







 本文探讨了企业业务连续性的概念,强调IT系统在业务中的重要性及其面临的风险。通过提升监控、增强架构容灾能力、实施故障管理策略,企业旨在确保在面对突发事件时能快速恢复。文章还提倡在系统设计中融入面向故障的思维,确保业务系统的稳定性贯穿整个生命周期。
本文探讨了企业业务连续性的概念,强调IT系统在业务中的重要性及其面临的风险。通过提升监控、增强架构容灾能力、实施故障管理策略,企业旨在确保在面对突发事件时能快速恢复。文章还提倡在系统设计中融入面向故障的思维,确保业务系统的稳定性贯穿整个生命周期。
什么是企业的业务连续性
企业的业务连续性是指企业在面对各种内部和外部的不可预测的风险和突发事件时,能够保持业务活动的持续性和稳定性的能力。这些风险和突发事件可能包括自然灾害(如地震、洪水、风暴)、人为事件(如恐怖袭击、供应链中断、数据泄露)以及技术故障(如系统崩溃、网络攻击)等。
业务连续性管理是指企业通过一系列的策略、计划和措施来减轻这些风险,并确保在面对突发事件时能够快速、有效地恢复业务运营。这些措施可能包括制定灾难恢复计划、备份关键数据和设备、建立备用工作场所、培训员工应对突发事件等。
通过有效的业务连续性管理,企业可以最大限度地减少业务中断对其运营和声誉造成的影响,提高组织的韧性和可持续性。
IT运维使命之一:保障IT系统长期稳定运行
企业的IT系统支撑着企业的正常运行,IT系统一但故障,就有可能给企业带来不可估量的损失。比如,生产线停产,销售停摆,物流网络瘫痪,被薅羊毛到破产等等。
但随着越来越多的新技术引入,业务发展越来越复杂,生产环境上运行的系统复杂度起来起高,影响业务连续性的因素也越来越多。
影响业务连续性的相关因素
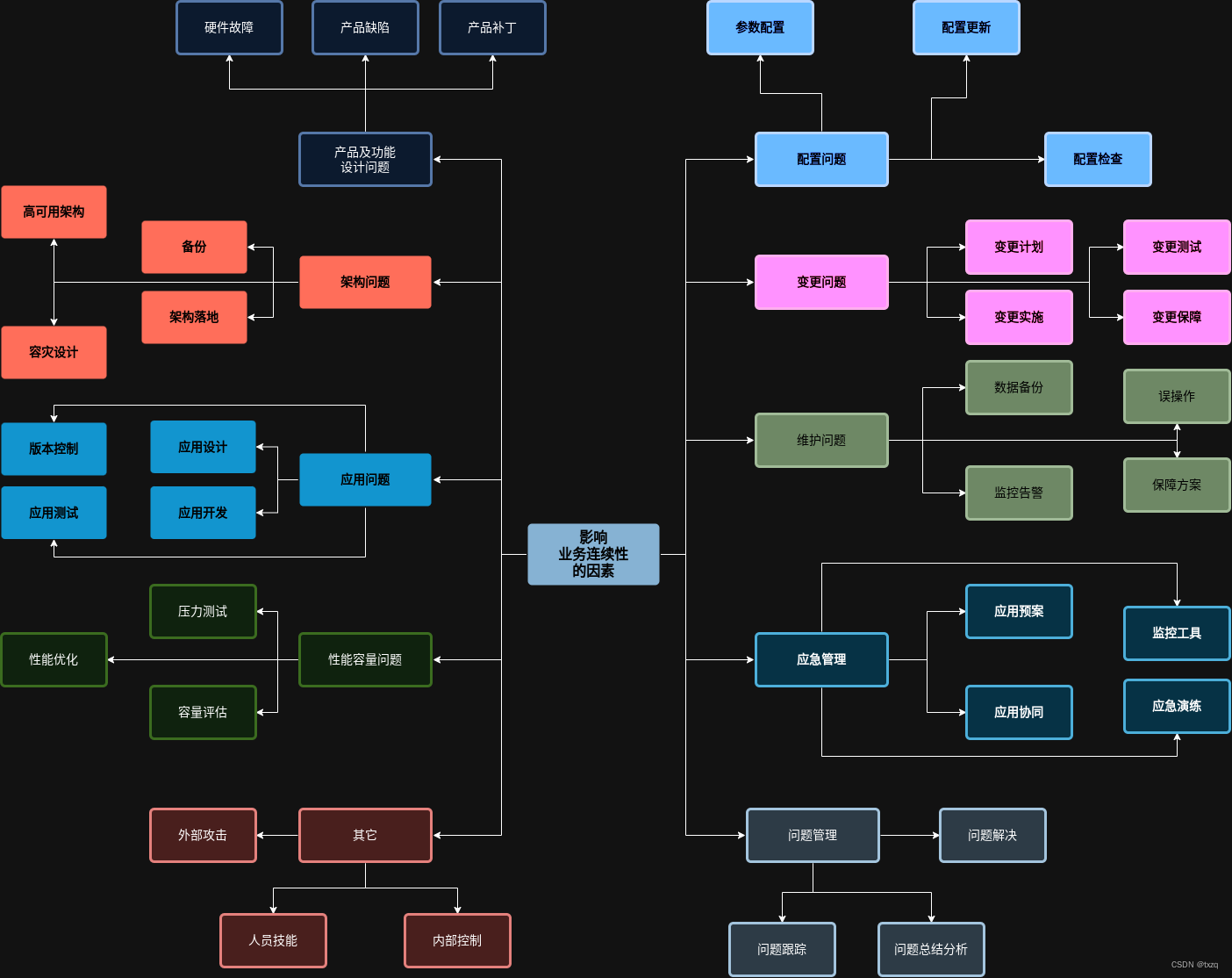
这还只是列举了一部分常见的因素,可见稍有不慎,我们的生产系统就有可能产生故障。
如何提升业务连续性保障水平
我们要提升业务连续性的保障水平,可以围绕故障管理生命周期展开,运维可以针对下面几个点来进行相应的能力建设:
- 提升监控覆盖面
从系统基础监控、到应用监控、到业务监控 - 提升监控发现事件的及时性
监控一定是方便问题定位与排查的 - 提升架构或者容灾的可用性
有条件的支撑双活,容灾,单元化架构 - 提升应用架构非功能性设计能力
除了完成业务功能外,增加比如熔断、限流、服务下线等非功能性设计 - 快速感知业务影响
通过影响的人、业务、关联的周边系统,快速决策故障等级,迅速拉起故障处理小队 - 加快故障诊断
通常监控及业务表现,相关业务系统的开发、产品、运维人员迅速定位问题,解决问题。 - 加强应急协同
设立专门的故障处理协同机制,UIOC(Urgent Incident Operations Center) - 加强应急处理的能力
针对不同的场景,有专门的工具,可帮助提升解决问题的效率。
故障是一定会发生的
作为一名IT从业人员,你一定要相信,故障是不可避免的,是一定会发生的。所以我们在设计一个产品和系统的时候,必须要假设故障是一定会发生的,要面向故障进行设计。
比如:
网络一定会有断的时候,也许是因为施工队的大型挖机一铲子的事情。
服务器也有罢工的时候,服务器也都是有使用寿命的,超过5年,出现故障的概率会大大增大。
机房也是有可能停电的,工厂也会被电力局拉闸限电的时候。
即使是AWS、AZURE、Google Cloud也会有大面积故障的时候。
统所依赖的外部的接口,也会返回500的时候,数据库也会有崩溃的时候。
所以,对那些重要性很高的系统,在做架构设计与开发的时候一定是要面向故障编程的。
业务系统稳定性贯穿于整个系统生命周期
从技术选型,到架构设计,到详细设计,到开发实现,到集成测试,到UAT测试,上线前压力测试,到部署环境的准备,监控、上线前检查,上线后的日常巡检、版本的变更等,都需要有相应的流程和管控卡点,才能保障业务系统上线后的稳定运行,是只有整个IT团队通力合作才能完成的一件事情。

















 616
616

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









