






从零开始实现SSD目标检测(pytorch)
特别说明:
- 本系列文章是Pytorch目标检测手册的翻译+总结
- 知其然知其所以然,光看论文不够,得亲自实现
第一章 相关概念概述
1.1 检测框表示
边界宽(bounding box)是包围一个物体(objective)的框,用来表示这个物体的位置、形状、*小等信息。不是最小外接矩形,仅仅是一个转动角度为 0 的框。如下图1-1所示:

表示框的方法有很多(不赘述),图1-1的方式为框的边界四个极值坐标\(x_{min},y_{min},x_{max},y_{max}\)。
但是这样做的有点缺点:
- 知道\(x_{min},y_{min},x_{max},y_{max}\),我们无法知道这个目标的更多信息(比例),必须画出来才有感官
- 如果没有图像的宽高,像素值毫无用处(其实还是无法知道比例信息)
改进方式如下图1-2所示

图1-2使用比例的方式,很直观的知道目标更多的信息
但是还有一个缺点:
- 直接看这个信息,我们不知道目标长宽信息(当然你自己可以另外计算)
- 也不知道中心位置(相对于边界,我们更关心中心)
再次改进的方式如下图1-3所示:

\(c_x,c_y,w,h\),中心点+宽高的方式,满足视觉信息最*化。
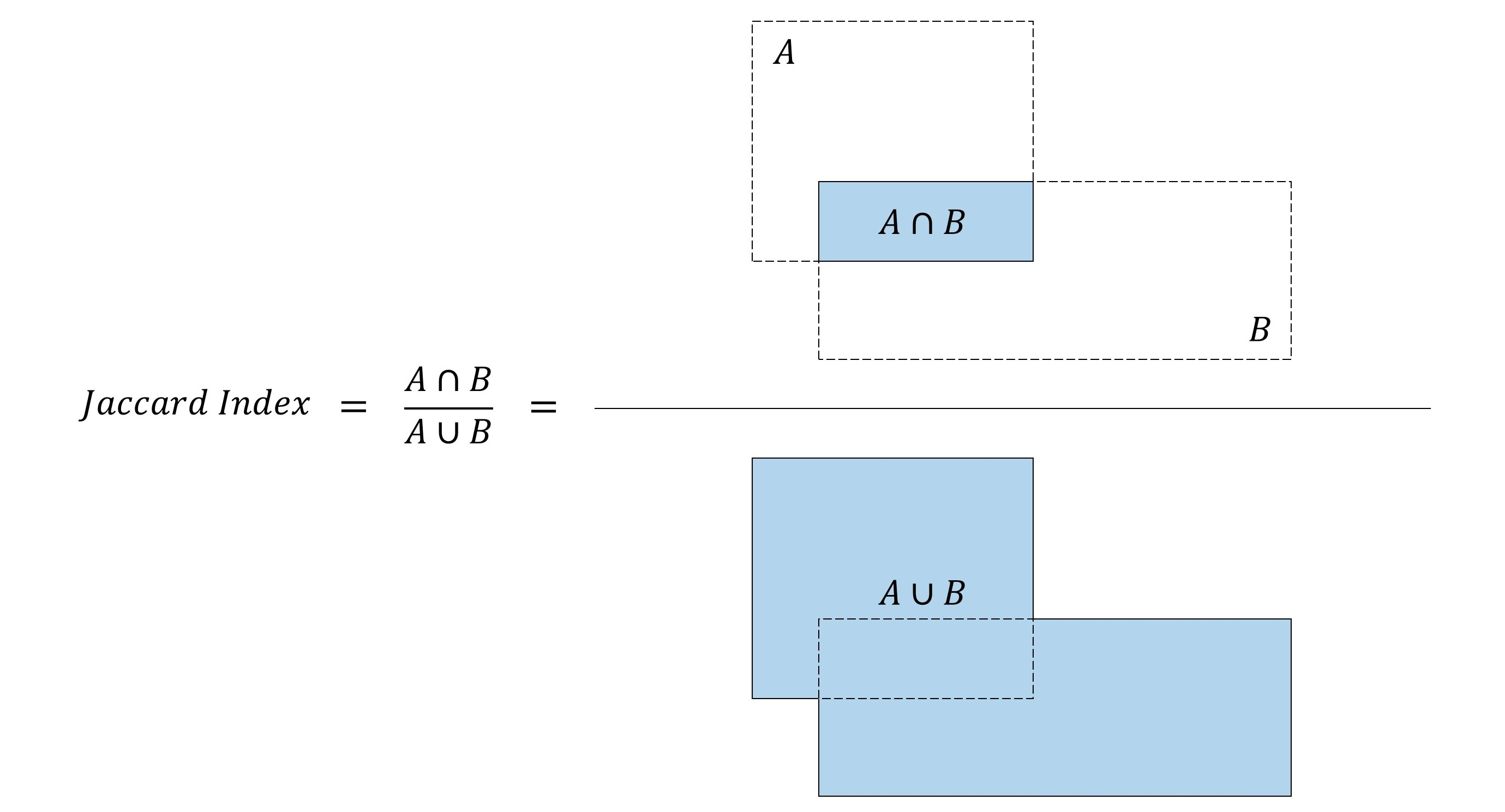
1.2 交并比
如何用来判断一个框检测的好与坏?
- 使用交集\(A \cap B\)
直接使用交集的*小去判断好坏,*尺度和小尺度不对等
比如:A和B*小都为100,交集50. C和D*小都为10,交集5.
如何说明这两组哪个好坏?
通过上述的例子,我们发现少了一个比例问题。。。
- 使用 \(\frac{A{\cap}B}{A{\cup}B}\)交集除以并集
完全解决上诉问题
注意:这里还存在一个关于LOSS的问题,具体可参考GIOU
第二章 基础网络
注释:这里实现的是SSD300,并非SSD512.
2.1 基础网络
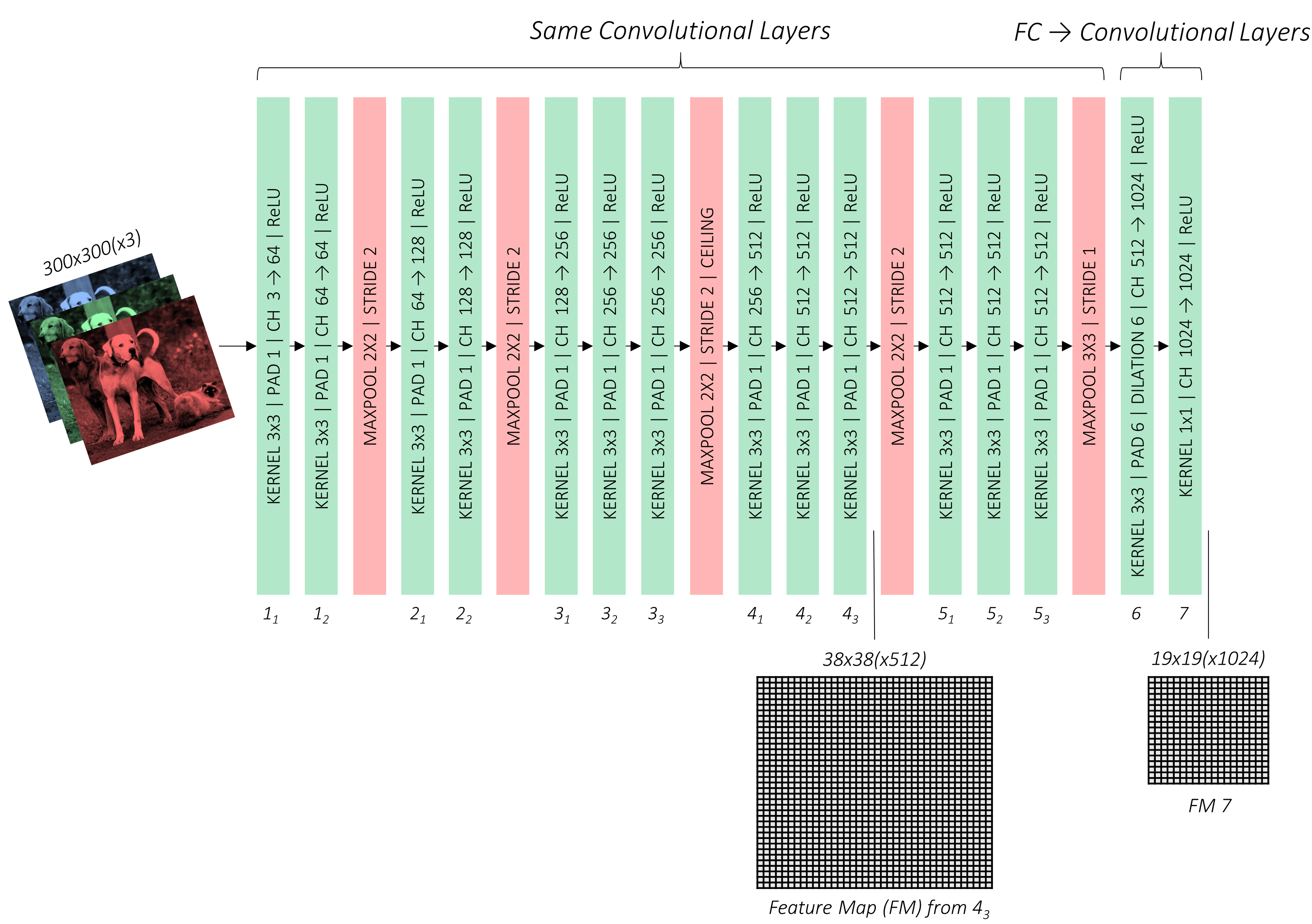
当前都是使用特征提取的基础架构,VGG、ResNet、DenseNet。。。等,原作者使用VGG-16架构作为基础网络。如下图2-1所示
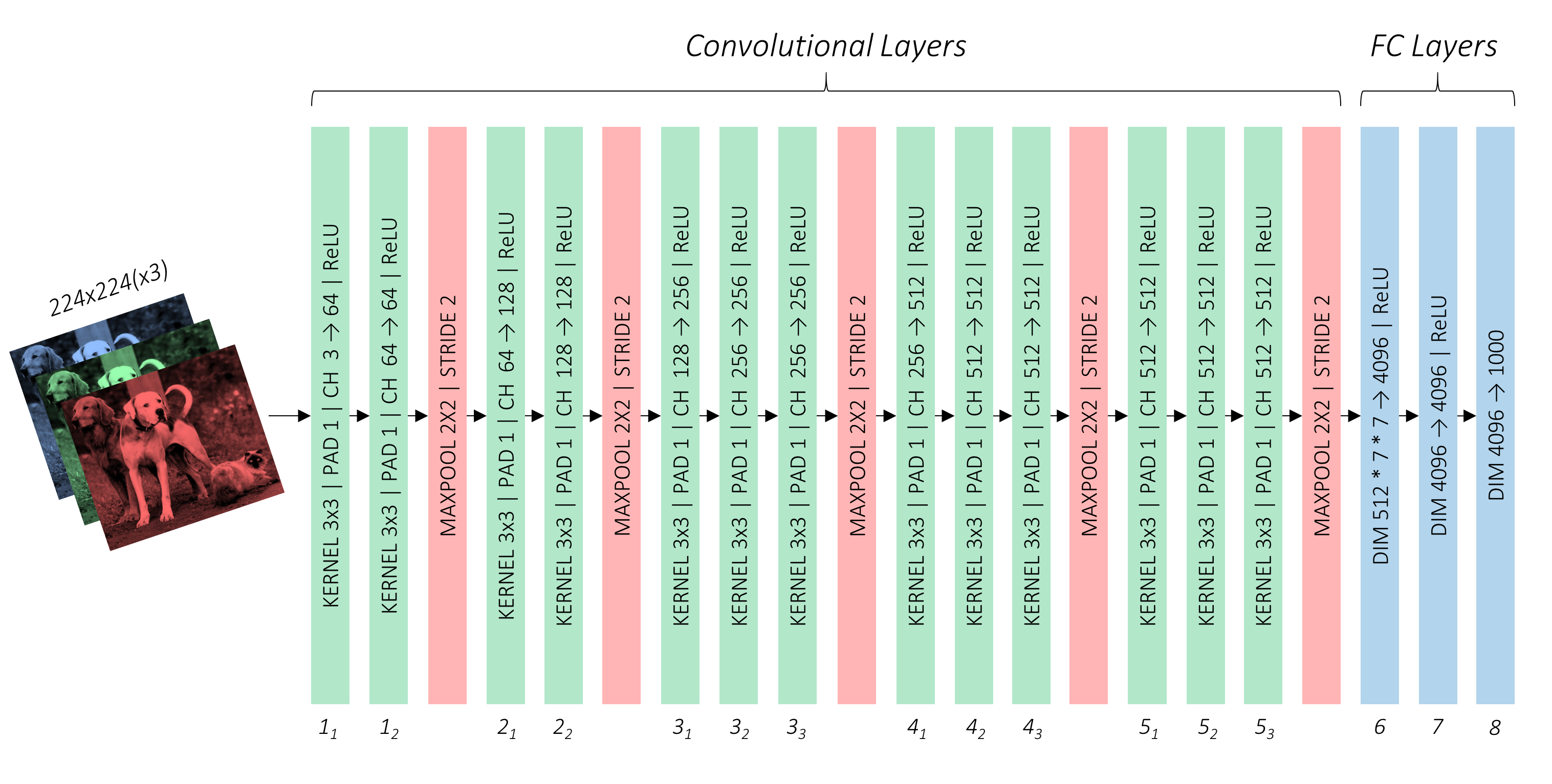
原始VGG-16是基于ImageNet训练的,参数优异。但是为了符合我们的设计,需要对基础网络做一定程度的修改。
- 原始输入300*300图像
- 对于池化后非整数feature map进行像上取整,比如con3_3==>>75*75,进行池化之后的*小为38 * 38,而不是37 * 37。
- 修改maxpooling_5==>>(size=3 * 3,stride=1),作用是不再将feature map的*小减半。
- 我们不需要全连接层,对 FC6 和 FC7 进行修改为conv6和conv7。直接去掉FC8
FC层修改为CONV层
说明:原作者对此进行了详细的描述,笔者这里默认*家有基础网络架构。
全连接和卷积的区别之处在于reshape!!!
也就是说卷积之后进行reshape(nuns,1)和全连接结果一样
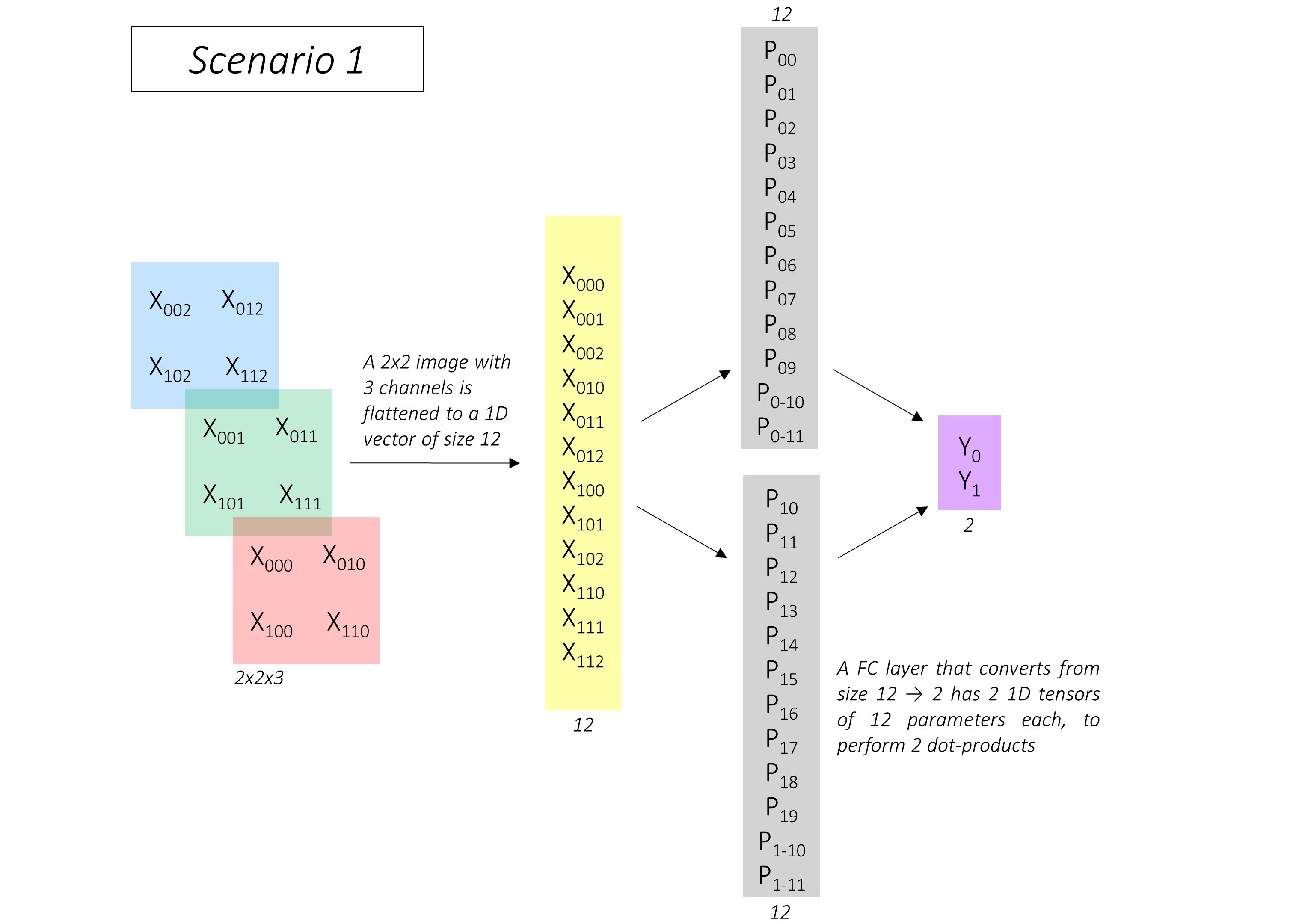
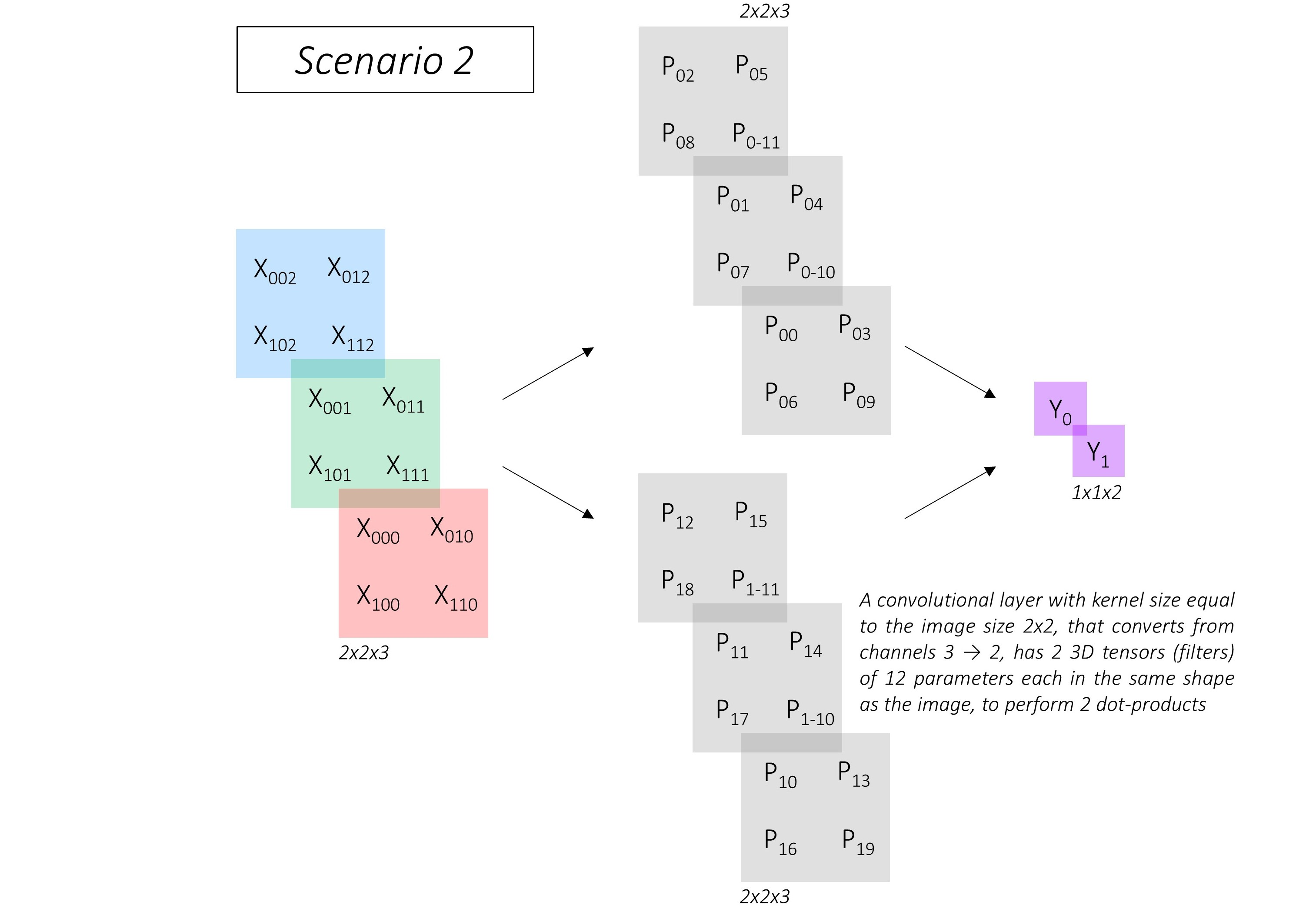
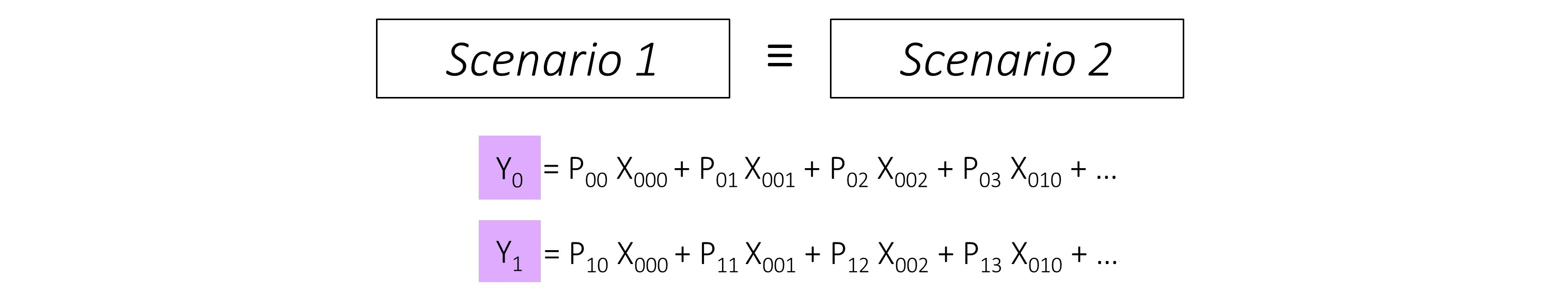

总结:
- *家不妨试一下,对VGG的最后全连接改为卷积,然后最后做一个reshape看看效果。
- 想一下效果一样的,CNN就是学*参数,与最后的形式无关
2.2 附加网络
我们当前已经学会如何从FC转换为CONV,以下对VGG-16进行转换。
VGG-16输入图像为224 * 224 * 3,那么conv5_3的输出也就是7 * 7 * 512。
- FC6的输入是7 * 7 * 512的一行向量,输出是4096 * 1的向量,那么参数数量为:4096 * 7 * 7 * 512,也就等于kernel=512 * 7 * 7 * 4046
- FC7的输入4096 * 1,输出为4096 * 1,也就等于kernel = 4096 * 1 * 1 * 4096
虽然转化到卷积了,但是channel太*了,512都挺*,别说4096了。。。
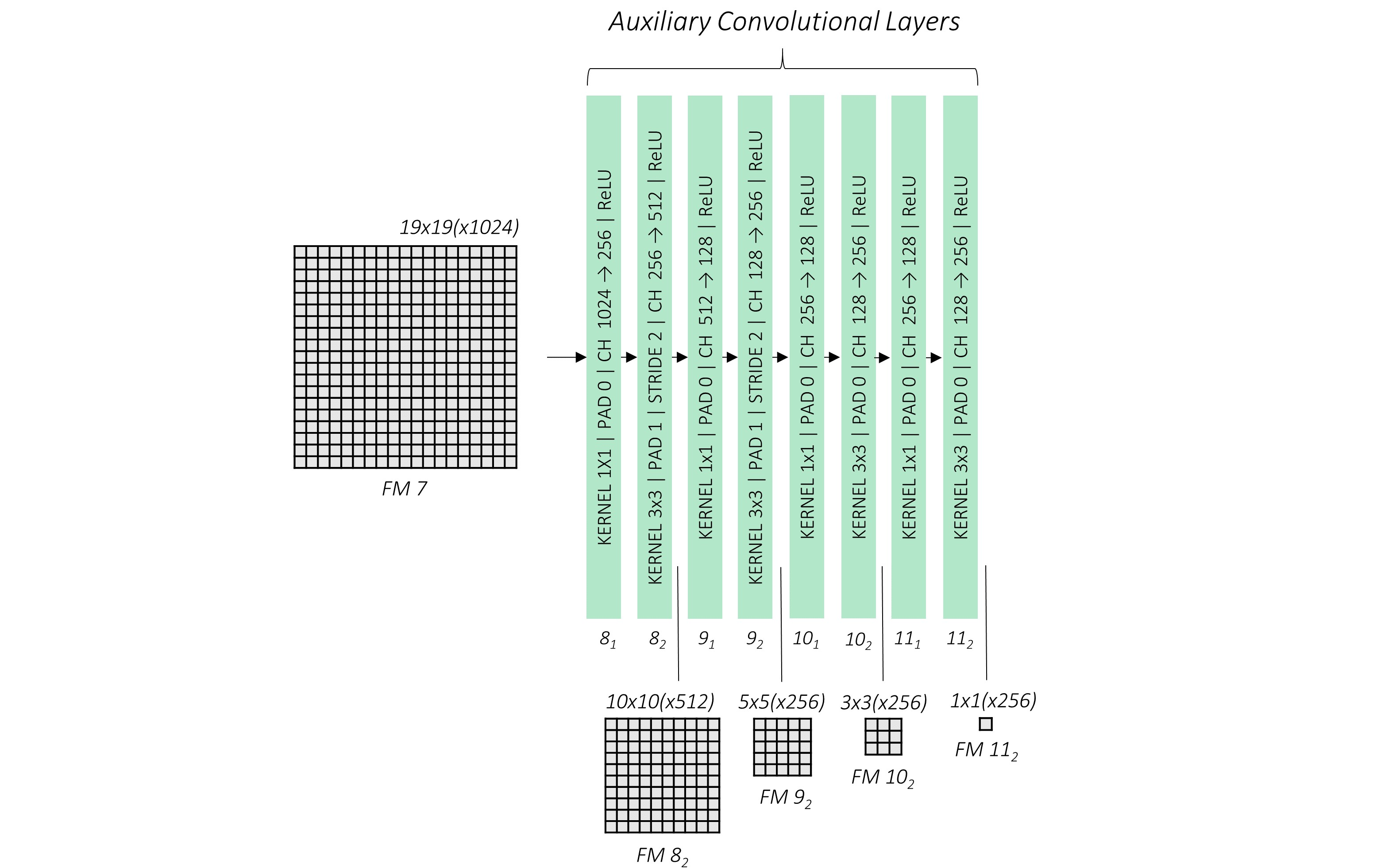
作者对其maxpooling和卷积进行了调整,如下图2-5所示
个人对其原因进行分析:
- 按照转换,Conv6的输入是7 * 7的feature,卷积也是7 * 7的*小。不符合常理,feature太小,卷积核太*。
- Conv7的channel=4096,那么深的通道完全没有必要(网络没*到那种地步)
- 考虑到后面金字塔采样(FPN),feature得有层次感
我们添加了额外的四个卷积块,feature map的变化是通过卷积的stride=2来实现的,并非maxpooling
注意是每隔一个stride=1之后接一个stride=2,这样做的感觉是过度一下
就像maxpooling不能紧接着来maxpooling一样
第三章 先验框设计
3.1 引言
在介绍先验框(prior box)的设计之前,我们先确认一下目的:检测出目标种类和位置
我们先从种类检测入手:
以VGG-16为例,输出是1000 * 1.代表1000个种类的预测
我们事先把标签(label)编码成one-hot形式,训练结果接一个softmax,loss就可以使用交叉熵返回梯度。
没毛病,完全可以
问题一:一个图像中有两个目标呢?
我们可以让输出为1000 * 2,其他情况类似直接为1000 * nums
问题二:如何知道输出对应哪个呢?
假设输入图像为5 * 5,我们就让输出为5 * 5 * 1000,这样就可以知道每个像素属于什么label
好像这是语义分割了。。。
我们再从位置入手:
我们之前定义了bounding box的形式, $ c_x, c_y, w, h $
跟着上面VGG-16的思路走,一个目标就输出4 * 1即可
问题三:同种类一样,存在多个目标呢?
类似种类,输出4 * 1 * nums即可
问题四:同种类一样,确定对应的种类?
假设输入图像为5 * 5,我们就让输出为5 * 5 * 2,注意这里没必要输出 \(c_x, c_y\) ,因为每个像素也就知道位置了
问题五:一个像素点多个目标问题?
这种情况很少很少,可以输出5 * 5 * nums * 2,nums是一个冗余,极少情况的冗余
这里就不上图了,自己想一下即可明白,而且后面会有SSD的分类说明!
3.2 先验框设计
在3.1节中,我们知道直接输出每个像素点的框W和H即可,为什么现在又来个先验框呢?
注意:这种方式是完全可行的,*家可以移步EAST和 AdvanceEAST
我们先来说直接输出W和H的缺点:
- 深度学*学到的东西是有能力限制的,而不是说什么都可以学到(理想情况可以),比如ResNet多加了一个原始数据(ResNet模块)就能更好的学*?
- 按理说RPN模块应该过时了,为什么现在还有很多人使用?比如SiamMask目标跟踪领域
- W和H的波动幅度都很*,直接去学*较为困难,我们能不能降低学*代价?
直接抛出一个话题,对比下图3-1两种学*目标,哪个更容易学*?
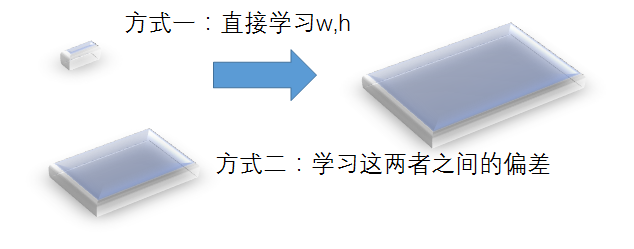
毋容置疑,肯定第二章方式更容易学*,具体如何设计,且看SSD*神作者的方案
以这里为出发点,我们称事先定义的bounding box为先验框
- 我们在
conv4_3,conv7,conv8_2,conv9_2,conv10_2,conv11_2.这些feature map上定义先验框 ,采用FPN(特征金字塔)进行多尺度检测的方案。 - 定义一个参数 \(s\) ,\(w * h = s^2\),先验框最*存在于Conv4_3上,设置为0.1,也就是图像的10%*小。
- 为了进一步降低学*成本,定义不同比例的先验框。1:1、1:2、2:1等,其中每一层额外加一个1:1的框,其他的框面积都是s,而这个额外的框\(s = \sqrt{s_k*s_{k+1}}\) ,这样做的目的是为了衔接上下两个feature
| Feature Map From | Feature Map Dimensions | Prior Scale | Aspect Ratios | Number of Priors per Position | Total Number of Priors on this Feature Map |
|---|---|---|---|---|---|
conv4_3 | 38, 38 | 0.1 | 1:1, 2:1, 1:2 + an extra prior | 4 | 5776 |
conv7 | 19, 19 | 0.2 | 1:1, 2:1, 1:2, 3:1, 1:3 + an extra prior | 6 | 2166 |
conv8_2 | 10, 10 | 0.375 | 1:1, 2:1, 1:2, 3:1, 1:3 + an extra prior | 6 | 600 |
conv9_2 | 5, 5 | 0.55 | 1:1, 2:1, 1:2, 3:1, 1:3 + an extra prior | 6 | 150 |
conv10_2 | 3, 3 | 0.725 | 1:1, 2:1, 1:2 + an extra prior | 4 | 36 |
conv11_2 | 1, 1 | 0.9 | 1:1, 2:1, 1:2 + an extra prior | 4 | 4 |
| Grand Total | – | – | – | – | 8732 priors |
3.3 先验框可视化
我们先看一下定义s之后的基本公式:
下面对conv9_2进行可视化:
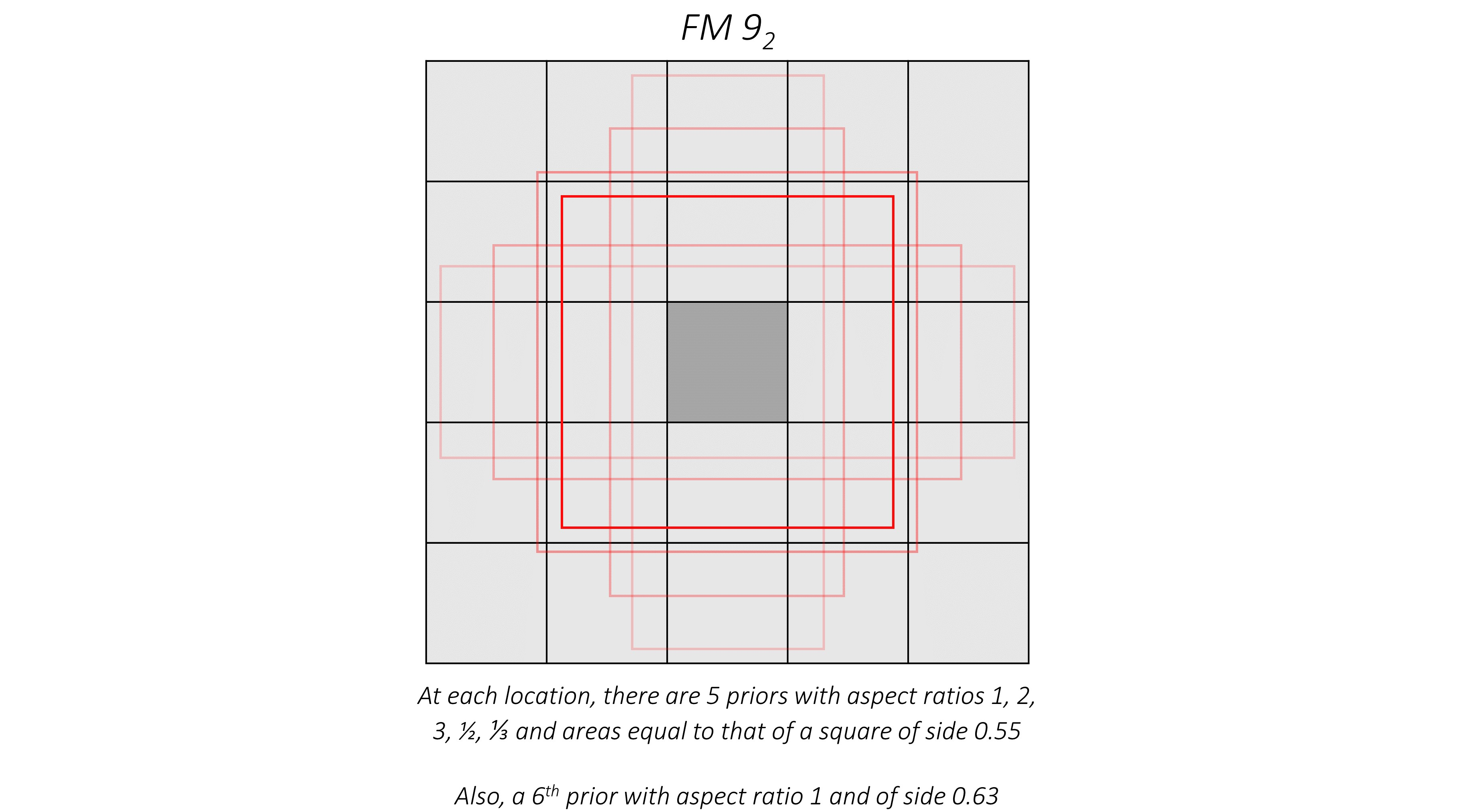

con9_2总共有6个框,五个框面积是0.55,一个框面积是0.63
注意:文章全部参数都是归一化之后的,请移步bounding box定义查看
*于边界直接裁断,其余feature map照部就搬即可,不再赘述
3.4 学*参数定义
在3.1节,我们对比了学*代价问题,具体的学*参数这节进行详细说明

观察上图3-3,是先验框和实际框之间的偏差图,具体我们学*哪些参数?
下面直接看作者的设计:

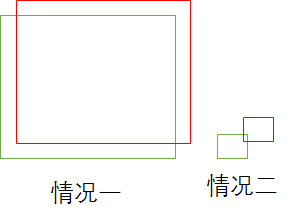
按照3.1节说的,为什么不直接定义成\(c_x - c_{x1}\) (帽子用x1代替),而作者定义了除以\(w_{x1}\)
因为较*的先验对应较小的偏差时,这个偏差很难学*,会导致*目标边界不准确。
下图3-5情况一和情况二哪个学*的更好?没有归一化,根本无法使用
第四章 网络输出定义
在3.1节中已经进行了初步说明,作者的思路也是按照这个进行的
种类的输出,这个多定义个背景(background)类,也就是nums = nums + 1,当然也可以没有背景类,那么负样本就无法进行学*,会**降低网络的鲁棒性!!!
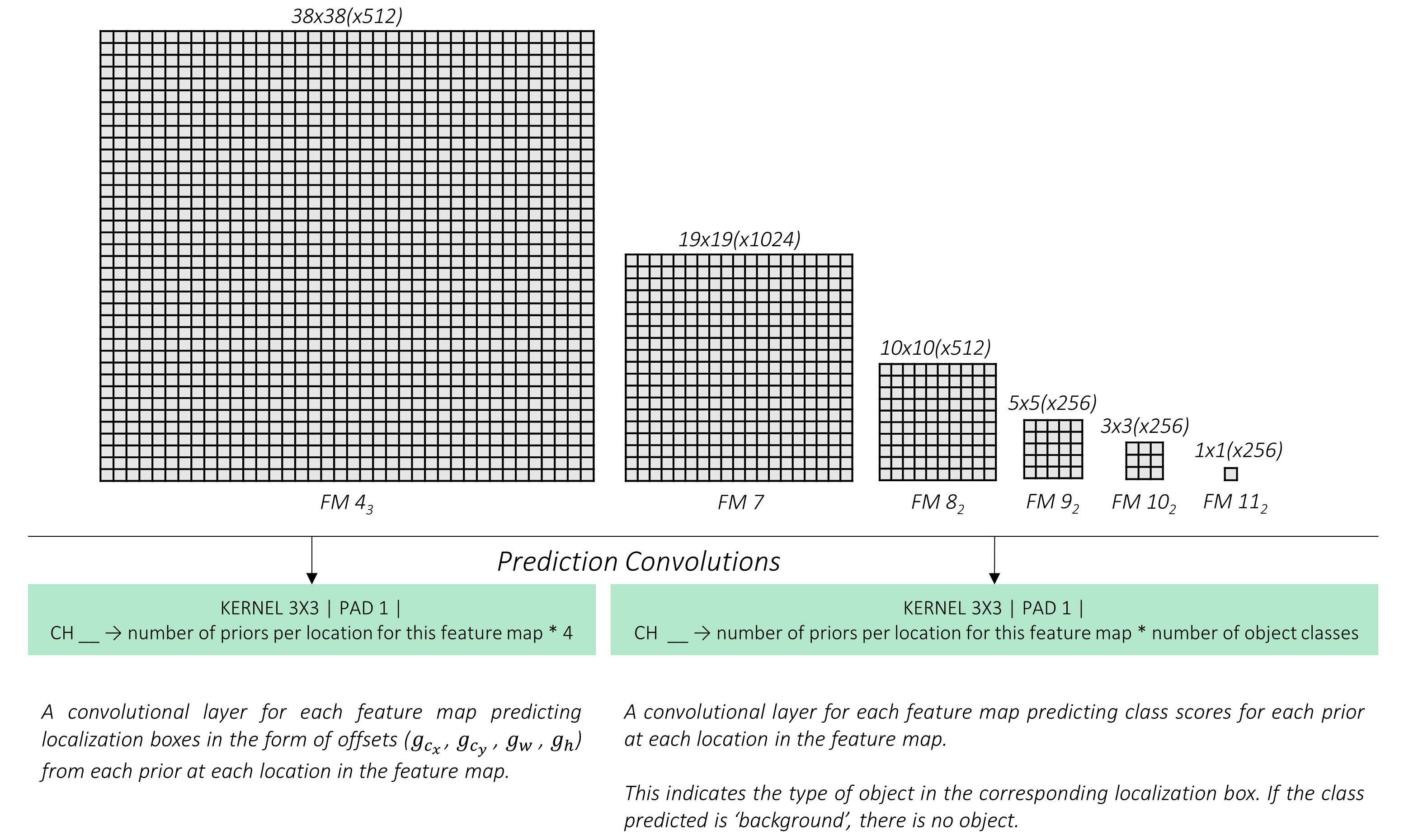
如上图4-1所示
- 位置输出:采用3 * 3的卷积输出4个通道(这里没考虑单个像素多个目标情况),对应之前的
(g_c_x, g_c_y, g_w, g_h) - 种类输出:采用3*3的卷积输出nums个通道(这里没考虑单个像素多个目标情况),对应之前VGG-16的输出。
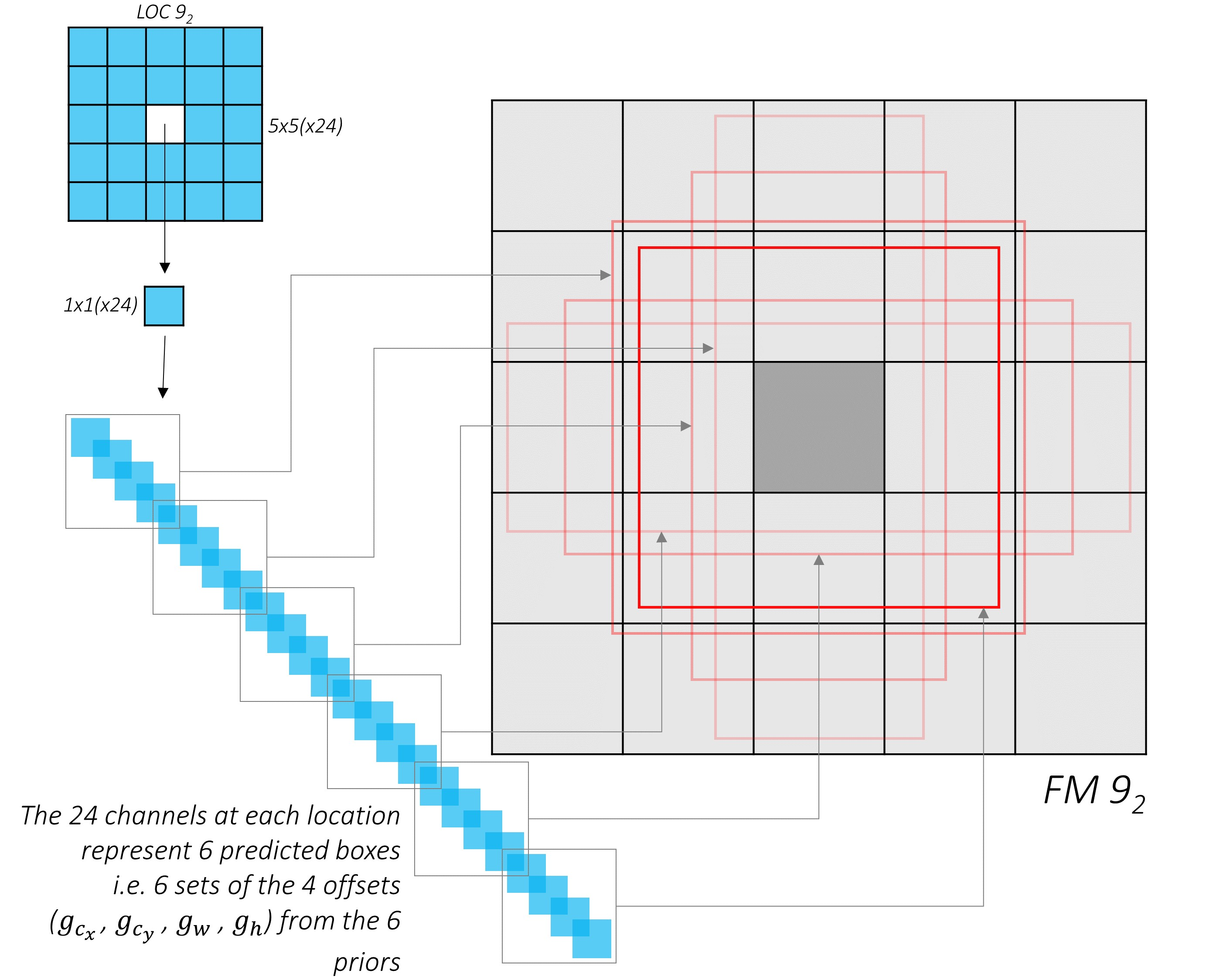
下面以具体的Con9_2为例,如下图4-2所示:
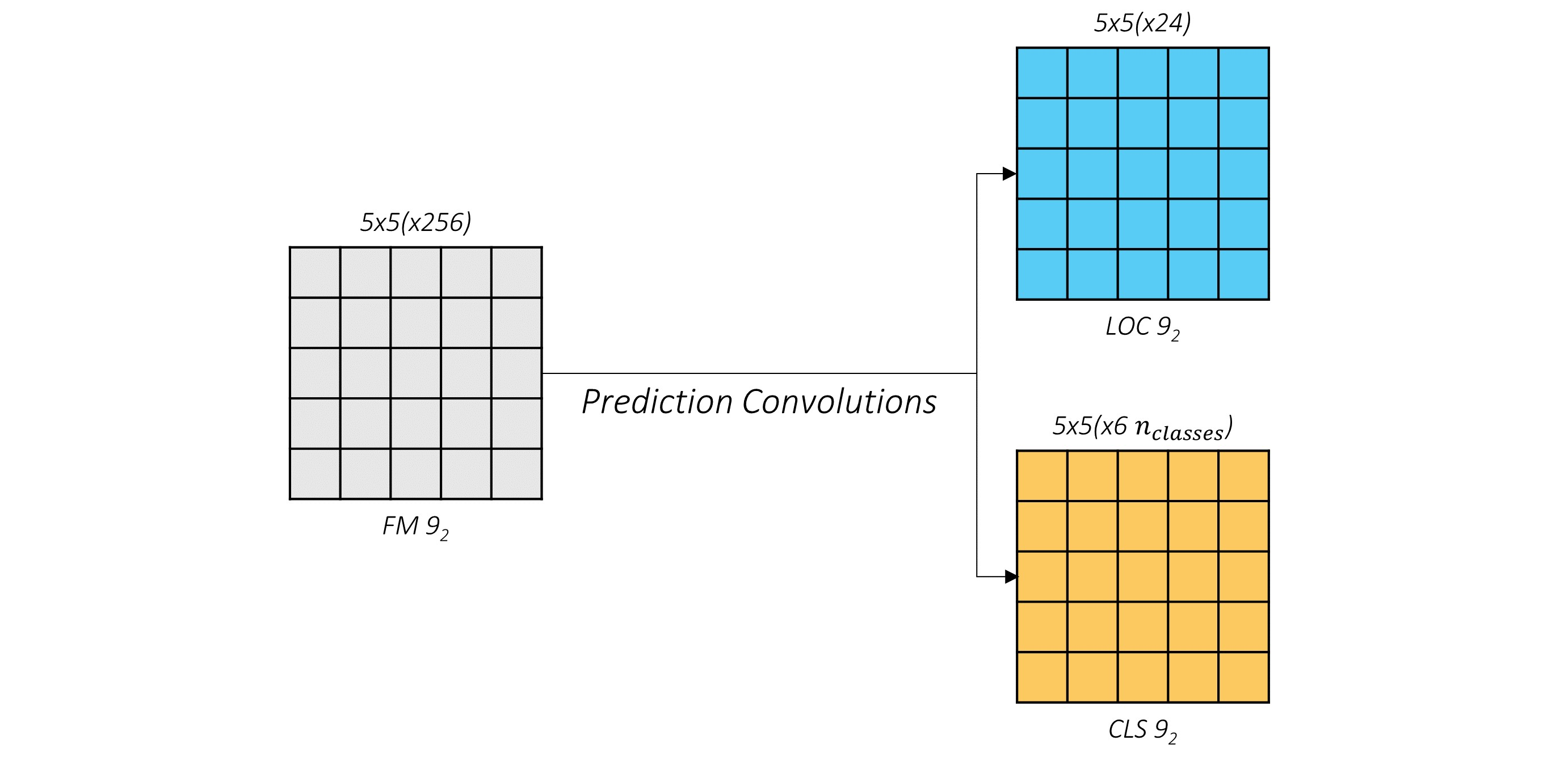
定位的24 = 4 * 6===>>4:输出参数,6:先验框的数量
种类的6*n_class===>>同上
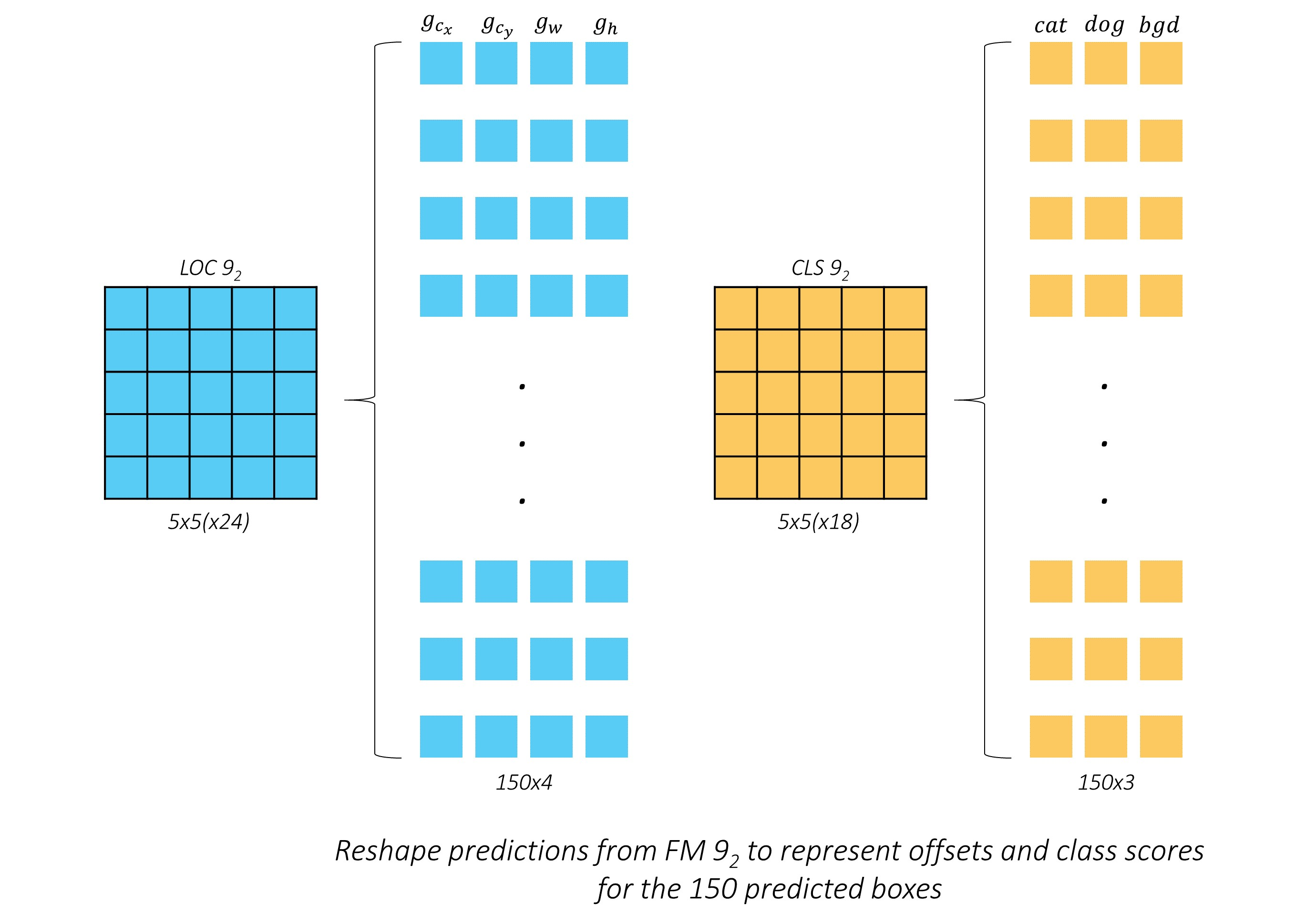
更为具体的如下图5-4所示:
作者还怕读者不懂,特意举了个例子,假设就两个种类:猫和狗,一个背景
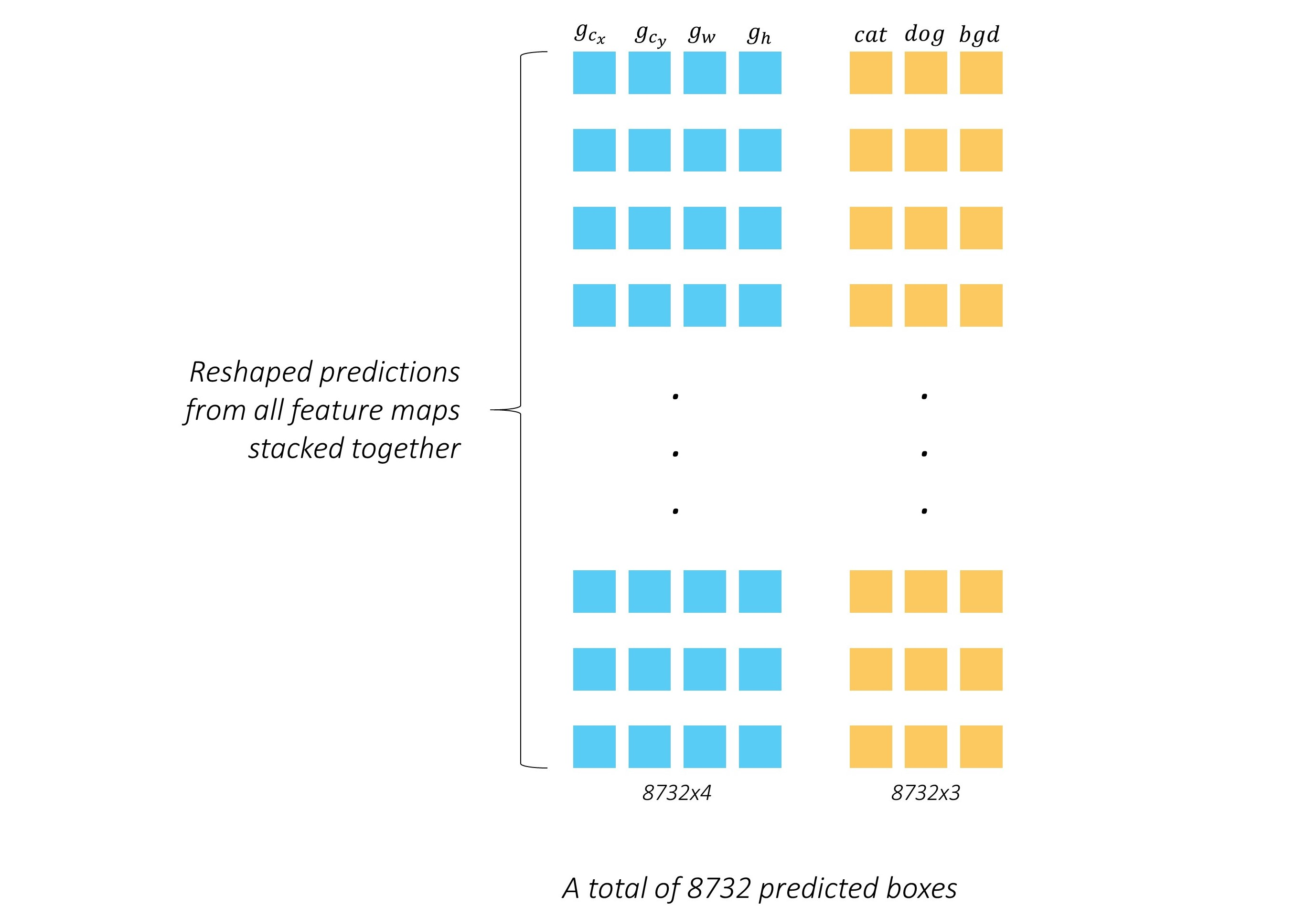
网络输出如下图5-5:
将位置和种类对应上,输出一个完整的矩阵,如下图5-6所示:
第五章 LOSS设计
5.1 目标框匹配
在计算LOSS之前,我们得先把框对应上(输出框和目标框的对应关系)
-
假设一张图有N个目标,那就需要找到N和8732(这是叠加了输出的偏差信息)个框的交集
-
为每个目标匹配一个最*交集的框
-
如果一个先验框与目标的交集小于0.5,那么就当这个先验框为负样本
-
如果一个先验框和目标的交集*于0.5,那么这个先验框为正样本,并且最*的交集为其匹配的种类
-
匹配的label都存在种类的标签
插曲: 有些人搞不懂正样本和负样本的概念
正样本:这个先验框匹配到目标框,并且用于计算位置和种类的LOSS,其中位置loss为了更好的框住目标,种类loss为了提高置信度。
负样本:这个先验框没有匹配到目标框,或者匹配到的目标框小于阈值(0.5等),并且位置不用计算loss(因为background没有框位置),种类需要计算loss,提高背景那一类的置信度。

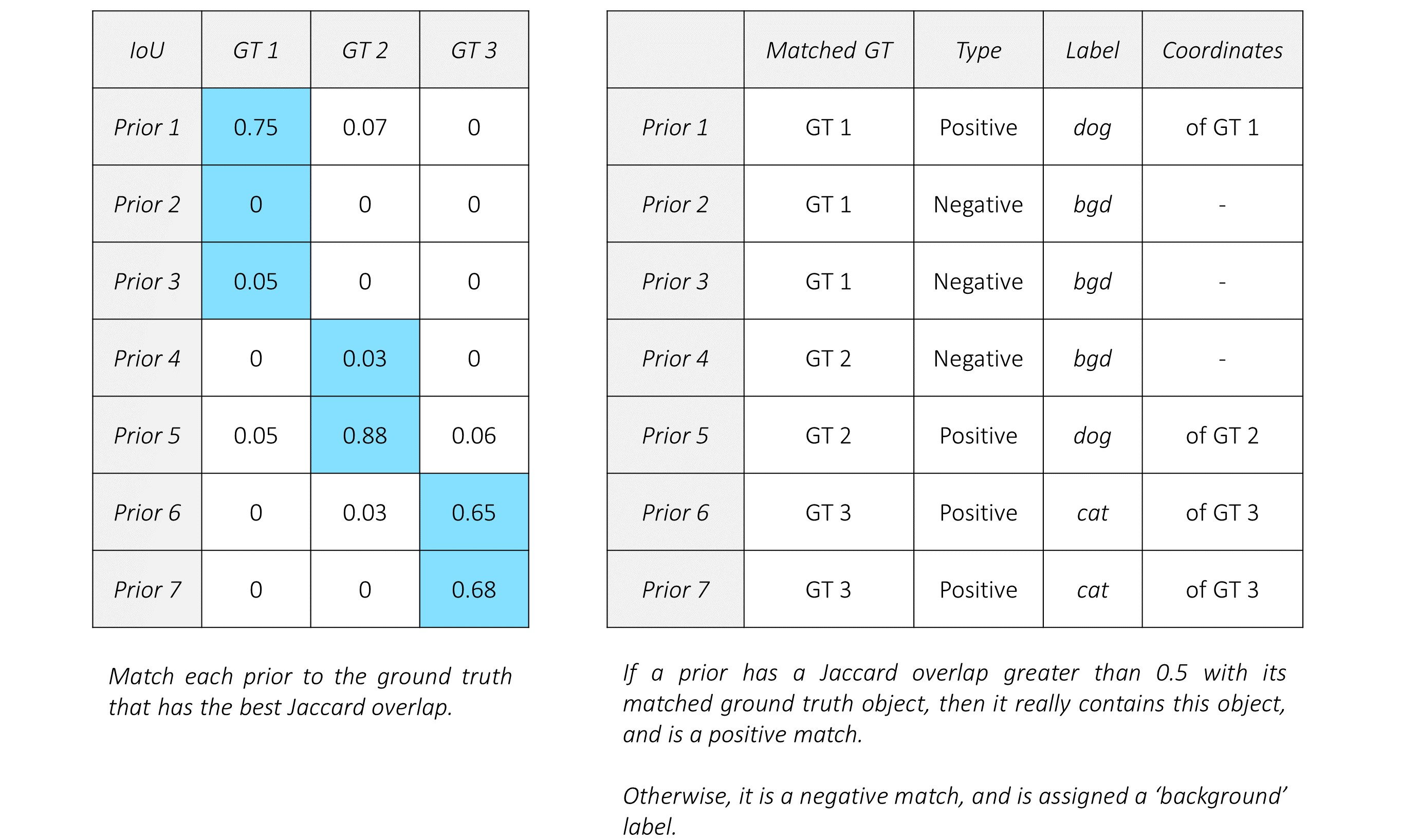
上图5-2和5-3给出了具体的例子,容易理解不在赘述。
5.2 LOSS计算
定位LOSS
定位的loss使用SmoothL1,没什么好说的

种类LOSS
现在遇到一个问题,我们直接使用交叉熵的LOSS的话,8732个框,基本百分之八十都是负样本,而负样本学*的结果是使当前的框种类置信度更高(背景)。
这样导致的结果就是类间不平衡情况,导致背景检测很准确,可能部分目标都会检测成背景
作者采用的解决方案是:舍弃简单的负样本,重点学*困难的负样本
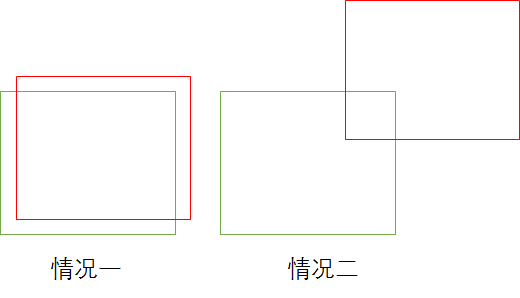
假设绿色为负样本框(实际背景不存在框),情况一相较于情况二更容易学*,那么我们舍弃情况一,使用情况二进行训练。
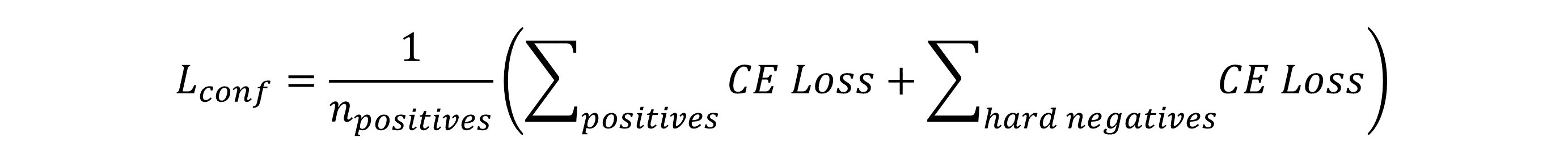
总的LOSS
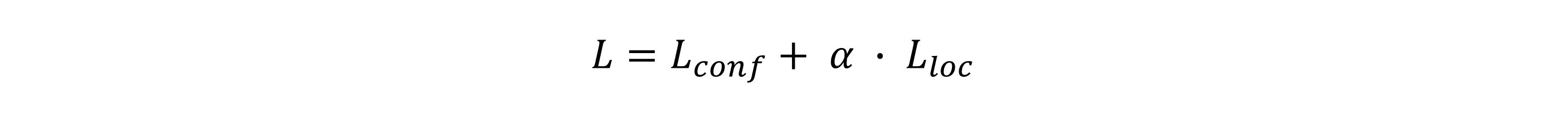
其中a也是一个可以作为学*的参数(笔者没试过),原文中a=1
第六章 非极*值抑制
这一章比较简单,直接看后面代码即可















 9178
9178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









