词典中找出最相关的扩写词。🤗 AcroBERT

代码使用
from inference.acrobert import acronym_linker
# input sentence with acronyms, the maximum length is 400 sub-tokens
sentence = "This new genome assembly and the annotation are tagged as a RefSeq genome by NCBI."
# mode = ['acrobert', 'pop']
# AcroBERT has a better performance while the pop method is faster but with a low accuracy.
results = acronym_linker(sentence, mode='acrobert')
print(results)
## expected output: [('NCBI', 'National Center for Biotechnology Information')]
| 💻 [code] | 🕹️ [demo] | Paper
作者主页:chenlihu.com
如果觉得以上论文或代码有用,请引用或者给出小星星😊
@inproceedings{chen2023gladis,
title={GLADIS: A General and Large Acronym Disambiguation Benchmark},
author={Chen, Lihu and Varoquaux, Ga{\"e}l and Suchanek, Fabian M},
booktitle={EACL 2023-The 17th Conference of the European Chapter of the Association for Computational Linguistics},
year={2023}
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









