







结合前段时间使用Cassandra使用过程,团队简单总结了Cassandra 数据模型设计,请大家斧正。
1、相关概念
- Column:Cassandra中的最基本的存储单元,用于存储某一行的信息;
- primary key:决定每行数据的唯一性;
- Row key:又称partition key,也即我们经常说的K-V中的key,是primary key中的第一列或者组合起来的复合列,partition key决定了每行数据在集群节点间的数据分布;
- 复合key:又称compound key,是由多列组成的row-key;
- Column key:column name。
Cassandra的模型结构可以理解为嵌套的map:
Map<RowKey,SortedMap<ColumnKey, ColumnValue>>
等同于下图:

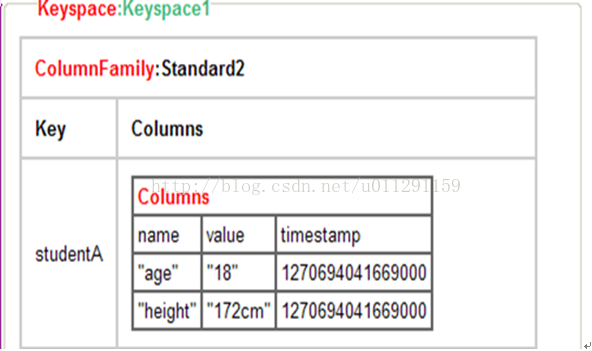
更具体设计如下图所示:
3.设计原则(重点,值得大家反思,nosql !=sql)
1、需要结合业务特点和Cassandra的模型结构,围绕查询模式进行ColumnFamily建模设计;
2、在设计表的时候,尽量减免表关联查询,按照实体对象,进行必要的反范式设计;
3、由于Cassandra的嵌套排序map数据结构,在模型设计时应考虑如何组织数据到这种类型的map中,以满足快速查询/排序/分组/过滤/聚合的要求;
4、不支持复杂sql的查询,比如,joins, group by,order by(因为order by是在设计时决策,Cassandra不支持Order By,排序是需要设计时考虑,而不是像在关系型数据库查询时刻使用Order By);
5、选择合适的rowkey,以实现数据分布,尽量保证rowkey唯一;
例如:primary key((date, type, hashcode), vendor) --加入hashcode能将数据尽可能的分布到多个节点中,以避免单点和热点的压力;
6、在第五点的基础上,尽量避免大key小value的出现,这样会导致很差的性能效果;
7、根据业务特征,将多读数据的表和多写数据的表实现分离;
8、保持column简短,因为它将和每个column value一起被重复存储(根据数据副本数)。当column value的大小比column name小很多时,内存和存储的开销可能会是个问题,除了用column name存储数据(即value为空时)外;
例如:'fname' 优于 'firstname','lname' 优于 'lastname'。
9、设计合适的TTL
需要根据不同表的特征和column的数据保留策略,设计合适的TTL,以保留适当时间窗口的数据。
最后写一句话吧:不要把Cassandra当做传统数据库!

















 443
443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









