







1.简单选择排序
基本思想:
给定待排数组,共n个元素,依次比较n个元素,选择出最大值(或最小值),与a[0]元素替换,然后比较剩下的n-1个元素,同样得到最大值最大值(或最小值),与a[1]元素替换,以此类推,重复进行。 直到n=1 。此时 数组顺序已排好(降序或升序)。
代码实现:
/**
简单选择排序
---基本思想:在要排序的一组数中,选出最小的一个数与第一个位置的数交换;
然后在剩下的数当中再找最小的与第二个位置的数交换,如此循环到倒数第二个数和最后一个数比较为止
简单选择排序法(Simple Selection Sort)就是通过n-i次关键字间的比较,
从n-i+1个记录中选出关键字最小的记录,并和第i(1≤i≤n)个记录交换之
**/
//对数组a进行 插入排序 ------升序
void simpleSlectSort(int *a,int n)
{
int min;
int i,j;
int temp;
for(i=0;i<n-1;i++)
{
min=i;
for(j=i+1;j<n;j++)
{
if(a[min]>a[j])
min=j;
}
if(min!=i) // a[i] 与a[min] 互换
{
a[i]=a[i]^a[min];
a[min]=a[i]^a[min];
a[i]=a[i]^a[min];
//两个数互换的另一种实现方式::缺点: 数值大时 容易溢出
// a[i]=a[i]+a[min];
// a[min]=a[i]-a[min];
// a[i]=a[i]-a[min];
}
}
}
时间复杂度:外层循环(移动次数),最好情况 移动0次,最坏情况(逆序)执行n-1次,内存循环(比较次数): 执行O(1+2+...+n-1)=O(n(n-1)/2) 所以总的时间复杂度为
移动次数+比较次数=O(n-1)+O(n(n-1)/2)=O(n^2)).
2.堆排序
基本思想:在要排序的一组数中,利用堆的性质 ,选出最小的一个数与第一个位置的数交换;
然后在剩下的数当中再找最小的与第二个位置的数交换,如此循环到倒数第二个数和最后一个数比较为止。
堆排序是基于简单选择排序的算法的一种改进算法。区别:每次循环比较时,利用堆的性质,得到最大值或最小值。
<1>现在简单介绍一下堆的性质:
若将此序列所存储的向量R[1..n]看做是一棵完全二叉树的存储结构,则堆实质上是满足如下性质的完全二叉树:
树中任一非叶子结点的关键字均不大于(或不小于)其左右孩子(若存在)结点的关键字。
即有:
ki<=k(2i)且ki<=k(2i+1)(1≤i≤ n) 小顶堆 (图二)
或
ki>=k(2i)且ki>=k(2i+1)(1≤i≤ n) 大顶堆(图一)
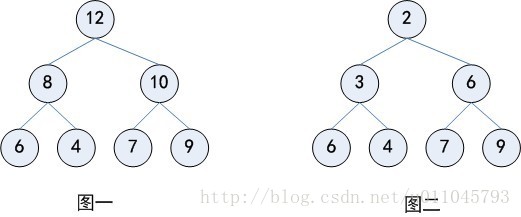
//k(i)相当于二叉树的非叶子结点,K(2i)则是左子节点,k(2i+1)是右子节点。
<2>.堆排序的步骤:
一、建立堆表。 将给定待排序数组元素 转换成二叉堆 。
二、 循环得到最大值(或是最小值),完成排序。
具体排序流程图例:
建堆过程:给定数组A
从第一个非叶子节点开始逐一比较 是否满足大顶堆的性质。
堆排序过程:
建好堆后 取堆顶元素(最大值),然后剩下的元素执行建堆 得新堆。重复比较。直至排好。
代码实现:
#include<stdio.h>
//对数组a进行 插入排序 ------升序
// 堆结构
typedef struct heap_t{
int *arr; //point for an array to store heap value.
int heapMaxIndex; //heap element max index number
int arrLength; //array length of arr
}Heap;
// 写函数使得 数组满足堆性质。
//思想是:从一个节点i,和他的孩子leftchild(i),rightChild(i)中找到最大的,
//然后其索引存放在largest中。如果i是最大的。那么i为根的子树已经是最大堆,程序结束。
//否则i的某个子节点有最大元素,那么i的值和largest的值交换。
//下标为largest的节点在交换后作为父节点,那么他可能又违反堆性质,因此递归调用该函数。
void maxHeapify(Heap *hp, unsigned int node)
{
// 某个节点:node
unsigned int left = (node+1) << 1 - 1; //left child = 2i-1, -1 ?:arr[0..n-1]
unsigned int right = (node+1) << 1 ; // right child = 2i
unsigned int largest = 0; //保存最大值
int heapMaxI = hp->heapMaxIndex;
if(left <= heapMaxI && hp->arr[left] > hp->arr[node])
largest = left ;
else
largest = node ; // 得最大节点
if(right <= heapMaxI && hp->arr[right > hp->arr[largest])
largest = right ;
if(largest!=node)
{
//exchange 最大值交换至node 点
hp->arr[largest]=hp->arr[largest]^hp->arr[node];
hp->arr[node]=hp->arr[largest]^hp->arr[node];
hp->arr[largest]=hp->arr[largest]^hp->arr[node];
maxHeapify(hp,largest);// 为何会有这一句
}else{
return ;
}
}
/*
对于1个个数为n的堆,从上面堆的图中可以分析得到,n/2-1之前的都是父节点。
之后的都是叶子节点,我们只需要对父节点进行maxHeapify就可以了。
n/2可以用右移运算n>>1。
*/
/**
arrp[]待排序数组 arrlength 表长 heap 堆表
**/
Heap *createHeap(int *arrp, int arrLength,Heap *heap)
{
int i;
heap->arr = arrp;
heap->heapMaxIndex = arrLength-1;
heap->arrLength = arrLength;
//for an heap a[0..n-1]; a[(n/2)..n-1] all are leaves
for(i = arrLength>>1-1; i >=0; i--)
maxHeapify(heap,i);
return heap;
}
//堆排序
/**
设堆的数组为A[0..n-1],调用maxHeapify函数就可以得到最大值,
然后将最大值和n-1互换,把堆的大小heapMaxIndex减1,再次调用maxHeapify,
又得到最大值,存放在A[0],再和A[n-2]互换,把堆的大小再减一,这样循环下去,
知道堆的大小为0。那么我们就得到了由小到大的排好序的数组。
**/
void heapSort(Heap *hp)
{
int tmp;
int last;
while(hp->heapMaxIndex>0)
{
last = hp->heapMaxIndex ;
//exchange
tmp = hp->arr[last];
hp->arr[last] = hp->arr[0];
hp->arr[0] = tmp;
hp->heapMaxIndex -= 1;
maxHeapify(hp,0); //make heap from root node 0 to heapMaxIndex
}
}
int main()
{
Heap hpa,*phpa;
int a[10]={2,13,3,9,29,15,98,55,67,9};
int i;
for(i=0;i<10;i++)
{
printf("%d\t",a[i]);
}
printf("\n");
printf("a[] sort by insert methods:\n");
phpa = createHeap(a,10,&hpa);
heapSort(phpa);
for(i=0;i<10;i++)
{
printf("%d\t",a[i]);
}
return 0;
}</pre><pre>堆排序代码参考 http://blog.csdn.net/caimo/article/details/7783970#sql
堆排序的性能分析:
它的运行时间主要是消耗在初始构建堆和在重建堆时的反复筛选上。
在构建堆的过程中,因为我们是完全二叉树从最下层最右边的非终端结点开始构建,将它与其孩子进行比较和若有必要的互换,对于每个非终端结点来说,其实最多进行两次比较和互换操作,因此整个构建堆的时间复杂度为O(n)。
在正式排序时,第i次取堆顶记录重建堆需要用O(logi)的时间(完全二叉树的某个结点到根结点的距离为.log2i.+1),并且需要取n-1次堆顶记录,因此,重建堆的时间复杂度为O(nlogn)。
所以总体来说,堆排序的时间复杂度为O(nlogn)。由于堆排序对原始记录的排序状态并不敏感,因此它无论是最好、最坏和平均时间复杂度均为O(nlogn)。这在性能上显然要远远好过于冒泡、简单选择、直接插入的O(n2)的时间复杂度了。
空间复杂度上,它只有一个用来交换的暂存单元,也非常的不错。不过由于记录的比较与交换是跳跃式进行,因此堆排序也是一种不稳定的排序方法。
另外,由于初始构建堆所需的比较次数较多,因此,它并不适合待排序序列个数较少的情况。















 338
338

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









