







L2 改善深层神经网络
1 深度学习的实践
课程时长105min25s
1.1 训练集&验证集&测试集
应用深度学习是一个迭代的过程
-
小数据阶段
- 验证集和测试集占比较大
- 70%实验集,30%测试集
- 60%实验集,20%验证集,20%测试集
-
大数据阶段
- 验证集和测试集占比减小
-
确保验证集和测试集的数据来自同一分布
-
没有测试集也是可行的
- 验证集作为测试集
- 此时应用于不需要进行无偏估计
1.2 偏差&方差
Bias&Variance
欠拟合、适度拟合、过拟合
- 训练集错误率1%,测试集错误率11%:方差较大
- 训练集错误率15%,测试集错误率16%:偏差较大
- 拟合训练集不佳
- 训练集错误率15%,测试集错误率30%:方差较大且偏差较大
- 训练集错误率0.5%,测试集错误率1%:方差较小且偏差较小
1.3 机器学习基础
- 是否有较高的偏差?
- 用于验证训练集性能
- 如果有,则尝试改变网络结构或使用其他类型网络
- 是否具有较高的方差?
- 用于验证测试集性能
- 如果有,采用更多的数据或者正则化方法
1.4 正则化
Regularization
减小方差的方法,避免过度拟合
-
在logistic回归中
min w , b J ( w , b ) J ( w , b ) = 1 m ∑ i = 1 m L ( y ^ ( i ) , y i ) + λ 2 m ∣ ∣ w ∣ ∣ 2 2 ∣ ∣ w ∣ ∣ 2 2 = ∑ j = 1 n x w j 2 = w T w \min_{w,b}J(w,b)\\ J(w,b)=\frac 1m \sum_{i=1}^mL(\hat y^{(i)},y^{i})+\frac {\lambda}{2m}||w||_2^2\\ ||w||_2^2=\sum_{j=1}^{n_x}w_j^2=w^Tw w,bminJ(w,b)J(w,b)=m1i=1∑mL(y^(i),yi)+2mλ∣∣w∣∣22∣∣w∣∣22=j=1∑nxwj2=wTw-
下标2指的是L2正则化
- 被称为权重衰减
-
L1正则化
λ m ∑ j = 1 n x ∣ w j ∣ = λ m ∣ ∣ w ∣ ∣ 1 \frac\lambda m\sum_{j=1}^{n_x}|w_j|=\frac \lambda m||w||_1 mλj=1∑nx∣wj∣=mλ∣∣w∣∣1- 如果使用L1正则化,则w结果会是稀疏的
- w中有很多0
-
b为实数,因此在正则化中可以进行省略
-
λ为正则化参数
-
-
在神经网络中
J ( w [ 1 ] , b [ 1 ] , … , w [ L ] , b [ L ] ) = 1 m ∑ i = 1 m l ( y ^ ( i ) , y ( i ) ) + λ 2 m ∑ l = 1 L ∣ ∣ w [ l ] ∣ ∣ F 2 ∣ ∣ w [ l ] ∣ ∣ F 2 = ∑ i = 1 n [ l − 1 ] ∑ j = 1 n [ l ] ( w i , j [ l ] ) 2 , w h i c h w : ( n [ l − 1 ] , n [ l ] ) J(w^{[1]},b^{[1]},\dots,w^{[L]},b^{[L]})=\frac 1m \sum_{i=1}^ml(\hat{y}^{(i)},y^{(i)})+\frac{\lambda}{2m}\sum_{l=1}^{L}||w^{[l]}||^2_F\\ ||w^{[l]}||^2_F=\sum_{i=1}^{n^{[l-1]}}\sum_{j=1}^{n^{[l]}}(w_{i,j}^{[l]})^2,which\ w:(n^{[l-1]},n^{[l]}) J(w[1],b[1],…,w[L],b[L])=m1i=1∑ml(y^(i),y(i))+2mλl=1∑L∣∣w[l]∣∣F2∣∣w[l]∣∣F2=i=1∑n[l−1]j=1∑n[l](wi,j[l])2,which w:(n[l−1],n[l])-
下标F表示Frobenius范数
-
将正则化加入计算中
d w [ l ] = ( f r o m b a c k p o p ) + λ m w [ l ] w [ l ] = w [ l ] − α d w [ l ] = w [ l ] − α λ m w [ l ] − α ( f r o m b a c k p o p ) dw^{[l]}=(from\ backpop)+\frac{\lambda}{m}w^{[l]}\\ w^{[l]}=w^{[l]}-\alpha dw^{[l]} =w^{[l]}-\frac{\alpha\lambda}{m}w^{[l]}-\alpha (from\ backpop) dw[l]=(from backpop)+mλw[l]w[l]=w[l]−αdw[l]=w[l]−mαλw[l]−α(from backpop)
-
1.5 为什么正则化可以减少过拟合
- 若正则化λ参数较大,权重矩阵
w
w
w被设置为接近0的值
- 神经网络神经元数量减少,深度不变
- 从过拟合状态倾向于向Logistic回归进行移动
- 使用tanh函数作为激活函数
- 若 w w w绝对值较小,则利用tanh函数接近线性部分
- 如果正则化参数较大,则 w w w较小,导致z[l]较小,从而使得接近线性部分,不适用于复杂决策
1.6 Dropout正则化
随机失活
对每层神经元,设置一个概率,随机删除神经元,使用删除后的神经元进行学习
-
反向随机失活:如一个三层神经网络
# 以(1 - keep-prob)概率失活 d3 = np.random.rand(a3.shape[0],a3.shape[1])< keep-prob a3 = np.multiply(a3, d3) #a3 * d3 a3 /= keep-prob #使得削减神经元之后a的期望值不变
1.7 理解Dropout
Dropout功能类似L2正则化
- 由于神经元的输入中将会被随机消除某几个,所以不能依赖某个神经元的输入特征
不同层的keep-prob可以不同
计算机视觉中应用较广
在绘制损失函数图像时候要设置为1,不然不能正常绘制
1.8 其他正则化函数
增大数据集
- 对数据集进行变换
- 图片翻转、裁剪、旋转、扭曲
提前终止 early stopping
- 训练过程中测试验证集
- 在中间停止
- 缺点:不能独立解决损失函数和方差较大问题
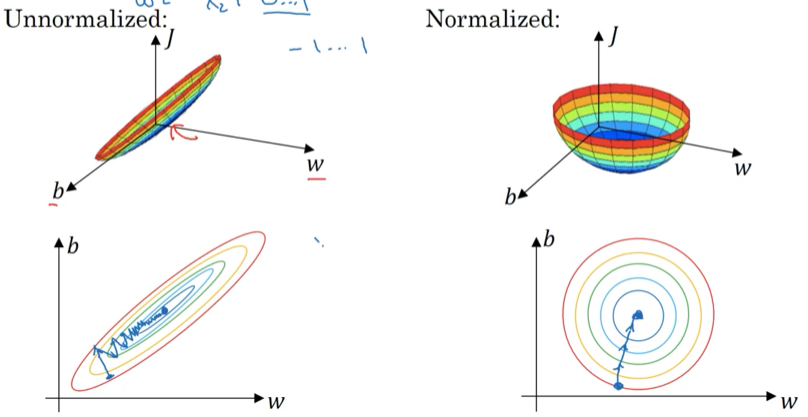
1.9 归一化输入
-
零均值化
μ = 1 m ∑ i = 1 m x ( i ) x : = x − μ \mu =\frac 1m \sum_{i=1}^m x^{(i)}\\ x := x-\mu μ=m1i=1∑mx(i)x:=x−μ -
归一化方差
σ 2 = 1 m ∑ i = 1 M x ( i ) 2 x / = σ \sigma^2=\frac 1m \sum _{i=1}^M x^{(i)^2}\\ x /= \sigma σ2=m1i=1∑Mx(i)2x/=σ
为什么归一化输入
-
方便找到极值
1.10 梯度消失和梯度爆炸
在较深的神经网络中
- 若 w w w大于1,容易造成梯度爆炸
- 若 w w w小于1,容易造成梯度消失
1.11 神经网络的权重初始化
一个不彻底的解决梯度消失和梯度爆炸的方法
-
ReLU函数
W [ l ] = n p . r a n d o m . r a n d n ( s h a p e ) ∗ n p . s q r t ( 2 n [ l − 1 ] ) W^{[l]}=np.random.randn(shape)*np.sqrt(\frac {2}{n^{[l-1]}}) W[l]=np.random.randn(shape)∗np.sqrt(n[l−1]2) -
tanh函数
W [ l ] = n p . r a n d o m . r a n d n ( s h a p e ) ∗ n p . s q r t ( 1 n [ l − 1 ] ) o r W [ l ] = n p . r a n d o m . r a n d n ( s h a p e ) ∗ n p . s q r t ( 1 n [ l − 1 ] + n [ l ] ) W^{[l]}=np.random.randn(shape)*np.sqrt(\frac {1}{n^{[l-1]}})\\ or\quad W^{[l]}=np.random.randn(shape)*np.sqrt(\frac {1}{n^{[l-1]}+n^{[l]}})\\ W[l]=np.random.randn(shape)∗np.sqrt(n[l−1]1)orW[l]=np.random.randn(shape)∗np.sqrt(n[l−1]+n[l]1)
1.12 梯度的数值逼近
导数的定义
使用双边误差更为准确:
f
(
θ
+
ξ
)
−
f
(
θ
−
ξ
)
2
ξ
\frac{f(\theta+\xi)-f(\theta-\xi)}{2\xi}
2ξf(θ+ξ)−f(θ−ξ)
1.13 梯度检验
假设网络中参数: W [ 1 ] , b [ 1 ] , W [ 2 ] , b [ 2 ] , … , W [ L ] , b [ L ] W^{[1]},b^{[1]},W^{[2]},b^{[2]},\dots,W^{[L]},b^{[L]} W[1],b[1],W[2],b[2],…,W[L],b[L]
将所有参数设置为向量 θ \theta θ
则 J ( W [ 1 ] , b [ 1 ] , W [ 2 ] , b [ 2 ] , … , W [ L ] , b [ L ] ) = J ( θ ) = J ( θ 1 , θ 2 , … ) J(W^{[1]},b^{[1]},W^{[2]},b^{[2]},\dots,W^{[L]},b^{[L]})=J(\theta)=J(\theta_1,\theta_2,\dots) J(W[1],b[1],W[2],b[2],…,W[L],b[L])=J(θ)=J(θ1,θ2,…)
同理,将参数 d W [ 1 ] , d b [ 1 ] , d W [ 2 ] , d b [ 2 ] , … , d W [ L ] , d b [ L ] dW^{[1]},db^{[1]},dW^{[2]},db^{[2]},\dots,dW^{[L]},db^{[L]} dW[1],db[1],dW[2],db[2],…,dW[L],db[L]
设置为 d θ d\theta dθ
则for each i:
d
θ
a
p
p
r
o
x
[
i
]
=
J
(
θ
1
,
θ
2
,
…
,
θ
i
+
ξ
,
…
)
−
J
(
θ
1
,
θ
2
,
…
,
θ
i
−
ξ
,
…
)
2
ξ
d\theta_{approx}^{[i]}=\frac{J(\theta_1,\theta_2,\dots,\theta_i+\xi,\dots)-J(\theta_1,\theta_2,\dots,\theta_i-\xi,\dots)}{2\xi}
dθapprox[i]=2ξJ(θ1,θ2,…,θi+ξ,…)−J(θ1,θ2,…,θi−ξ,…)
进行梯度检验:
∣
∣
d
θ
a
p
p
r
o
x
−
d
θ
∣
∣
2
∣
∣
d
θ
a
p
p
r
o
x
∣
∣
2
+
∣
∣
d
θ
∣
∣
2
,
i
n
w
h
i
c
h
ξ
=
1
0
−
7
\frac{||d\theta_{approx}-d\theta||_2}{||d\theta_{approx}||_2+||d\theta||_2}, in\ which\ \xi=10^{-7}
∣∣dθapprox∣∣2+∣∣dθ∣∣2∣∣dθapprox−dθ∣∣2,in which ξ=10−7
得到结果:
- ≈10-7:Great
- ≈10-5:Maybe is OK
- ≈10-3:Bug
1.14 关于梯度校验实现
- 不要在训练中使用梯度校验,仅仅用于调试
- 如果算法的梯度校验失败,要检查所用项
- 梯度检验时候,使用正则化
- 梯度检验不能和Dropout同时使用
- 随机初始化过程中,可以进行梯度检验
- 保证 w , b w,b w,b有一段时间远离0















 1036
1036











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









