







首先要能编译、能打印log
编译的方法有两种,1) bazel 2) make
可以在本地编译调试使用bazel test
bazel test //tensorflow/lite/experimental/micro/examples/gesture_recognition:gesture_recognition_test
到路径下bazel-bin/tensorflow/lite/experimental/micro/examples/gesture_recognition/找到对应的bin,然后运行得到log.
使用make
make -f tensorflow/lite/experimental/micro/tools/make/Makefile test
当前makefile有问题,更改一点或者不该都是全编译,太慢,推荐用bazel编译
1. 为什么引入tflite for mcu
tflite for mcu因硬件的限制如内存, 使用和tflite不同的interpreter和算子等。因内存的限制使tflite不能使用c++的高级用法
如hastable等。tflite仍使用c++作为主要编程语言,但主要是使用c with class。
我的体会是因为内存的限制导致tflite for mcu只能用c++的部分功能或者说库,导致tflite for mcu从tflite 中分离出来。
tflite for mcu的目标是没有库支持、没有操作系统,完全裸的情况,实际中还是会用一些库,看内存的大小而定。
2. tflite 和tflite for mcu的关系
两者都是用tflite格式的模型文件,
但是否通用要看算子是否都实现了
两者使用相同的核心数据结构 TfLitexxx(TfLiteContext, TfLiteTensor, TfLiteNode等等)
lite/c/
├── builtin_op_data.h
├── c_api_internal.c
├── c_api_internal.h
两者使用相同的接口(C++虚类), tflite和tflite for mcu给出具体的实现
lite/core/
├── api
│ ├── BUILD
│ ├── error_reporter.cc
│ ├── error_reporter.h
│ ├── flatbuffer_conversions.cc
│ ├── flatbuffer_conversions.h
│ ├── op_resolver.cc
│ ├── op_resolver.h
│ ├── profiler.h
│ ├── tensor_utils.cc
│ └── tensor_utils.h
├── subgraph.cc
└── subgraph.h
使用tflite for mcu进行推断的流程:
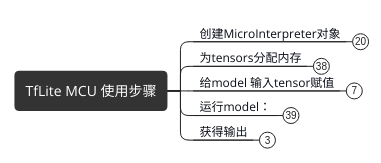
1] 根据如下元素创建micro_interpreter
error_report(打印log的实现), op_resolve(算子的实现)和 内存(初始地址和大小), 还有最重要的 tflite格式的模型文件
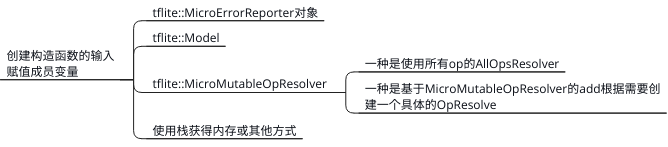
因为内存等限制MCU平台可能没有实现文件系统,tflite for mcu直接使用全局变量数组保存模型文件; 内存的分配也直接使用从栈里分配的unsinged char数组。
tflite
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3929
3929











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









