







身份证、名片、书籍、 考试试卷、答题卡这些检测目标都属于矩形目标检测。
一,现有技术
传统检测方法思路:
第一步,采用滑动窗口,设置不同的大小,遍历图像,得到一些目标的候选框;
第二步,候选框的图像特征提取;
第三步,对候选框提取的特征进行分类器判断;
第四步,对判断为目标的候选框进行处理得到最终的目标边框。
基于深度学习的目标检测:
候选区域+深度学习的方法,如 R-CNN,Fast R-CNN, Faster R-CNN 等方法;
基于深度学习的回归方法,如 YOLO、SSD 等方法。最后得到目标的边框和类别。
二,现有技术存在的问题
将目标检测模块部署在移动端,目标检测必须具备实效性。
传统算法中,基于滑动窗口的区域选择没有针对性,窗口冗余多,时间复杂度高,
另外手工设计的特征对于多样性的变换没有很好的鲁棒性。
深度学习方法中,移动端轻量级网络结构往往达不到高精度。VGG 等网络结构虽
然能达到高精度,但部署到移动端很难达到实时性。
三,本文方法介绍
从图像中定位矩形目标的边框,有两方面:定位及评估准确性;
技术思路:利用目标的边缘与线段,借助 ransac 思想,使用满足条件的多条线段去估计一个凸四边形,用 4 条线段或者 3 条线段,就能 估计出符合期望的凸四边形。因此,ransac 过程中,先后使用 4 条线段、3 条线段去估 计凸四边形,如果成功,就得到矩形目标的边框。
本方法检测透视变换程度较小的矩形目标。目标呈现在图像上,是一个不 规则凸四边形,检测到的线段构成的凸四边形越接近矩形越好。
3D 世界坐标系转换到 2D 图像像素坐标系:
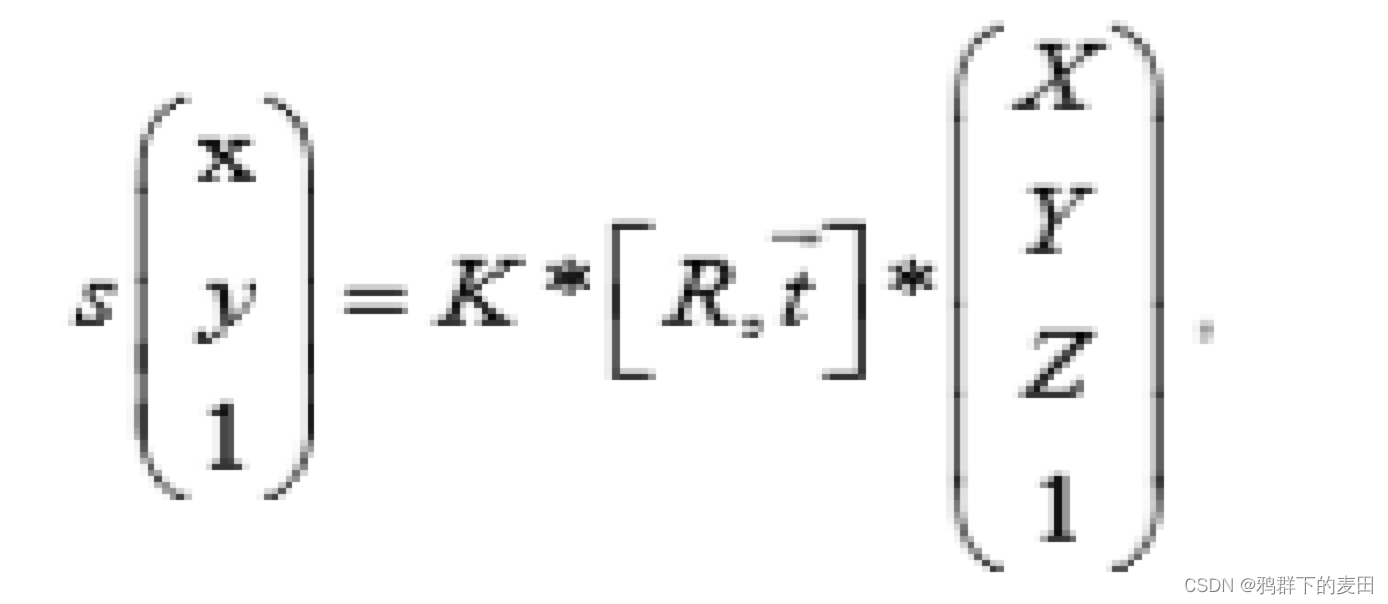
其中 K 是摄像机内参,R,t 为世界坐标系到摄像机坐标系的旋转、平移变换。目标是一
个平面时,例如如文本平面,这里假定此平面是世界坐标系下的 Z=0 平面,则目标上的点
对应的上述变换就变成了:
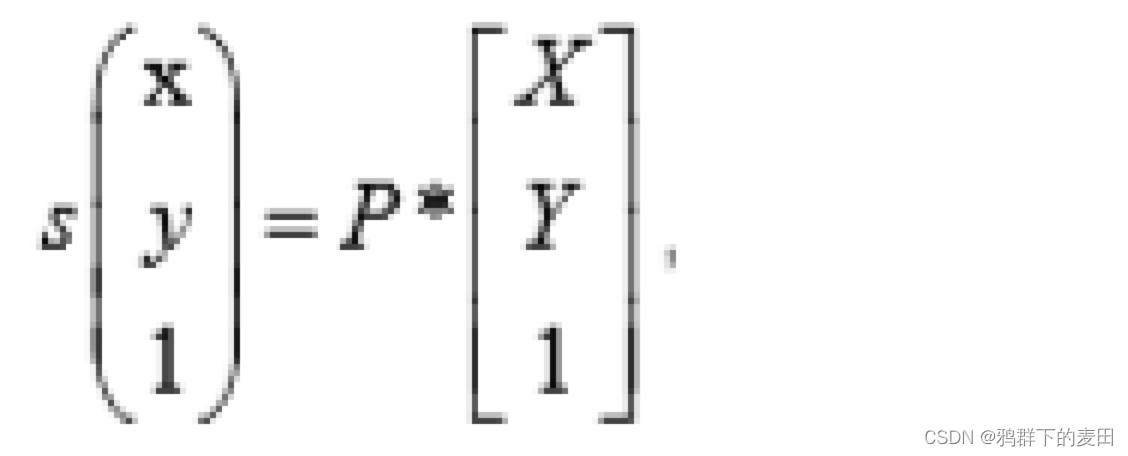
其中 P 是 3x3 可逆矩阵,涵盖了摄像机内外参数,那么透视变换过程就是:
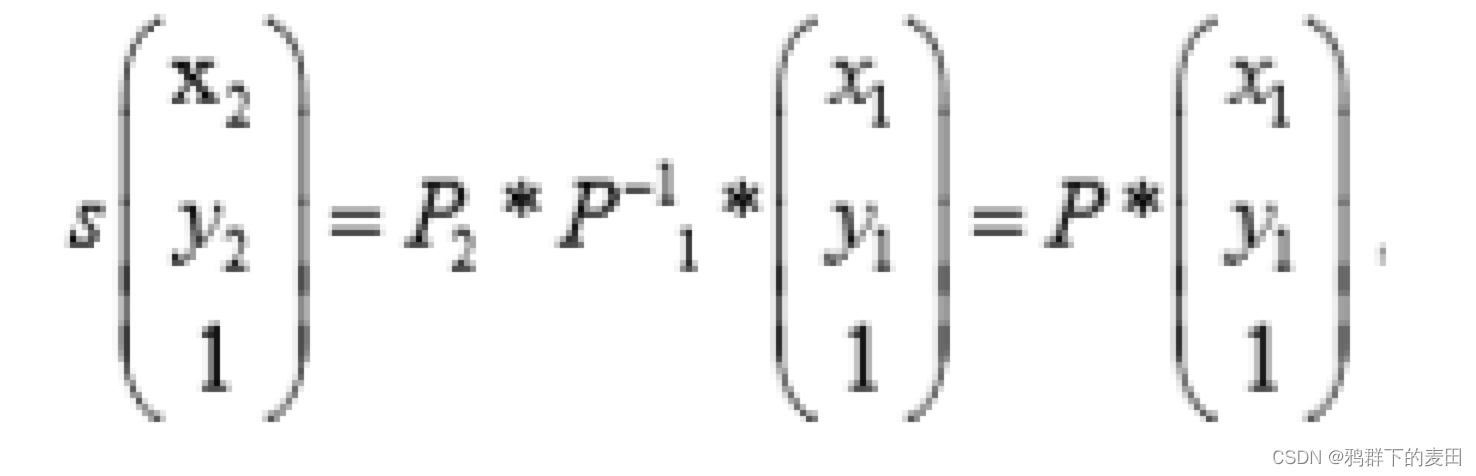
其中 P 是透视变换矩阵,可以基于对应的两个二维点集估计出来。
如果想要得到摄像机位置 1 到位置 2 的 x,y,z 三个方向的旋转角度,这需要估计 P,是一
个摄像机姿态估计问题。
因此,3D 空间中的矩形目标,变换后到图像上一个不规则凸四边形,这个凸四边形与
原矩形约接近越好。
四,流程
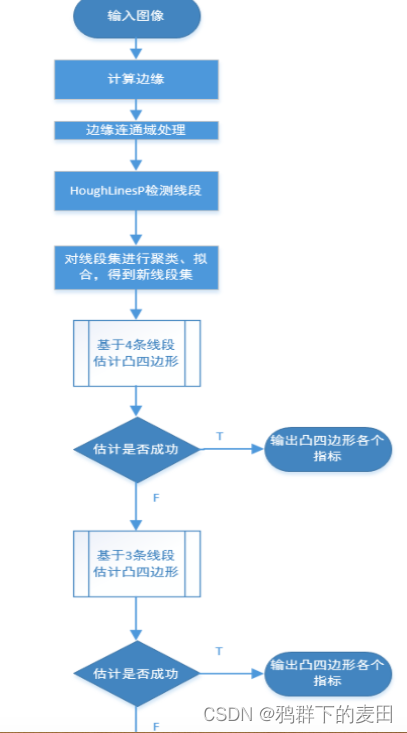
第 1 步,计算图像的边缘
可以使用传统的边缘检测方法,如 canny 边缘。
也可以使用轻量级的网络,检测边缘。精度不要求太高,移动端达到实时性就好。如
基于 mobilenet 训练的 HED 方法。
第 2 步,线段检测
利用基于概率的霍夫变换直线检测在边缘图上检测线段。
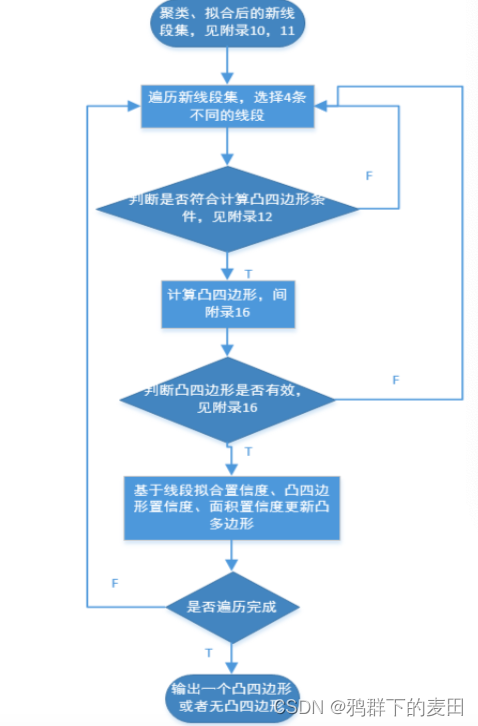
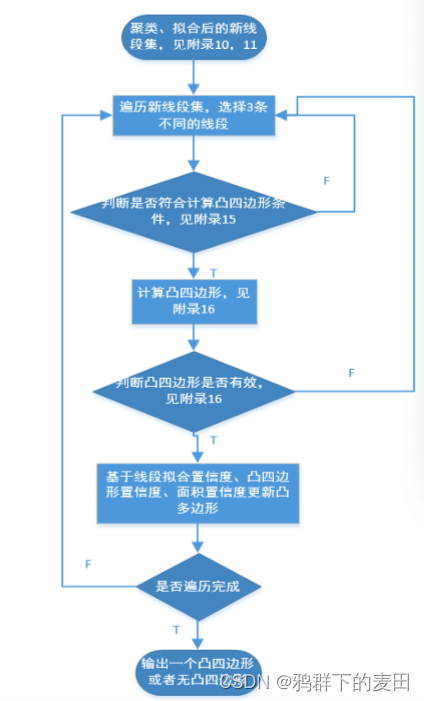
第 3 步,对线段进行合并,得到新线段集,见附录[9][10][11]
设定两直线距离阈值 e1、两直线弧度阈值 e2,两条线段的直线距离、弧度差若达到阈
值以内,则合并两线段为一条新线段。这样,遍历所有线段后,得到一组新的线段集。
第 4 步,遍历新线段集,抽取 4 条线段估计凸四边形。
如果估计成功,则输出凸四边形,作为边框定位结果;
如果估计不成功,进入第 5 步。
第 5 步,遍历新线段集,抽取 3 条线段估计凸四边形。
如果估计成功,则输出凸四边形,作为边框定位结果;
如果估计不成功,则失败。
五,效果
手持、弯折


















 9529
9529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









