







 深度学习技术在人工智能领域崛起,中科寒武纪NPU专为神经网络处理定制,优化芯片架构,提升处理效率,赋能移动端AI芯片。寒武纪NPU通过片上存储和神经网络计算指令集,实现高性能功耗比。
深度学习技术在人工智能领域崛起,中科寒武纪NPU专为神经网络处理定制,优化芯片架构,提升处理效率,赋能移动端AI芯片。寒武纪NPU通过片上存储和神经网络计算指令集,实现高性能功耗比。
人工智能领域深度学习兴起;神经网络规模快速增长,对计算能力需求提升。深度学习技术评为 2013 年十大突破性技术之首,带动了人工智能的再次兴起;深度学习凭借其更加优秀的拟合能力, 在语音识别、图像处理等领域取得诸多本质性的突破。近些年,随着深度学习的神经网络规模的快 速增长,相关 AI 领域的识别准确率有了大幅提升,但是随之而来的是:整体深度学习架构对计算 能力的需求有了爆发式的增长。

传统计算架构在神经网络处理方面有所欠缺。目前深度学习的基本操作是神经元和突触的处理,传 统的处理器指令集(包括 x86 和 ARM 等)是为了进行通用计算发展起来的,其基本操作为算术操 作(加减乘除)和逻辑操作(与或非),往往需要数百甚至上千条指令才能完成一个神经元的处理, 深度学习的处理效率不高。
中科寒武纪 NPU 专为神经网络处理定制,提供高性能功耗比解决方案,赋能移动端 AI 芯片。中 科寒武纪是全球智能芯片领域的先行者,宗旨是打造各类智能云服务器、智能终端以及智能机器人 的核心处理器芯片。2016 年推出的寒武纪 1A 处理器(Cambricon-1A)是世界首款商用深度学习 专用处理器,面向智能手机、安防监控、可穿戴设备、无人机和智能驾驶等各类终端设备,在运行 主流智能算法时性能功耗比全面超越 CPU 和 GPU,与特斯拉增强型自动辅助驾驶、IBM Watson 等国内外新兴信息技术的杰出代表同时入选第三届世界互联网大会(乌镇)评选的十五项“世界互
联网领先科技成果”。中科寒武纪 NPU 专为神经网络定制:
1)、优化芯片架构,提升芯片对于神经网络的处理效率。传统架构存储和处理是分离的,分别由 存储器和运算器来实现(X86 处理器和英伟达 GPU);而神经网络中存储和处理是一体化的,都 是通过突触权重来体现;当传统架构计算神经网络时将受到存储和处理分离式结构的制约,因而影 响效率。寒武纪策略则通过“片上存储”的方式尽量减少访存次数,提升性能。
图 6:通过改变芯片架构、优化片上存储层次,降低访存次数、提升性能

资料来源:中科寒武纪、中科院、东方证券研究所
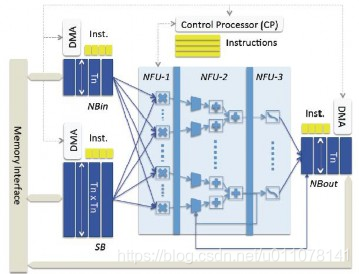
2)、基于优化的芯片架构,针对性的提出神经网络计算处理的指令集。传统的计算架构并非是专 门针对神经网络架构计算而设计;而寒武纪 NPU 芯片设计能够对于任意规模 DNN、CNN、MLP、 SOM 等多种神经网络算法能够实现通用性的支撑,同时对神经元和突触数据在芯片上的传输提供 了一系列专门的支持;实现一条指令即可完成一组神经元的处理。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











