







 本文介绍了软件开发中的分析和设计方法,包括文字文档、图形建模和数学模型等。图形建模部分重点讲解了思维导图、实体关系图、数据流图和UML的作用和应用场景。此外,文章还提到了从需求规格到实现的流程,以及开发阶段的日常管理策略,如每日构建和构建大师制度。
本文介绍了软件开发中的分析和设计方法,包括文字文档、图形建模和数学模型等。图形建模部分重点讲解了思维导图、实体关系图、数据流图和UML的作用和应用场景。此外,文章还提到了从需求规格到实现的流程,以及开发阶段的日常管理策略,如每日构建和构建大师制度。
摘至 邹欣《构建之法》一书,以作学习之用
分析和设计方法
我们写软件就是要解决用户的需求,我们需要表达和传递下面这些信息:
在“需求分析”阶段,我们要搞清楚
在问题领域中的现实世界里,都有哪些实体,如何抽象出我们真正关心的属性,实体之间的关系是什么,在这个基础上,用户的需求是什么,软件如何解决用户的需求
在“设计与实现阶段”,我们要搞清楚软件是怎么解决这些需求的?
在“测试”和“发布”阶段,我们要搞清楚软件真的解决了这些需求了么?
软件团队的所有相关人员都需要处理、了解这些信息,如果在处理的过程中有误解和遗失,就会导致开发过程中的问题,以至最终产品不能满足用户的需求。那么这些信息怎么表达才能更准确、更能有效地交流呢?
我们先看看两个初中水平的题目:
今有雉兔同笼,上有三十五头,下有九十四足,问雉兔各几何?
程序员果冻觉得写程序赚钱不多,他想捞外快。于是他参加了王屋村的搬砖大队,大队规定搬砖到目的地,没有破损则给运费每块砖四分钱,如果有任何破损或丢失则倒扣一毛五分钱。果冻搬到一半的时候觉得还是坐着写程序好,最后他搬了一千块砖,共得三十五块两毛五分钱。问果冻搬的砖头没有破损的有多少块?
这两个问题看似不容易,并且毫不相干,但是本书的读者应该都能毫不费力地用类似的方法来解答。我想最常见的思路是:这个问题实质上是二元一次方程求解:鸡兔同笼:
x+y=35;
4*x+2*y=94果冻搬砖:
x+y=1000;
4*x-15*y=3525我们还可以用二维坐标系图示的方法来得出直观的解法:
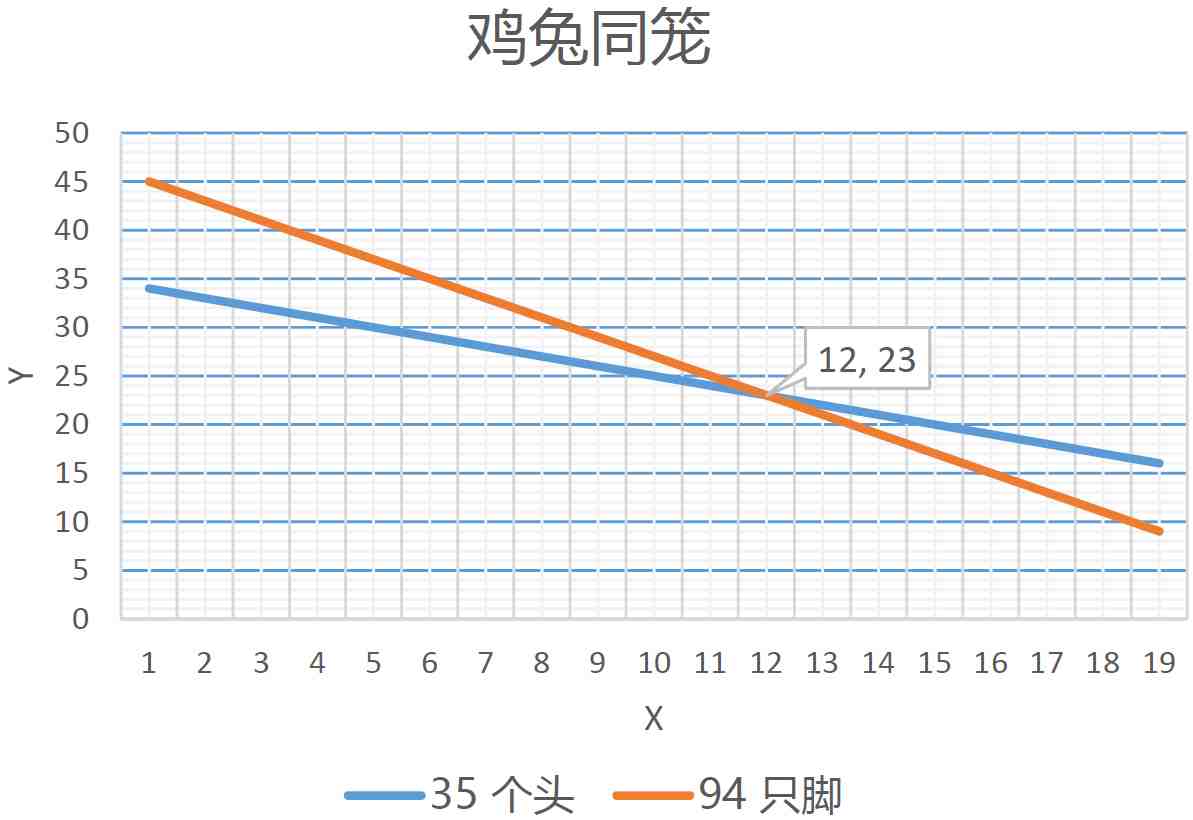
看典型解题者的解题过程,有下面的步骤:
理解,抽象:理解问题,过滤掉非核心信息,抽象出关键信息和它们之间的关系。(雉就是野鸡,我没看见过活的野鸡,在这个问题中它等同于家鸡,鸡长啥样?一只鸡有几个头,几只脚,兔子长啥样?……鸡头、兔头、鸡脚、兔脚要满足一些关系)
找到合适的数学模型:啊,这就是二元一次方程求解
根据模型和解法,按部就班地解决问题:这要依赖于对数学原理(交换律,等价性……)和基本操作的掌握
分析和设计有许多方法:
以文字为主的文档,如Word、PowerPoint 文档。正如我们在需求分析和场景设计中看到的那样
用图形为主构造的模型,如Mind Map(思维导图),ERD,DFD,UML的各种图,甚至包括Flow Chart流程图
用数学语言的描述,如Vienna Development Method
用类自然语言+代码构造的描述,如Literate Programming
源代码加注释也能描述
图形建模和分析方法
我们要给事物建造出一个“模型”,描述事物、事物的属性、事物之间的关系(静态的)以及各个事物之间的信息传递(动态的)。
11.2.1 表达实体和实体之间的关系(Entity Relationship Diagram, Entity Relationship Model,Mind Map)
1. 思维导图(Mind Map)
“一图胜千言”,人们经常用图形来帮助他们了解概念,强化记忆。思维导图是其中的一个例子。思维导图没有严格的语法定义,一般来说是从图形的正中开始写下一个概念,然后按照绘图者所关心的属性扩展,几乎每个人都能马上开始画图。这个看似简单的工具其实很适合团队一起讨论和理解核心概念——例如,我们的主要用户有什么特点、什么需求。
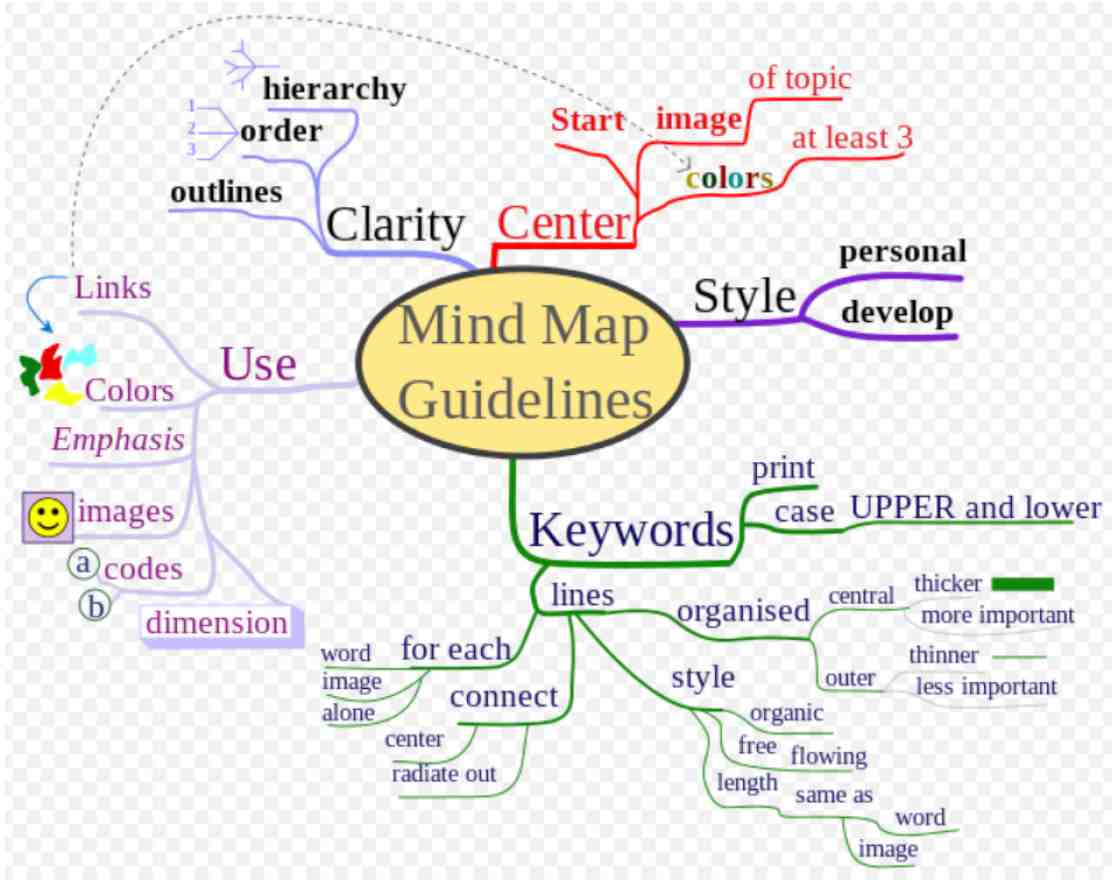
思维导图形式灵活,适用于很多鼓励探索、发散思维的场合(如头脑风暴会议),但是它的图形元素缺乏严格的语法和语义
2. 实体关系图(Entity Relationship Diagram)
如果我们着重于表达现实世界中的实体和它们之间的关系,那么实体关系图ERD是最自然的表达方式。下面是实体关系图的一个例子,表达了大多数读者都比较熟悉的“图书馆借书”的场景:
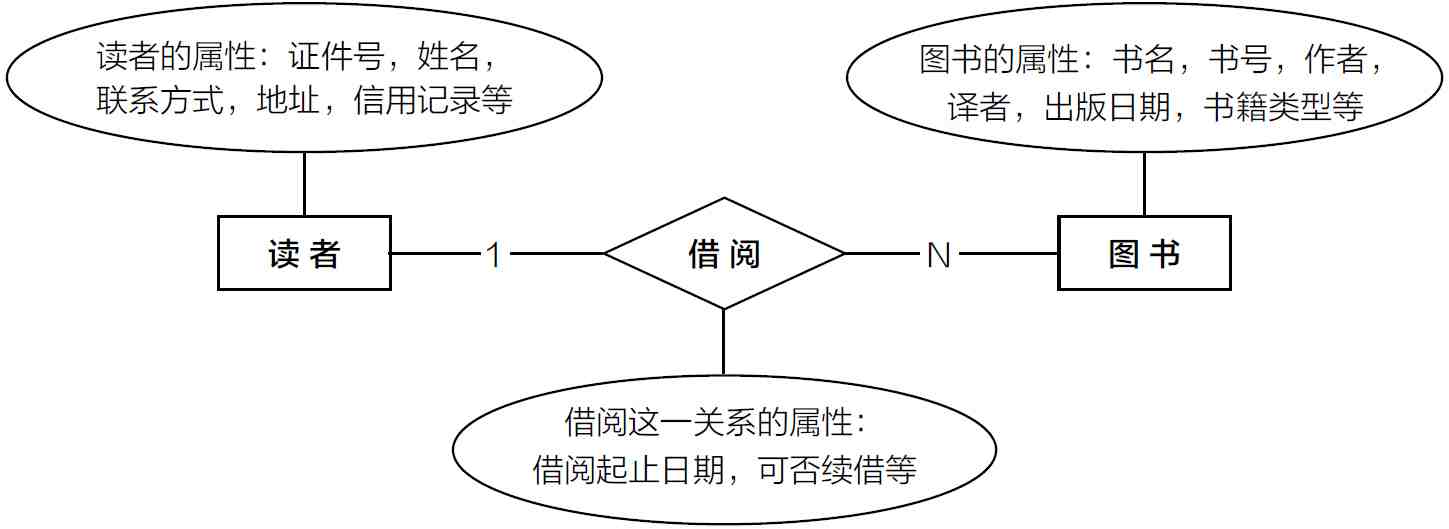
在我们分析实体之间的关系时,这就是一个理解和抽象的过程,例如,我们可以通过自然语言的帮助把各种元素归类到它们在ERD里适当的类型中,当我们要表示实体之间的静态关系时,ERD是一个合适的工具
3. Use Case Diagram(UCD)
上一章提到的用例(Use Case)也有图形化的表示。用例图主要有下列的元素:
参与者(Actor):表示参与系统运作的外部因素,例如用户,管理员,外部模块,设备,来自外部的信号等。通常是一个简笔画的小人
系统:通常用一个方框来表示系统的边界。有时也可以忽略
用例(Use Case):表示系统和参与者交互的一次场景。它是一组动作的集成,而不是一个单独的内部元素
信息传递线:用带箭头的线用来表示参与者和系统通过相互发送信号或消息进行交互的关联关系
用例图的元素简单,绘图简明,它的主要目的是尽快让团队成员和利益相关者(特别是对技术不熟悉的)理解系统的需求。
表达数据的流动(Data Flow Diagram)
当我们要关注数据在不同的实体之间依赖一定的规则流动的时候,DFD是一个合适的工具。还是用大学图书馆管理系统为例,它有什么数据流过呢?从下图来看,流过的数据还真不少。我们简要地列出几个例子:
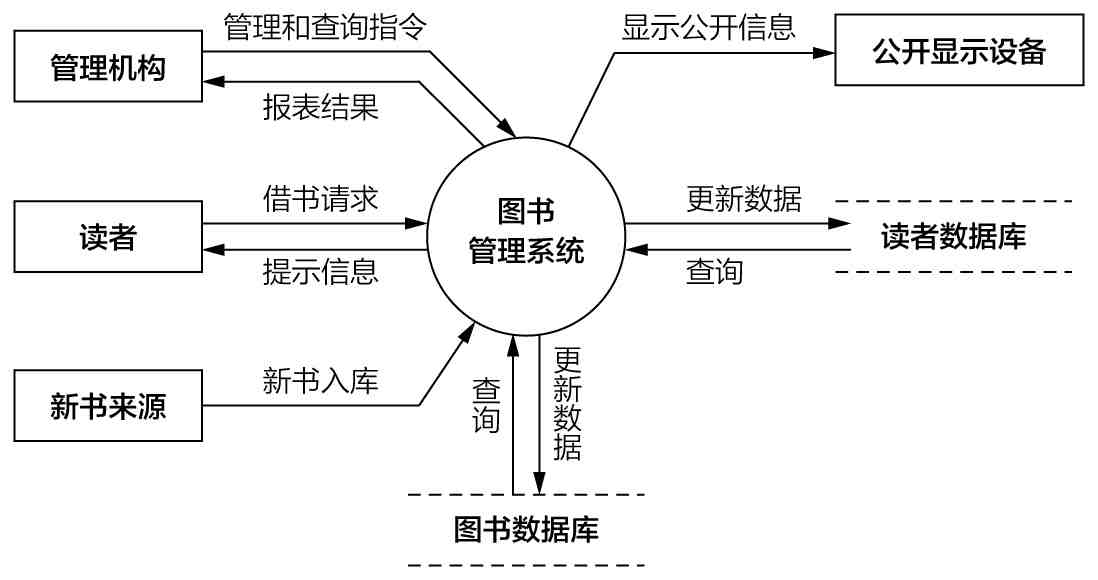
1)和管理机构相关的数据流
管理机构可以发出指令,“改变读者借书数量的上限”,这样的信息会导致图书馆的处理规则发生变化,并且会导致相关信息出现在“公开显示设备”——例如网页,或者电子公告板上。管理机构可以查询一定时间内图书借阅情况的明细或统计信息,这些信息或者返回到管理机构(例如——借书欠款最多的读者),或者出现在“公开显示设备”上(例如——本月热门人文类书籍前十名)。
2)和读者相关的数据流
读者可以查询、预定、借出书籍。
3)和新书入库相关的数据流
新书入库的时候,书的各种属性会被录入到系统内的“图书数据库”,同时内部管理系统能触发流程,让预定某书的读者知道,他关心的书已经到货。
4)和时间相关的数据流(图上没有表示)
时间也是信息,当某个时间点到达的时候,系统内部的逻辑会触发一系列动作,导致信息的处理和流动,例如每天晚上6点开始统计第二天图书到期的读者,并给这些读者推送催还消息。
每一个数据的操作还可以进一步细化,形成一个新的、更低层次的DFD。这些数据流能引导设计者全面设计系统的信息处理流程。DFD还能帮助系统得到安全设计,设计者可以分析能影响本系统的信息都从哪里来,外部数据和内部数据的边界在哪里?如果我们盲目相信信息源发出的数据,是否会造成严重后果?敏感数据都流到哪里去了?如果数据的目的地没有合适的保护,是否会造成敏感数据的泄露[注释2]?等等。如果我们再分析其他的信息管理系统(学籍管理,病历管理系统,BBS系统,等等),就能看出这些基于信息“增删改查”系统的共性。
表达控制流(Flow Chart, Finite State Machine)
我们在计算机理论基础课上都学过有限状态自动机(Finite State Machine, FSM),在程序设计语言基础课上都学过基本的流程图,这里不再赘述
统一的表达方式(Unified Modeling Language, UML)
这些图形建模方法各有特点,它们使用了不同的几何图形、标注规则、专有词汇和颜色。人们自然会想,能否有一个统一的表达方式?UML就是这样的回答。UML在20世纪90年代伴随面向对象的方法发展,在工业界的应用和反馈中成熟起来,2004年发布的UML2.0是一个相对稳定的版本。
其他设计方法
在计算机软件发展的过程中,科学家和工程师们还尝试了很多其他方法,它们在不同程度上解决了一些局部问题,从不同的方面推动了相关领域的发展。
1. 形式化的方法(Formal Method)
很多软件需求(例如计算机语言的编译器)可以抽象为对符号的运算和变换,很多软件的某些核心功能需要严密地验证,保证没有问题。一些科学家一直在努力,希望用无歧义的、形式化的语言描述我们要解决的问题,然后用严密的数学推理和变换一步一步把软件实现出来,或者证明我们的实现的确完整和正确地解决了问题。在这个领域一个比较成熟和经过实践考验的方法是Vienna DevelopmentMethod(VDM)
2. 文学化编程(Literate Programming)
程序员在写程序的时候,要理解在文档中的需求,同时还要在程序里写相关的注释,这些不同目的的“写作”各有价值,但是一旦需求或程序发生变化,这些不同的文档很难保持同步。更不用说程序员最常见的毛病“我以后会加上注释的……”Donald Knuth在20世纪70年代末开始尝试并提倡Literate Programming的思想并在自己的软件项目中身体力行。这一方法和常见的“写程序,时不时加上一些注释”相反,它是“写文档,时不时有些代码”。它使用了宏(Macro)来进行抽象和信息隐藏。通过工具的支持,它的源代码可以提取出让计算机编译执行的部分(叫Tangle),以及文档(叫Weave)
从Spec到实现
一个开发人员(比如小飞)拿到了设计文档(Spec)之后,他会做下面这几件事情。
估计开发任务所需的时间,他会参考以前同类任务所需花费的实际时间,以及其他同事的时间估计。
小飞会试着写一些快速原型的代码,看看效果会怎样。期间他发现了若干问题,与PM沟通后,最终达成一致意见。
在看到初始效果和了解了实现的细节后,小飞开始写设计文档(Technical Spec、Design Document),写好之后,他可以请同事一起来复审设计文档(复审可选,因为一般情况下任务都不大)。
设计文档写好之后,小飞就会按照设计文档写代码。在实现过程中,他又发现了一些意想不到的问题,与PM沟通后,找到了解决方案。
写好代码后,小飞对照设计文档和代码指南进行自我复审,重构代码。
创建或更新单元测试。
进行单元测试(不仅要自己创建或更新单元测试,还要通过整个模块/系统的单元测试)。
得到一个可以测试的版本,交给相关的测试人员测试,或者在网上进行某种公开测试,如A/B测试等。
修复测试人员或用户发现的问题,等到问题都解决得差不多了,就请同事进行代码复审。
根据代码复审的意见修改代码,完善单元测试和其他相关文档,然后把代码签入到代码库中。
把修改集集成到代码库中
现在开发人员手头上有不少修改,分别属于不同的具体任务,那如何将这些修改签入源代码控制系统呢?具体步骤如下:
根据场景和开发任务来决定集成的次序
互相依赖的任务要一起集成
在测试场景时,要保证端到端的测试
场景的所有者必须保证场景完全通过测试,然后把场景的状态改为“解决”
开发人员的标准工作流程
综上所述,我们就可以得到开发人员的标准工作流程
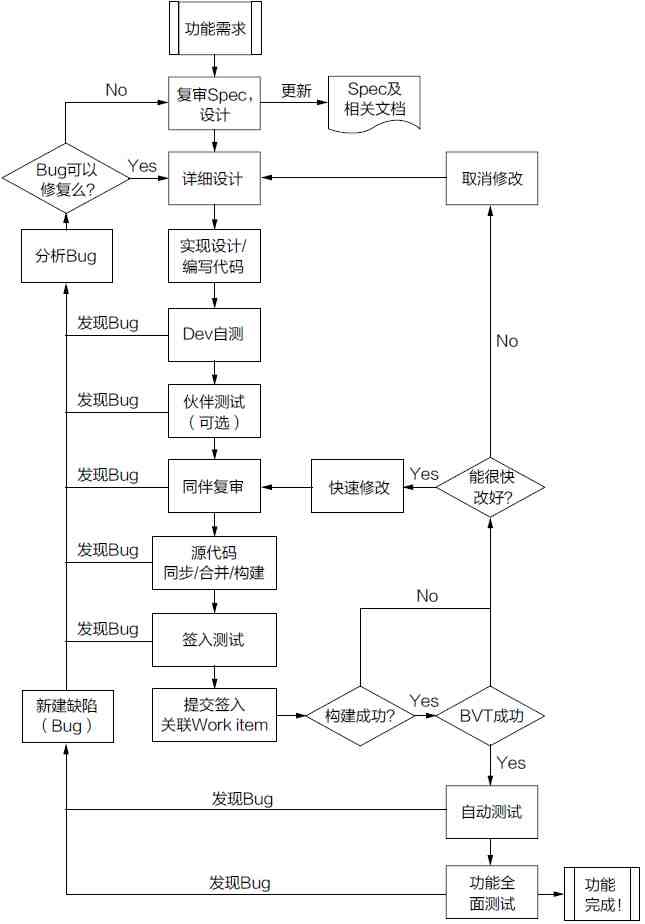
代码完成(Code Complete)
代码完成就是指工程师认为所有应该写的代码都写了,所有应该实现的功能都实现了(但未必没有问题)。
那么在这一状态的软件就是可以发布的吗?
不,还不行。代码虽然都写了,但是代码中可能会有很多Bug,各个模块之间的合作还有很多问题。Beta用户看到产品后,说不定要提不少修改意见。软件的其他工作(如各种类型的测试/国际化/本土化/给用户的文档)都没有完成。但是,软件团队毕竟是把“我们认为所有应该写的代码都写了,应该实现的功能都实现了”。这是一个了不起的事件。一个团队经过几个月的努力,从无到有,从简到繁,把几个月前的远景变成了可以运行的软件,也许我们还有许多问题,但这无疑是很值得庆祝的!
在TFS上,就是所有的代码任务(Task)都完成了。也许我们现在还有许多缺陷(Bug),还有一些与测试相关的任务。这些要留到以后稳定阶段才能全部解决。
开发阶段的日常管理
闭门造车(Leave Me Alone)
团队的E-mail会特别多。在这种情况下,不要整天被E-mail牵着鼻子走。在Outlook上设置好邮件规则,按下面的规则把邮件自动分类到不同的邮件夹中:
(1)从直接老板来的,发给你一个人的——马上处理
(2)从团队成员来的、和项目有关的事情,自动分配到一个叫“Team”的邮件夹中
(3)从TFS来的状态信息,如团队的check-in E-mail,自动分配到一个叫“Check-In”的邮件夹中
(4)从公司其他同事来的与工作无关的消息(如笑话、大减价的消息等),自动分配到一个叫“Other”的邮件夹中。最好每隔两三小时集中阅读和回复一下E-mail,对于短信、微信、微博等,也建议集中处理
(5)有些优秀团队(例如Google 公司的一些团队)规定一周有一天不能开会
每日构建(Daily Build)
在我们的全球调查中,我们发现成功公司中有94%每天或至少每周完成构建,而不成功公司绝大多数每月甚至更少去做构建……当有一个能运行的系统时,即使只是一个简单的系统,(团队的)积极性也会上升。
构建大师
对于下一个导致构建失败的成员,授予“构建大师”(Build Master)称号,构建大师做下面的事。
负责管理构建服务器。
调试构建,负责找错,并分析出错的原因。
负责把“构建大师”称号和责任交给下一个导致构建失败的成员。
“构建大师”同时向团队的“腐败基金”存入50元,以供大家将来“腐败”之用(此项可选)。
宽严皆误
构建终于成功了,现在构建成功了,明天呢?答:团队有两条路可以实行。
(1)严格的规则和流程控制,这样会保证很高的签入成功率,如果一个人根据流程来做,几乎肯定能成功。这样构建质量高,但是团队的进展会受到限制。极端情况下,整个团队的进展被序列化为一系列个人串行签入操作
(2)宽松的规则和流程,每个人随时可以签出签入,签入时的成本很低,但是签入成功率不高,构建质量低,极端情况下,所有人都可以签入、同步,但是没有人能正常工作
不审势即宽严皆误,从来治蜀要深思。那么,什么是我们这个团队目前的“势”呢。当团队成员的行为只是影响到个人时,就尽量放松,让个人根据自己的情况处理;当其行为影响到整个团队时,就尽量严格,因为整个团队都有可能会受影响。同时,我们要提高可预见性——明确构建大师的职责,公开显示固定的构建时间
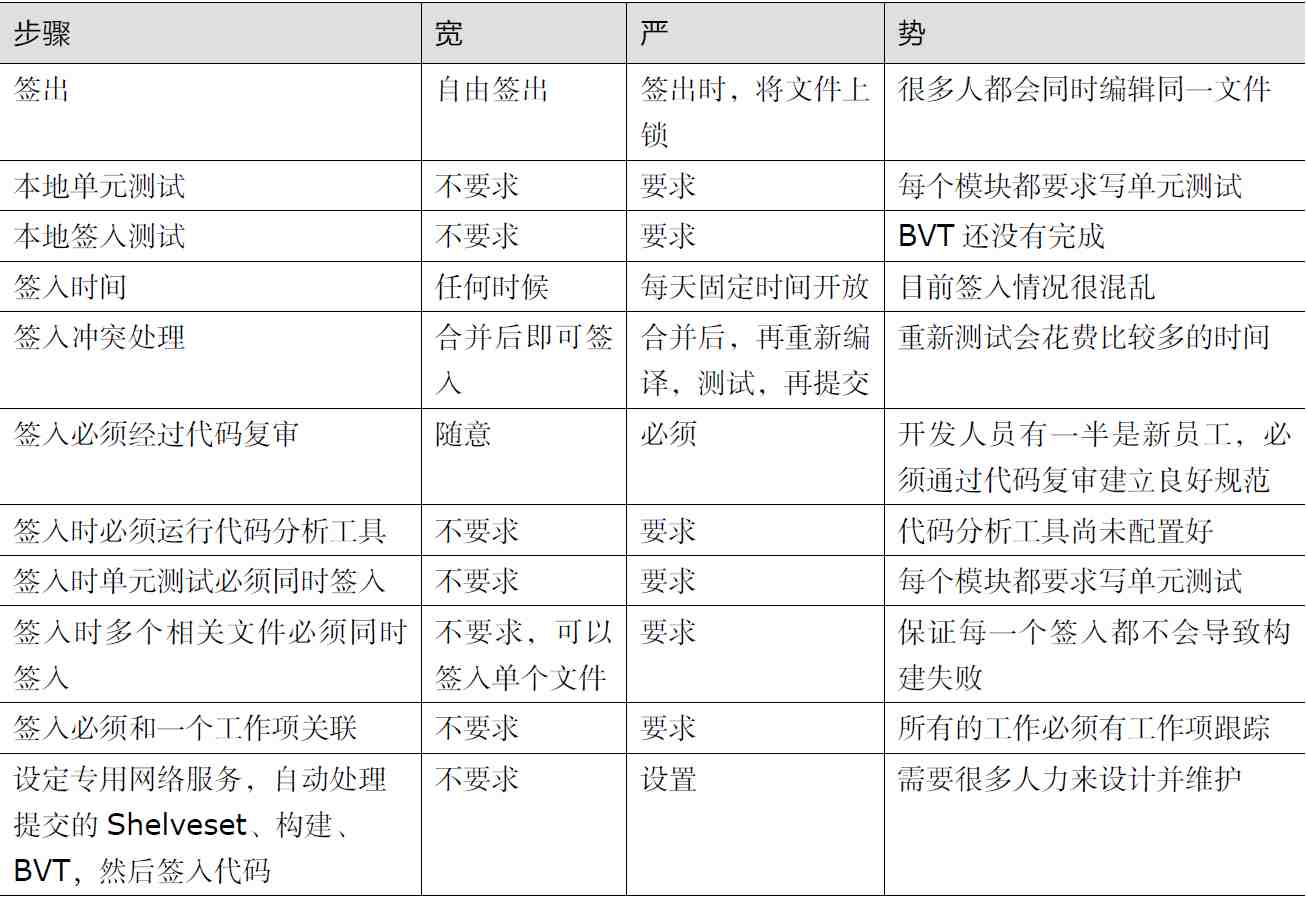
具体开发流程如下:
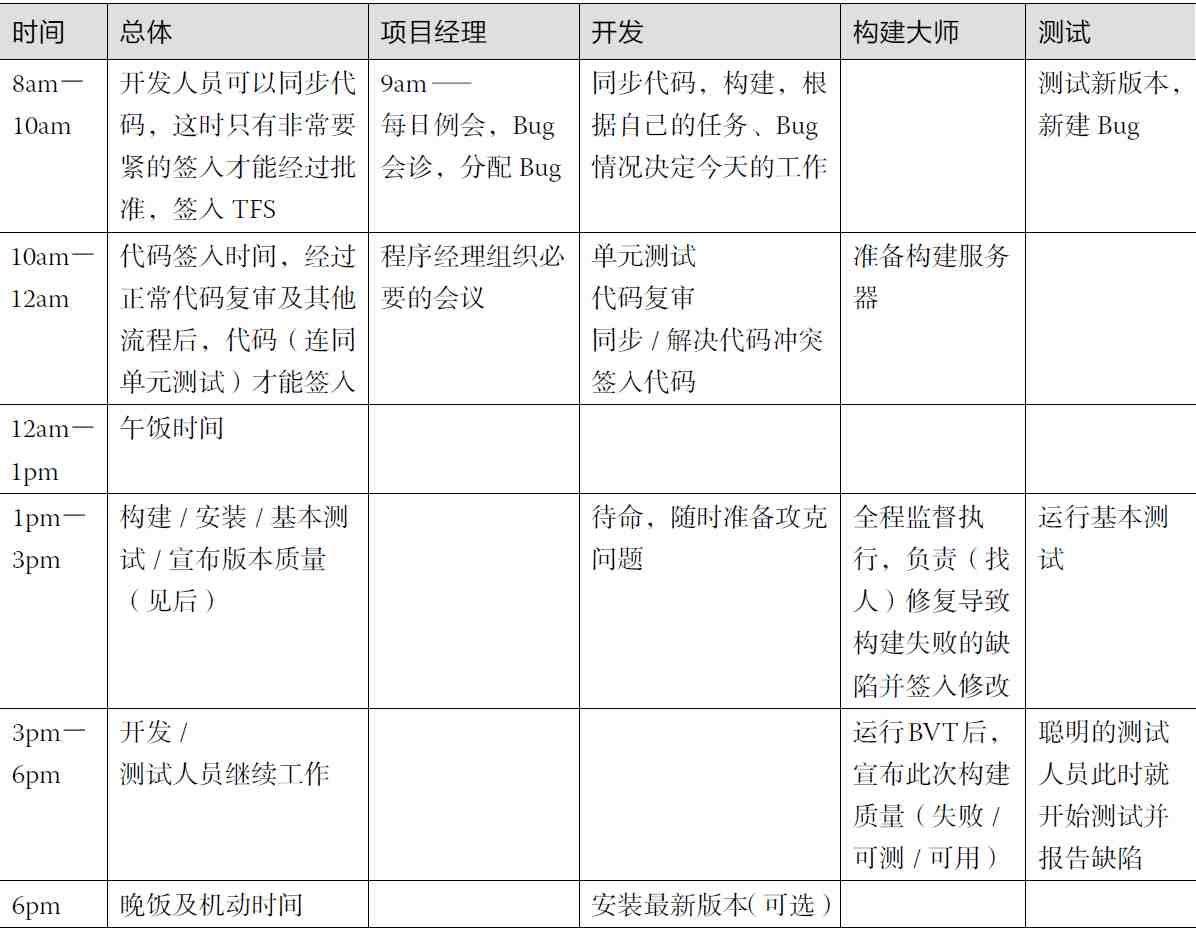
小强地狱(Bug Hell)
随着项目的深入,每个人同时既要开发新的功能,也要修复以前的缺陷。由于没有明确的优先次序,一般人都愿意把时间花在开发新功能上。但是我们的确需要平衡进度和质量。有这样的一种方法:小强地狱(Bug Hell)。
如果开发人员的小强(Bug)数量超过一规定值,则此君被送入“小强地狱”,在地狱中,他唯一能做的就是修复小强,直到小强数量低于此阈值。这一阈值由团队根据实际情况来确定,要注意:开发人员同时“入狱”的人数应在全体成员的5%——30%之间,若比例太高,则要考虑阈值或小强数量的计算方式是否合理(是否只包括某一严重程度以上的Bug)。在项目过程中,阈值不宜频繁调整,最好事先宣布阈值。















 4939
4939

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









