









1) 修改原因
用户需要阅读大量相同的数据库表,比如相同schema的表有1000张(比如对mysql进行分表分库)需要全读,每次建立dataframe的时候需要通过jdbcrelation去查询每一张表的schema,需要消耗了大量时间。本文对提出一种修改办法,如果用户知道表的sechema相同,可以使用sechema复用功能。
2) 代码流程
val df = sqlContext.read().format("jdbc").options(dfOptions).load();
->resolved= ResolvedDataSource(
sqlContext,
userSpecifiedSchema =userSpecifiedSchema,
partitionColumns = Array.empty[String],
provider = source,
options = extraOptions.toMap) //解析数据源,获取jdbc、parquet、josn的schema参数
->dataSource.createRelation(sqlContext,new CaseInsensitiveMap(options)) //传入options
->JDBCRelation(url, table, parts, properties)(sqlContext) //获取jdbc的relation
->override val schema= JDBCRDD.resolveTable(url, table, properties) //获取schema
->conn.prepareStatement(s"SELECT * FROM $table WHERE1=0").executeQuery() //直接读取database,需要优化
3) 修改方法
在用户知道schema的情况下,没有必要重复获取schema;
用户定义是否需要重复使用schema,修改代码流程最小;
修改方法:
a) 用户通过Options传入需要复用schema的开关:
dfOptions.put("jdbcschemakey","sparkourtest");
b) 建立一个hashtable,保存已经获取的shema
val schemaHashTable= newjava.util.HashMap[String,StructType]()
c) schema获取流程:
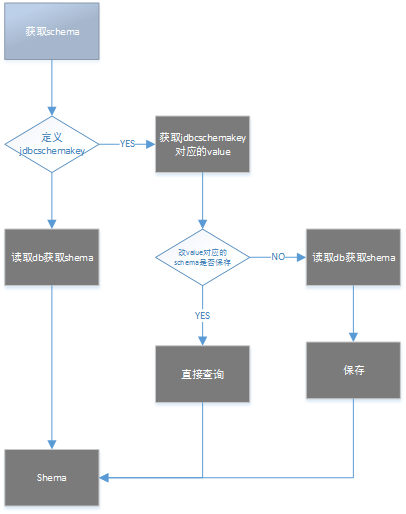
4) 修改代码
| 29a30 > import org.apache.spark.Logging 40c41 < private[sql] object JDBCRelation { --- > private[sql] object JDBCRelation{ 48a50,55 > > > // add by Ricky for get same table schema > > val schemaHashTable= new java.util.HashMap[String,StructType]() > 117c124 < private[sql] case class JDBCRelation( --- > private[sql] case class JDBCRelation ( 124c131 < with InsertableRelation { --- > with InsertableRelation with Logging{ 128c135,160 < override val schema: StructType = JDBCRDD.resolveTable(url, table, properties) --- > > // add by Ricky for get same table schema > def getSchema():StructType={ > //val schemaKey = properties.getProperty("jdbcSchemaKey") > val schemaKey = properties.getProperty("jdbcschemakey") > if (schemaKey != null) { > val schemaStored = JDBCRelation.schemaHashTable.get(schemaKey) > if (schemaStored != null) { > schemaStored > } else { > val schemaStored = JDBCRDD.resolveTable(url, table, properties) > logInfo("schemaKey configed,schemaHashTable empty,now put "+schemaKey.toString) > JDBCRelation.schemaHashTable.put(schemaKey, schemaStored) > schemaStored > } > } > else > { > JDBCRDD.resolveTable(url, table, properties) > } > > } > > override val schema: StructType = getSchema() > // end by Ricky > // override val schema: StructType = JDBCRDD.resolveTable(url, table, properties) |















 1359
1359

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









