







本系列文章介绍人工智能的基础概念和常用公式。由于协及内容所需的数学知识要求,建议初二以上同学学习。 运行本系统程序,请在电脑安装好Python、matplotlib和scikit-learn库。相关安装方法可自行在百度查找。
朴素贝叶斯算法(Naive Bayers)是一种基于概率的分类方法。它在条件独立假设的基础上,使用贝叶斯定理构建算法。
我们先来看一个案例。用一个假冒的呼气测试仪来测试司机是否醉驾。假设这个仪器有5%的概率会把一个正常的司机判断为醉驾,但对真正醉驾的司机测试则是100%准确。从过往的统计得知,大概有0.1%的司机为醉驾。现在问题是,假设用这仪器随机检测一名司机是醉驾的概率有多高?
假设我们过往的记录里有1000个检测司机,里面有1个是醉驾(0.1%)。其余999个是正常的。仪器有5%的误判,即999×5%+1个司机被定为醉驾。由此可得被判断为醉驾的概率是1/(999×0.5+1)=1.96%。
由此我们可以推导出一条公式:
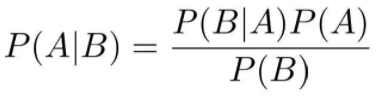
举例说明
A为司机真的醉驾,B为仪器显示司机为醉驾。例子要求的就是P(A|B)。即当仪器检测到司机是醉驾,而司机也是真醉驾的概率是多少。P(A|B)也叫联合概率。
P(A)表示司机真正醉驾的概率,也叫先验概率。即0.1%。
P(B)表示仪器显示司机醉驾的概率。这里包括两方面数据。一个是司机真醉驾的0.1%。另一个是没醉驾被误检的(1-0.1%)×5%。所以
P(B)=0.1%+(1-0.1%)×5%
P(B|A)表示当司机真的醉驾时,仪器检测的概率。即100%。
把数值代入公式:(0.1%×100%) / (0.1%+(1-0.1%)×5%)=1.96%
以上就是贝叶斯定理。
再举例说明
有两份报纸,人民日报和浙江日报,其中每张报纸出现“商业”和“股票”的概率如下:
- P(S|RM)人民日报有“商业”的可能性:0.7
- P(M|RM)人民日报有“股票”的可能性:0.2
- P(S|ZJ)浙江日报有“商业”的可能性:0.1
- P(M|ZJ)浙江日报有“股票”的可能性:0.1
现在假设阅读两份报纸的人是一样多的即P(RM)=0.5,P(ZJ)=0.5。
那么这里的y代表类变量,例子中报纸的名称,xn代表特征向量,例子中的词语。假定每个特征向量相互独立,我们要计算浙江日报中有“商业”和“股票”的可能性。
P(ZJ | S,M)=(P(ZJ)* P(S | ZJ)* P(M | ZJ))/ P(S,M)
除了P(S,M)其他变量都是已知的。
P(S,M)=(p(ZJ)* P(S | ZJ)* P(M | ZJ))+(P(RM)* P(S | RM)* P(M | RM))
将他们替换成概率进行计算,结果是
P(RM| S,M)=0.933,P(ZJ|S,M)=0.067。
P(S,M)概率的计算,我们是把他所包含的概率相乘求出它的绝对概率。绝对概率有很多不足,当样本数据数量较少时,概率的偏差会非常严重。Scikit-learn支持朴素贝叶斯算法支持高斯分布、多项式分布和伯努利分布等几种概率方式。
示例程序
下面我们看一个程序例子,这个例子分别用素贝叶斯算法支持高斯分布、多项式分布和伯努利分布概率方法对样本数据进行训练。再根据训练结果用predict,predict_log_proba和predict_proba三种方法进行预测。
例子是这样的,提供一组二元样本(1,1),(1,2)...。分别对应结果(1),(2)...。经过训练后,测试下一组样本(-0.8,-1)对应的结果是1还是2。
from sklearn.naive_bayes import GaussianNB
from sklearn.naive_bayes import MultinomialNB
from sklearn.naive_bayes import BernoulliNB
import numpy as np
X = np.array([[1, 1], [1, 2], [1, 0], [3, 0], [2, 1], [2, 3]])
Y = np.array([1, 1, 1, 2, 2, 2])
clf = GaussianNB()
#拟合数据
clf.fit(X, Y)
print("-------GaussianNB------------------")
print("Predict result by predict:",clf.predict([[-0.8, -1]]))
print("Predict result by predict_proba:",clf.predict_proba([[-0.8, -1]]))
print("Predict result by predict_log_proba:",clf.predict_log_proba([[-0.8, -1]]))
print("-------MultinomialNB---------------")
clf = MultinomialNB()
#拟合数据
clf.fit(X, Y)
print("Predict result by predict:",clf.predict([[-0.8, -1]]))
print("Predict result by predict_proba:",clf.predict_proba([[-0.8, -1]]))
print("Predict result by predict_log_proba:",clf.predict_log_proba([[-0.8, -1]])
print("-------BernoulliNB----------------")
clf = BernoulliNB()
#拟合数据
clf.fit(X, Y)
print("Predict result by predict:",clf.predict([[-0.8, -1]]))
print("Predict result by predict_proba:",clf.predict_proba([[-0.8, -1]]))
print("Predict result by predict_log_proba:",clf.predict_log_proba([[-0.8, -1]]))
运行效果

输出的概率分别表示是1的概率和是2的概率。那个概率大系统就认为结果是那个。















 304
304











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









