







 本文介绍了K-means算法,这是一种常用的聚类方法,通过最小化每个点与最近聚簇中心的欧几里得距离平方和来划分数据。算法包括初始化聚簇中心、分配数据、重新计算聚簇中心等步骤。文中还提供了测试代码,并展示了高斯分布数据的分类结果。
本文介绍了K-means算法,这是一种常用的聚类方法,通过最小化每个点与最近聚簇中心的欧几里得距离平方和来划分数据。算法包括初始化聚簇中心、分配数据、重新计算聚簇中心等步骤。文中还提供了测试代码,并展示了高斯分布数据的分类结果。
一、什么是K-means
k-means 是一种被广泛使用的直接聚类算法,给定一个对象的集合,把这些对象划分为多个组,使得组内之间比较相似而不同的组之间差异较大。
二、K-Means 算法思想
K-Means 算法的输入对象是d维向量空间中的一些点,算法将集合D分为k个聚簇,集合D中的每个点属于且仅属于k个聚簇中的一个。K-Means算法默认的紧密度度量标准是欧几里得距离,算法的实质是最小化一个如下的非负代价函数:即最小化每个点和它距离最近的聚簇代表之间饿欧式距离平方和。
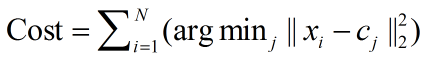
算法过程:
: 1:用集合D中的K个数据作为初始的聚簇代表,(可以随机选取)
2:分数据,将每个点分配到当前与之最近的那个聚簇中心,同时打破上次迭代确定的归属关系。
3:重定均值,重新确定每一个聚簇代表,计算所有分配给改聚簇代表的数据的中心。
4:重复步骤2、3,当C={cj|j=1,2,3...,k} 不再变化 或者目标函数收敛 的时候算法停止。
三、代码:
package dataMining;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/**
* @author 作者 : xcy
* @version 创建时间:2016年11月16日 下午7:11:53
* 类说明
*/
public class Kmeans {
private int k;
private double[][] data;
private double threshold;
private double[][] center;
private int[] cate;
public Kmeans(String path, int k, double threshold) throws IOException {
// data;
BufferedReader bfr = new BufferedReader(new FileReader(path));
List<String> tmp = new ArrayList<String>();
String s = "";
while ((s = bfr.readLine()) != null) {
tmp.add(s);
}
bfr.close();
this.data = new double[tmp.size()][2];
this.cate = new int[tmp.size()];
this.center = new double[k][2];
for (int i = 0; i  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3908
3908

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









