







https://www.bilibili.com/video/av43996494
高清原图
VGG修改图示意
图上信息讲解
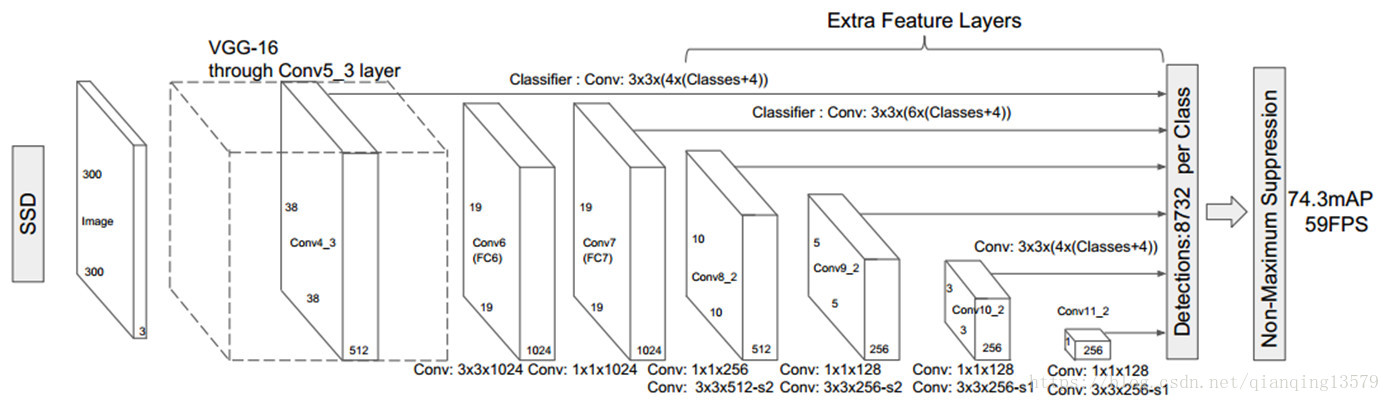


1 大体结构
vgg前5层保留,后面是三个全连接层
现在是VGG前5层,后面6-11是卷积层
VGG基础上加了+ conv6,conv7,conv8,conv9,conv10,conv11
提取特征的feature map是conv4 conv7 conv8 conv9 conv10 conv11
2 详细讲解第67层
输入是300*300 FC6 FC7换成了3*3的 conv6 conv7
并把pool5(s=2步长,池化核也是2)变成了 s=1 pool_size=3*3
第六层带孔卷积层,使用空洞卷积(扩张率是6)来进行视野扩张(类似膨胀)
使用带孔卷积的原因:为了不减少feature map size

移除dropout层,和FC8, 增加conv7 conv8 conv9 conv10 conv11 , 然后在检测数据集上面做fine-turning
SSD采集:提取特征的feature map是conv4 conv7 conv8 conv9 conv10 conv11 6个卷积层
因为conv4靠前, featuremap的norm很大,PS:会用一个l2的归一化进行处理
需要让conv4 通过12 nrom减少norm (仅对channel这个维度归一化),这时需要加一个可训练放缩量(gamma)
之后提取的feature map size是 (38,38)(19,19)(10,10)(5,5)(3,3)(1,1)

空洞卷积说明:
扩张率分别为1, 2, 3
?=?第三个存疑

锚点对应的正方形先验框说明:

3 tf相关代码解释
因为第四层比较靠前,进行l2归一化,只对channel这个维度归一化
4 7 8 9 10 11这几层提取的特征之后,进行两次卷积:
一次是得到类别,
一次得到锚点框的位置
不会用到配置函数 ,
def __init__(self):
pass了
PS:应该是构造函数吧
tf.layers.conv2d()
与tf.nn.conv2d()的区别
tf.layers.conv2d需要自己定义bias之类的
tf.nn.conv2d参数少了很多


tf.nn.conv2d
参考博客:https://blog.csdn.net/zuolixiangfisher/article/details/80528989
方法定义
tf.nn.conv2d (input, filter, strides, padding, use_cudnn_on_gpu=None, data_format=None, name=None)参数:
**input : ** 输入的要做卷积的图片,要求为一个张量,shape为 [ batch, in_height, in_weight, in_channel ],其中batch为图片的数量,in_height 为图片高度,in_weight 为图片宽度,in_channel 为图片的通道数,灰度图该值为1,彩色图为3。(也可以用其它值,但是具体含义不是很理解)
filter: 卷积核,要求也是一个张量,shape为 [ filter_height, filter_weight, in_channel, out_channels ],其中 filter_height 为卷积核高度,filter_weight 为卷积核宽度,in_channel 是图像通道数 ,和 input 的 in_channel 要保持一致,
out_channel 是卷积核数量。
strides: 卷积时在图像每一维的步长,这是一个一维的向量,[ 1, strides, strides, 1],第一位和最后一位固定必须是1
padding: string类型,值为“SAME” 和 “VALID”,表示的是卷积的形式,是否考虑边界。"SAME"是考虑边界,不足的时候用0去填充周围,"VALID"则不考虑
use_cudnn_on_gpu: bool类型,是否使用cudnn加速,默认为true
tf.layers.conv2d
参考博客:https://blog.csdn.net/gqixf/article/details/80519912
conv2d(inputs, filters, kernel_size, strides=(1, 1), padding='valid', data_format='channels_last', dilation_rate=(1, 1), activation=None, use_bias=True, kernel_initializer=None, bias_initializer=<tensorflow.python.ops.init_ops.Zeros object at 0x000002596A1FD898>, kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None, trainable=True, name=None, reuse=None)作用
2D 卷积层的函数接口 这个层创建了一个卷积核,将输入进行卷积来输出一个 tensor。如果
use_bias是True(且提供了bias_initializer),则一个偏差向量会被加到输出中。最后,如果activation不是None,激活函数也会被应用到输出中。参数
inputs:Tensor 输入
filters:整数,表示输出空间的维数(即卷积过滤器的数量)
kernel_size:一个整数,或者包含了两个整数的元组/队列,表示卷积窗的高和宽。如果是一个整数,则宽高相等。
strides:一个整数,或者包含了两个整数的元组/队列,表示卷积的纵向和横向的步长。如果是一个整数,则横纵步长相等。另外,strides不等于1 和dilation_rate不等于1 这两种情况不能同时存在。
padding:"valid"或者"same"(不区分大小写)。"valid"表示不够卷积核大小的块就丢弃,"same"表示不够卷积核大小的块就补0。"valid"的输出形状为"valid"的输出形状为其中, 为输入的 size(高或宽), 为 filter 的 size, 为 strides 的大小, 为向上取整。
data_format:channels_last或者channels_first,表示输入维度的排序。
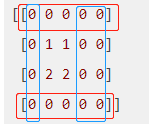
tf.pad()
参考博客: https://msd.misuland.com/pd/2884250171976192248
例子1:
第1个维度上,上下各补1行0
第2个维度上,上补1行0,下补2行0
例子2:
例子3:
a= [ [ [1, 1], [2, 2] ],
[ [3, 3], [4, 4] ] ]
padding
PS:我认为博客答案不对,因此在这里没有写



4 代码实现,以类的形式讲解
改错:(视频里作者写错了,我修正)
tf.Variable_scope这里应该是tf.variable_scope
存疑:# b7 conv7: 1x1x1024 =>第2个检测层
net = self.conv2d(net, filter=1024, k_size=[3, 3], scope='conv7') ???
# => 个数1024, 卷积核不是[1, 1]
运行出错:
下面代码直接运行会报错:
TypeError: conv2d() got an unexpected keyword argument 'input'
# 这里是本视频的所有代码
#!usr/bin/python
# -*- coding: utf-8 -*-
# Creation Date: 2019/7/10
import tensorflow as tf
import numpy as np
import cv2
class ssd(object):
def __init__(self):
pass # 先略过
# ===>l2正则化<===
def l2norm(self, x, scale, trainable=True, scope='L2Normalization'):
n_channels = x.get_shape().as_list()[-1] # 通道数. 得到形状,变成列表,取后一个
l2_norm = tf.nn.l2_normalize(x, dim=[3], epsilon=1e-12) # 只对每个像素点在channels上做归一化
with tf.variable_scope(scope):
gamma = tf.get_variable("gamma", shape=[n_channels, ], dtype=tf.float32,
initializer=tf.constant_initializer(scale),
trainable=trainable)
return l2_norm * gamma
# ===>下面开始定义所需组件<===
# conv2d, max_pool2d, pad2d, dropout
# 定义一个卷积的操作 1输入 2卷积核个数 3卷积核大小 4步长 5padding 6膨胀 7激活函数 8名字
def conv2d(self, x, filter, # 输入x, 卷积核的个数filter
k_size, stride=[1, 1], # k_size卷积核是几*几,步长stride
padding='same', dilation=[1, 1], # padding, 空洞卷积指数这里1代表正常卷积
activation=tf.nn.relu, scope='conv2d'): # 激活函数relu, 名字scope
return tf.layers.conv2d(input=x, filters=filter, kernel_size=k_size,
strides=stride, padding=padding, dilation_rate=dilation,
name=scope, activation=activation)
def max_pool2d(self, x, pool_size, stride, scope='max_pool2d'): # 我猜padding是vaild
return tf.layers.max_pooling2d(inputs=x, pool_size=pool_size, strides=stride, padding='valid', name=scope)
# 用于填充s=2的第8,9层. 从6层往后的卷积层需要自己填充, 不要用它自带的填充.
def pad2d(self, x, pad):
return tf.pad(x, paddings=[[0, 0], [pad, pad], [pad, pad], [0, 0]])
def dropout(self, x, d_rate=0.5):
return tf.layers.dropout(inputs=x, rate=d_rate)
# ===>下面开始写网络架构<===
def set_net(self):
check_points = {} # 装特征层的字典,用于循环迭代
x = tf.placeholder(dtype=tf.float32, shape=[None, 300, 300, 3])
with tf.variable_scope('ssd_300_vgg'):
# ===>VGG前5层<===
# b1
net = self.conv2d(x, filter=64, k_size=[3, 3], scope='conv1_1') # 64个3*3卷积核, s=1 默认,标准卷积
net = self.conv2d(net, 64, [3, 3], scope='conv1_2') # 64个3*3卷积核, s=1默认
net = self.max_pool2d(net, pool_size=[2, 2], stride=[2, 2]) # 池化层2*2卷积核, s=2 默认,池化层一般都是2
# b2
net = self.conv2d(net, filter=128, k_size=[3, 3], scope='conv2_1')
net = self.conv2d(net, 128, [3, 3], scope='conv2_2')
net = self.max_pool2d(net, pool_size=[2, 2], stride=[2, 2], scope='pool2')
# b3
net = self.conv2d(net, filter=256, k_size=[3, 3], scope='conv3_1')
net = self.conv2d(net, 256, [3, 3], scope='conv3_2')
net = self.conv2d(net, 256, [3, 3], scope='conv3_3')
net = self.max_pool2d(net, pool_size=[2, 2], stride=[2, 2], scope='pool3')
# b4 =>第1个检测层
net = self.conv2d(net, filter=512, k_size=[3, 3], scope='conv4_1')
net = self.conv2d(net, 512, [3, 3], scope='conv4_2')
net = self.conv2d(net, 512, [3, 3], scope='conv4_3')
check_points['block4'] = net
net = self.max_pool2d(net, pool_size=[2, 2], stride=[2, 2], scope='pool4')
# b5 关键部分来了,这里与vgg不同了
net = self.conv2d(net, filter=512, k_size=[3, 3], scope='conv5_1')
net = self.conv2d(net, 512, [3, 3], scope='conv5_2')
net = self.conv2d(net, 512, [3, 3], scope='conv5_3')
net = self.max_pool2d(net, pool_size=[3, 3], stride=[1, 1], scope='pool5') # =>池化层3*3核, 步长变成1*1
# ===>卷积层,代替VGG全连接层<===
# b6 conv6: 3x3x1024-d6
net = self.conv2d(net, filter=1024, k_size=[3, 3], dilation=[6, 6], scope='conv6')
# => 个数1024, dilation=[6, 6]
# b7 conv7: 1x1x1024 =>第2个检测层
net = self.conv2d(net, filter=1024, k_size=[3, 3], scope='conv7')
# => 个数1024, 卷积核不是[1, 1] ?=?
check_points['block7'] = net
# b8 conv8_1: 1x1x256; conv8_2: 3x3x512-s2-vaild =>第3个检测层
net = self.conv2d(net, 256, [1, 1], scope='conv8_1x1') # =>个数256,卷积核1x1
net = self.conv2d(self.pad2d(net, 1), 512, [3, 3], [2, 2], scope='conv8_3x3', padding='valid')
# =>个数512, 卷积核3x3, 步长2, 'valid'
check_points['block8'] = net
# b9 conv9_1: 1x1x128 conv8_2: 3x3x256-s2-vaild =>第4个检测层
net = self.conv2d(net, 128, [1, 1], scope='conv9_1x1') # =>个数128,卷积核1x1
net = self.conv2d(self.pad2d(net, 1), 256, [3, 3], [2, 2], scope='conv9_3x3', padding='valid')
# =>个数256,卷积核3x3,步长2x2, valid
check_points['block9'] = net
# b10 conv10_1: 1x1x128 conv10_2: 3x3x256-s1-valid =>第5个检测层
net = self.conv2d(net, 128, [1, 1], scope='conv10_1x1') # =>个数128,卷积核1x1
net = self.conv2d(net, 256, [3, 3], scope='conv10_3x3', padding='valid')
# =>个数256,valid
check_points['block10'] = net
# b11 conv11_1: 1x1x128 conv11_2: 3x3x256-s1-valid =>第6检测层
net = self.conv2d(net, 128, [1, 1], scope='conv11_1x1') # =>个数128,卷积核1x1
net = self.conv2d(net, 256, [3, 3], scope='conv11_3x3', padding='valid')
# =>个数256, valid
check_points['block11'] = net
print(check_points)
if __name__ == '__main__':
sd = ssd()
sd.set_net()
最后两次卷积,
一次卷积得到类别,
一次卷积得到锚点框的位置xywh
注意:因为要加载权重, 名字是不能修改的: conv1_1等,其他的可以修改
5 网上下载的作者源代码
import tensorflow as tf
import numpy as np
import cv2
class ssd(object):
def __init__(self):
self.feature_map_size = [[38, 38], [19, 19], [10, 10], [5, 5], [3, 3], [1, 1]]
self.classes = ["aeroplane", "bicycle", "bird", "boat", "bottle",
"bus", "car", "cat", "chair", "cow", "diningtable",
"dog", "horse", "motorbike", "person", "pottedplant",
"sheep", "sofa", "train", "tvmonitor"]
self.feature_layers = ['block4', 'block7', 'block8', 'block9', 'block10', 'block11']
self.img_size = (300,300)
self.num_classes = 21
self.boxes_len = [4,6,6,6,4,4]
self.isL2norm = [True,False,False,False,False,False]
self.anchor_sizes = [[21., 45.], [45., 99.], [99., 153.],[153., 207.],[207., 261.], [261., 315.]]
self.anchor_ratios = [[2, .5], [2, .5, 3, 1. / 3], [2, .5, 3, 1. / 3],
[2, .5, 3, 1. / 3], [2, .5], [2, .5]]
self.anchor_steps = [8, 16, 32, 64, 100, 300]
self.prior_scaling = [0.1, 0.1, 0.2, 0.2] #特征图先验框缩放比例
self.n_boxes = [5776,2166,600,150,36,4] #8732个
self.threshold = 0.2
########### ssd网络架构部分
def l2norm(self,x, trainable=True, scope='L2Normalization'):
n_channels = x.get_shape().as_list()[-1] # 通道数
l2_norm = tf.nn.l2_normalize(x, dim=[3], epsilon=1e-12) # 只对每个像素点在channels上做归一化
with tf.variable_scope(scope):
gamma = tf.get_variable("gamma", shape=[n_channels, ], dtype=tf.float32,
trainable=trainable)
return l2_norm * gamma
def conv2d(self,x,filter,k_size,stride=[1,1],padding='same',dilation=[1,1],activation=tf.nn.relu,scope='conv2d'):
return tf.layers.conv2d(inputs=x, filters=filter, kernel_size=k_size,
strides=stride, dilation_rate=dilation, padding=padding,
name=scope, activation=activation)
def max_pool2d(self,x, pool_size, stride, scope='max_pool2d'):
return tf.layers.max_pooling2d(inputs=x, pool_size=pool_size, strides=stride, name=scope, padding='same')
def pad2d(self,x, pad):
return tf.pad(x, paddings=[[0, 0], [pad, pad], [pad, pad], [0, 0]])
def dropout(self,x, d_rate=0.5):
return tf.layers.dropout(inputs=x, rate=d_rate)
def ssd_prediction(self, x, num_classes, box_num, isL2norm, scope='multibox'):
reshape = [-1] + x.get_shape().as_list()[1:-1] # 去除第一个和最后一个得到shape
with tf.variable_scope(scope):
if isL2norm:
x = self.l2norm(x)
print(x)
# #预测位置 --》 坐标和大小 回归
location_pred = self.conv2d(x, filter=box_num * 4, k_size=[3,3], activation=None,scope='conv_loc')
location_pred = tf.reshape(location_pred, reshape + [box_num, 4])
# 预测类别 --> 分类 sofrmax
class_pred = self.conv2d(x, filter=box_num * num_classes, k_size=[3,3], activation=None, scope='conv_cls')
class_pred = tf.reshape(class_pred, reshape + [box_num, num_classes])
print(location_pred, class_pred)
return location_pred, class_pred
def set_net(self):
check_points = {}
predictions = []
locations = []
x = tf.placeholder(dtype=tf.float32,shape=[None,300,300,3])
with tf.variable_scope('ssd_300_vgg'):
#b1
net = self.conv2d(x,filter=64,k_size=[3,3],scope='conv1_1')
net = self.conv2d(net,64,[3,3],scope='conv1_2')
net = self.max_pool2d(net,pool_size=[2,2],stride=[2,2],scope='pool1')
#b2
net = self.conv2d(net, filter=128, k_size=[3, 3], scope='conv2_1')
net = self.conv2d(net, 128, [3, 3], scope='conv2_2')
net = self.max_pool2d(net, pool_size=[2, 2], stride=[2, 2], scope='pool2')
#b3
net = self.conv2d(net, filter=256, k_size=[3, 3], scope='conv3_1')
net = self.conv2d(net, 256, [3, 3], scope='conv3_2')
net = self.conv2d(net, 256, [3, 3], scope='conv3_3')
net = self.max_pool2d(net, pool_size=[2, 2], stride=[2, 2], scope='pool3')
#b4
net = self.conv2d(net, filter=512, k_size=[3, 3], scope='conv4_1')
net = self.conv2d(net, 512, [3, 3], scope='conv4_2')
net = self.conv2d(net, 512, [3, 3], scope='conv4_3')
check_points['block4'] = net
net = self.max_pool2d(net, pool_size=[2, 2], stride=[2, 2], scope='pool4')
#b5
net = self.conv2d(net, filter=512, k_size=[3, 3], scope='conv5_1')
net = self.conv2d(net, 512, [3, 3], scope='conv5_2')
net = self.conv2d(net, 512, [3, 3], scope='conv5_3')
net = self.max_pool2d(net, pool_size=[3, 3], stride=[1, 1], scope='pool4')
#b6
net = self.conv2d(net,1024,[3,3],dilation=[6,6],scope='conv6')
#b7
net = self.conv2d(net,1024,[1,1],scope='conv7')
check_points['block7'] = net
#b8
net = self.conv2d(net,256,[1,1],scope='conv8_1x1')
net = self.conv2d(self.pad2d(net,1),512,[3,3],[2,2],scope='conv8_3x3',padding='valid')
check_points['block8'] = net
#b9
net = self.conv2d(net, 128, [1, 1], scope='conv9_1x1')
net = self.conv2d(self.pad2d(net,1), 256, [3, 3], [2, 2], scope='conv9_3x3', padding='valid')
check_points['block9'] = net
#b10
net = self.conv2d(net, 128, [1, 1], scope='conv10_1x1')
net = self.conv2d(net, 256, [3, 3], scope='conv10_3x3', padding='valid')
check_points['block10'] = net
#b11
net = self.conv2d(net, 128, [1, 1], scope='conv11_1x1')
net = self.conv2d(net, 256, [3, 3], scope='conv11_3x3', padding='valid')
check_points['block11'] = net
for i,j in enumerate(self.feature_layers):
loc,cls = self.ssd_prediction(
x = check_points[j],
num_classes = self.num_classes,
box_num = self.boxes_len[i],
isL2norm = self.isL2norm[i],
scope = j + '_box'
)
predictions.append(tf.nn.softmax(cls))
locations.append(loc)
return locations,predictions,x
########### ssd网络架构部分结束
########## 先验框部分开始
#先验框生成
def ssd_anchor_layer(self,img_size,feature_map_size,anchor_size,anchor_ratio,anchor_step,box_num,offset=0.5):
y,x = np.mgrid[0:feature_map_size[0],0:feature_map_size[1]]
y = (y.astype(np.float32) + offset) * anchor_step /img_size[0]
x = (x.astype(np.float32) + offset) * anchor_step /img_size[1]
y = np.expand_dims(y,axis=-1)
x = np.expand_dims(x,axis=-1)
#计算两个长宽比为1的h、w
h = np.zeros((box_num,),np.float32)
w = np.zeros((box_num,),np.float32)
h[0] = anchor_size[0] /img_size[0]
w[0] = anchor_size[0] /img_size[0]
h[1] = (anchor_size[0] * anchor_size[1]) ** 0.5 / img_size[0]
w[1] = (anchor_size[0] * anchor_size[1]) ** 0.5 / img_size[1]
for i,j in enumerate(anchor_ratio):
h[i + 2] = anchor_size[0] / img_size[0] / (j ** 0.5)
w[i + 2] = anchor_size[0] / img_size[1] * (j ** 0.5)
return y,x,h,w
#解码网络
def ssd_decode(self,location,box,prior_scaling):
y_a, x_a, h_a, w_a = box
cx = location[:, :, :, :, 0] * w_a * prior_scaling[0] + x_a #########################
cy = location[:, :, :, :, 1] * h_a * prior_scaling[1] + y_a
w = w_a * tf.exp(location[:, :, :, :, 2] * prior_scaling[2])
h = h_a * tf.exp(location[:, :, :, :, 3] * prior_scaling[3])
print(cx, cy, w, h)
bboxes = tf.stack([cy - h / 2.0, cx - w / 2.0, cy + h / 2.0, cx + w / 2.0], axis=-1)
return bboxes
#先验框筛选
def choose_anchor_boxes(self, predictions, anchor_box, n_box):
anchor_box = tf.reshape(anchor_box, [n_box, 4])
prediction = tf.reshape(predictions, [n_box, 21])
prediction = prediction[:, 1:]
classes = tf.argmax(prediction, axis=1) + 1
scores = tf.reduce_max(prediction, axis=1)
filter_mask = scores > self.threshold
classes = tf.boolean_mask(classes, filter_mask)
scores = tf.boolean_mask(scores, filter_mask)
anchor_box = tf.boolean_mask(anchor_box, filter_mask)
return classes, scores, anchor_box
########## 先验框部分结束
######### 训练部分开始
def bboxes_sort(self,classes, scores, bboxes, top_k=400):
idxes = np.argsort(-scores)
classes = classes[idxes][:top_k]
scores = scores[idxes][:top_k]
bboxes = bboxes[idxes][:top_k]
return classes, scores, bboxes
# 计算IOU
def bboxes_iou(self,bboxes1, bboxes2):
bboxes1 = np.transpose(bboxes1)
bboxes2 = np.transpose(bboxes2)
# 计算两个box的交集:交集左上角的点取两个box的max,交集右下角的点取两个box的min
int_ymin = np.maximum(bboxes1[0], bboxes2[0])
int_xmin = np.maximum(bboxes1[1], bboxes2[1])
int_ymax = np.minimum(bboxes1[2], bboxes2[2])
int_xmax = np.minimum(bboxes1[3], bboxes2[3])
# 计算两个box交集的wh:如果两个box没有交集,那么wh为0(按照计算方式wh为负数,跟0比较取最大值)
int_h = np.maximum(int_ymax - int_ymin, 0.)
int_w = np.maximum(int_xmax - int_xmin, 0.)
# 计算IOU
int_vol = int_h * int_w # 交集面积
vol1 = (bboxes1[2] - bboxes1[0]) * (bboxes1[3] - bboxes1[1]) # bboxes1面积
vol2 = (bboxes2[2] - bboxes2[0]) * (bboxes2[3] - bboxes2[1]) # bboxes2面积
iou = int_vol / (vol1 + vol2 - int_vol) # IOU=交集/并集
return iou
# NMS
def bboxes_nms(self,classes, scores, bboxes, nms_threshold=0.5):
keep_bboxes = np.ones(scores.shape, dtype=np.bool)
for i in range(scores.size - 1):
if keep_bboxes[i]:
overlap = self.bboxes_iou(bboxes[i], bboxes[(i + 1):])
keep_overlap = np.logical_or(overlap < nms_threshold, classes[(i + 1):] != classes[i])
keep_bboxes[(i + 1):] = np.logical_and(keep_bboxes[(i + 1):], keep_overlap)
idxes = np.where(keep_bboxes)
return classes[idxes], scores[idxes], bboxes[idxes]
######## 训练部分结束
def handle_img(self,img_path):
means = np.array((123., 117., 104.))
self.img = cv2.imread(img_path)
img = np.expand_dims(cv2.resize(cv2.cvtColor(self.img, cv2.COLOR_BGR2RGB) - means,self.img_size),axis=0)
return img
def draw_rectangle(self,img, classes, scores, bboxes, colors, thickness=2):
shape = img.shape
for i in range(bboxes.shape[0]):
bbox = bboxes[i]
# color = colors[classes[i]]
p1 = (int(bbox[0] * shape[0]), int(bbox[1] * shape[1]))
p2 = (int(bbox[2] * shape[0]), int(bbox[3] * shape[1]))
cv2.rectangle(img, p1[::-1], p2[::-1], colors[0], thickness)
# Draw text...
s = '%s/%.3f' % (self.classes[classes[i] - 1], scores[i])
p1 = (p1[0] - 5, p1[1])
cv2.putText(img, s, p1[::-1], cv2.FONT_HERSHEY_DUPLEX, 0.5, colors[1], 1)
cv2.namedWindow("img", 0);
cv2.resizeWindow("img", 640, 480);
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
def run_this(self,locations,predictions):
layers_anchors = []
classes_list = []
scores_list = []
bboxes_list = []
for i, s in enumerate(self.feature_map_size):
anchor_bboxes = self.ssd_anchor_layer(self.img_size, s,
self.anchor_sizes[i],
self.anchor_ratios[i],
self.anchor_steps[i],
self.boxes_len[i])
layers_anchors.append(anchor_bboxes)
for i in range(len(predictions)):
d_box = self.ssd_decode(locations[i], layers_anchors[i], self.prior_scaling)
cls, sco, box = self.choose_anchor_boxes(predictions[i], d_box, self.n_boxes[i])
classes_list.append(cls)
scores_list.append(sco)
bboxes_list.append(box)
classes = tf.concat(classes_list, axis=0)
scores = tf.concat(scores_list, axis=0)
bboxes = tf.concat(bboxes_list, axis=0)
return classes,scores,bboxes
'''
只要修改
img = sd.handle_img('tetst.jpg') 这一行代码就好啦,把你想预测的图片放进去
'''
if __name__ == '__main__':
sd = ssd()
locations, predictions, x = sd.set_net()
classes, scores, bboxes = sd.run_this(locations, predictions)
sess = tf.Session()
ckpt_filename = 'ssd_vgg_300_weights.ckpt'
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver()
saver.restore(sess, ckpt_filename)
img = sd.handle_img('tetst.jpg')
rclasses, rscores, rbboxes = sess.run([classes, scores, bboxes], feed_dict={x: img})
rclasses, rscores, rbboxes = sd.bboxes_sort(rclasses, rscores, rbboxes)
rclasses, rscores, rbboxes = sd.bboxes_nms(rclasses, rscores, rbboxes)
sd.draw_rectangle(sd.img,rclasses,rscores,rbboxes,[[0,0,255],[255,0,0]])

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











