







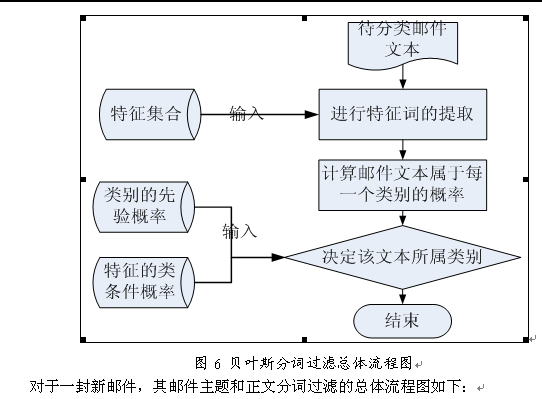
贝叶斯过滤器的理论介绍





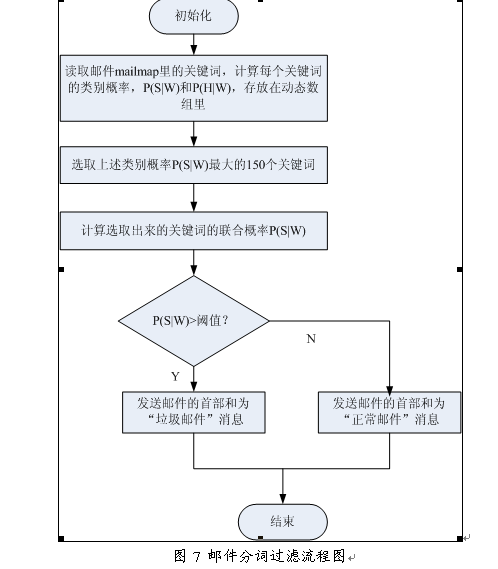
代码示例:
#include "ProbC.h"
#include "common.h"
#define SPAMSIZE 50
#define PAMSIZE 50
#define MAXWORDS 15
FindWordNum(char *word,map<string,int> maillib)
{
int wordnumslib;
wordnumslib = FindWordNumsLib(word,maillib);
return wordnumslib;
}
double SinWordProb(char *word,map<string,int>spam_map,map<string,int>pam_map)
{
/*p(s|w) = p(w|s)/(p(w|s) + p(w|h)) */
int wordspamnum;
int wordpamnum;
double wordspamlibprob = 0.0;
double wordpamlibprob =0.0;
double mailspamprob;
wordspamnum = FindWordNum(word,spam_map);
wordpamnum = FindWordNum(word,pam_map);
printf("wordspamnum = %d,wordpamnum = %d\n",wordspamnum,wordpamnum);
if((wordpamnum !=0) && (wordspamnum == 0))
{
wordspamlibprob = 0.1;
wordpamlibprob = double(wordpamnum)/PAMSIZE;
mailspamprob = wordspamlibprob/(wordspamlibprob + wordpamlibprob);
return mailspamprob;
}
else if((wordpamnum ==0) && (wordspamnum != 0))
{
wordpamlibprob = 0.1;
wordspamlibprob = double(wordspamnum)/SPAMSIZE;
mailspamprob = wordspamlibprob/(wordspamlibprob + wordpamlibprob);
return mailspamprob;
}
else if((wordpamnum !=0) && (wordspamnum != 0))
{
wordpamlibprob = double(wordpamnum)/PAMSIZE;
wordspamlibprob = double(wordspamnum)/SPAMSIZE;
mailspamprob = wordspamlibprob/(wordspamlibprob + wordpamlibprob);
return mailspamprob;
}
else if((wordpamnum==0)&&(wordspamnum==0))
{
mailspamprob = 0.4;
return mailspamprob;
}
}
double *WordsMaxProb(map<string,int> mailmap,map<string,int> spam_map,map<string,int> pam_map)
{
int mailwordsize = 0;
double *wordsprob = NULL;
int index = 0;
char word[30] = {0};
double *result = NULL;
map <string,int> ::iterator iter;
mailwordsize = MapWordSizeStr(mailmap);
printf("mailwordsize = %d\n",mailwordsize);
wordsprob = (double*)calloc(mailwordsize,sizeof(double));
result = (double*)calloc(MAXWORDS,sizeof(double));
for(iter = mailmap.begin();iter!=mailmap.end();iter++)
{
strcpy(word,iter->first.c_str());
wordsprob[index++] = SinWordProb(word,spam_map,pam_map);
}
sort(wordsprob,wordsprob + mailwordsize);
for(index = mailwordsize-1;index >=0;index--)
{
printf("wordsprob[%d]:%f\n",index,wordsprob[index]);
}
if(MAXWORDS <=mailwordsize)
{
for(index = 0;index <MAXWORDS;index++)
{
result[index] = wordsprob[mailwordsize--];
}
}
else
{
result = wordsprob;
}
return result;
//free(wordsprob);
}
double WordsJointProb(double wordprob[],int wordnums)
{
//(p1 * p2 * ...p15)/(p1 * p2 * ...p15 +(1-p1) *(1- p2) * ...(1-p15))
double mailprob;
double tmpprob1 = wordprob[0];
double tmpprob2 = 1-wordprob[0];
int index;
for(index = 1;index < wordnums;index++)
{
tmpprob1 *= wordprob[index];
tmpprob2 *=(1-wordprob[index]);
}
mailprob = tmpprob1 / (tmpprob1 + tmpprob2);
return mailprob;
}参考链接: http://www.ruanyifeng.com/blog/2011/08/bayesian_inference_part_two.html















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









